
프로그래머스 SQL 고득점 Kit SUM, MAX, MIN
어제 SQL 고득점 Kit SELCET를 다 풀었다!
오늘부터는 새로운 Kit SUM, MAX, MIN을 풀어볼 것이다!!
이제는 하루에 두 문제 이상 풀 거다 ㅎ
1. 가장 비싼 상품 구하기 Level 1

정답
Level 1 이라서 그런지 이렇다 할 게 없다..
SELECT MAX(PRICE) AS MAX_PRICE
FROM PRODUCT;2. 최댓값 구하기 Level 1
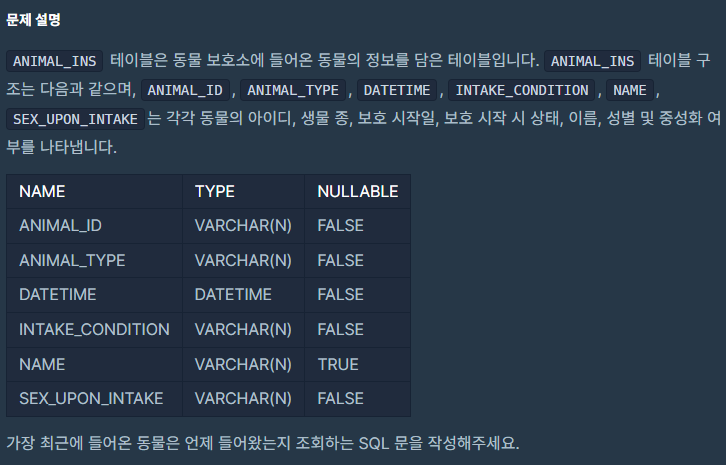
시간은 과거부터 현재까지 오름차순으로 진행되니까,
MIN은 가장 과거,
MAX는 가장 최근이다!
정답
SELECT MAX(DATETIME) AS '시간'
FROM ANIMAL_INS;3. 잡은 물고기 중 가장 큰 물고기의 길이 구하기 Level 1
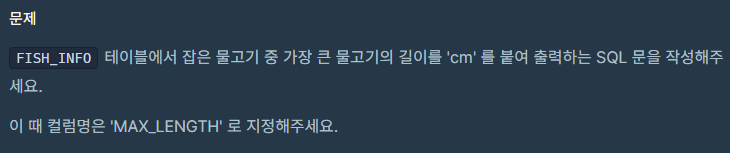
정답
전에 사용한 적 있던 CONCAT을 활용하여 문자열을 결합하면 된다!
CONCAT을 통해 결합할 때,DECIMAL,FLOAT,DOUBLE등의 숫자 타입 데이터는 소수점을 기본적으로 유지한다. 그래서 .00과 같은 값이 붙을 수 있다.
SELECT CONCAT(MAX(LENGTH), 'cm') AS MAX_LENGTH
FROM FISH_INFO;4. 가격이 제일 비싼 식품의 정보 출력하기 Level 2

서브쿼리를 사용하는 거라서 Level 2였다~~
혹시나 SQL 문법을 잘 몰랐다면, WHERE PRICE = MAX(PRICE)라고 입력했을 수도 있다.(나 아님)
그러나 WHERE 절에서는 집계 함수(MAX(), SUM() 등)를 직접 사용할 수 없다!
이럴 때는 서브쿼리(SUBQUERY)를 사용해야 한다.
정답
SELECT
PRODUCT_ID,
PRODUCT_NAME,
PRODUCT_CD,
CATEGORY,
PRICE
FROM
FOOD_PRODUCT
WHERE
PRICE = (
SELECT
MAX(PRICE)
FROM
FOOD_PRODUCT
);서브쿼리(SUBQUERY)
문제가 너무 시시하니까 서브쿼리를 제대로 배워보자!
서브쿼리란 SQL에서 메인 쿼리 내에서 결과를 도출하기 위해 실행되는 작은 쿼리다.
즉, SELECT문 내에 다시 SELECT문을 사용하는 SQL문이다.
이 문제처럼 한 번의 실행으로 원하는 데이터를 얻기 어려울 때 주로 사용한다.
그리고 일반 SELECT문과 동일하게 한 개의 행을 반환할 수도 있고, 여러 개의 행을 반환할 수도 있다.
보통 FROM, SELECT, WHERE, HAVING 절에서 사용한다.
그리고 어떤 절에서 사용되냐에 따라서 이름도 달라진다.
이번에 SQLD를 공부한 김에 SQLD 기준으로 정리를 해보겠다 ㅎ
반환 행에 따른 서브쿼리 종류
반환하는 행의 수에 따라서 분류한다.
| 서브쿼리 유형 | 설명 | 연산자 |
|---|---|---|
| ① 단일 행 서브쿼리 (Single row subquery) | 단 하나의 행만 반환하는 서브쿼리 | 비교 연산자 =, <, <=, >=, <> |
| ② 다중 행 서브쿼리 (Multi row subquery) | 여러 개의 행을 반환하는 서브쿼리 | IN, ANY, ALL, EXISTS |
사용되는 위치에 따른 서브쿼리 종류(SQLD 기준)
사용 위치에 따라서도 분류한다.
| 서브쿼리 유형 | 설명 | 사용 위치 |
|---|---|---|
| ① 스칼라 서브쿼리 (Scalar Subquery) | SELECT절 | SELECT문에 SELECT문을 사용한 것. |
| 한 행이나 한 컬럼을 반환. | ||
| ② 인라인 뷰 (Inline View) | FROM구 | FROM구에 SELECT문을 사용한 것. |
| 단일 행, 다중 행 서브쿼리 모두 가능 | ||
| ③ 서브쿼리 (Subquery) | WHERE구 | WHERE구에 SELECT문을 사용한 것. |
| 단일 행, 다중 행 서브쿼리 모두 가능 |
5. 최솟값 구하기 Level 1
정답
SELECT
MIN(DATETIME) AS '시간'
FROM
ANIMAL_INS;6. 동물 수 구하기 Level 2

정답
SELECT
COUNT(*) AS count
FROM
ANIMAL_INS;7. 중복 제거하기 Level 2

이건 그나마 SELECT 문제집에 비하면 Level 2..? 수준은 아닌 거 같지만,,
그나마 조금은 어려운 문제가 나왔다..
DISTINCT를 사용하면 중복을 제거한다.
그래서 NULL이 아닌 것들만 테이블에서 가져온 뒤에, 중복을 제거한 값들 중에서 COUNT를 하면 된다!
정답
SELECT
COUNT(DISTINCT NAME) AS count
FROM
ANIMAL_INS
WHERE NAME IS NOT NULL;8. 조건에 맞는 아이템들의 가격의 총합 구하기 Level 2

SELECT
SUM(PRICE) AS 'TOTAL_PRICE'
FROM
ITEM_INFO
WHERE
RARITY = 'LEGEND';9. 연도별 대장균 크기의 편차 구하기 Level 2

1. 연도별 가장 큰 대장균 찾기
SELECT
YEAR(DIFFERENTIATION_DATE) AS YEAR,
MAX(SIZE_OF_COLONY) AS MAX_SIZE
FROM
ECOLI_DATA
GROUP BY
YEAR(DIFFERENTIATION_DATE);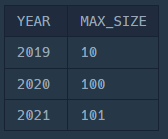
여기까지는 바로 따라올 수 있을 것이다.
2. 원본 테이블과 방금 구한 MAX_SIZE를 JOIN하기
이 부분이 솔직히 많이 어려웠다.
기존의 JOIN은 같은 테이블 내에서 서로 연관된 컬럼을 연결하는 방식이라 직관적으로 이해하기 쉬웠다.
하지만 이 문제에서는 연도별 최대 크기라는 가공된 데이터를 기존 테이블과 JOIN해야 했다.
즉, 원본 테이블에는 존재하지 않는 데이터를 먼저 계산한 후, 그 결과를 기존 테이블과 연결해야 하는 방식이었다.
그러나 이것도 역시 연결하는 것이기 때문에 원본 테이블의 YEAR(DIFFERENTIATION_DATE)과 가공된 서브쿼리의 YEAR를 연결하면 되는 것이었다.
그래서 서브쿼리를 WITH AS 구문으로 만들어서 임시 테이블처럼 선언해서 ON 조건을 통해 JOIN하면 되는 것이었다!
WITH
-- 1. 연도별로 가장 큰 대장균 찾기
MAX_SIZE_PER_YEAR AS (
SELECT
YEAR (DIFFERENTIATION_DATE) AS YEAR,
MAX(SIZE_OF_COLONY) AS MAX_SIZE
FROM
ECOLI_DATA
GROUP BY
YEAR (DIFFERENTIATION_DATE)
)
-- 2. 연도별로 JOIN하기
SELECT
P.YEAR,
P.MAX_SIZE - E.SIZE_OF_COLONY AS YEAR_DEV,
E.ID
FROM
ECOLI_DATA E
JOIN MAX_SIZE_PER_YEAR P ON YEAR (E.DIFFERENTIATION_DATE) = P.YEAR
-- 3. 정렬
ORDER BY
P.YEAR,
YEAR_DEV;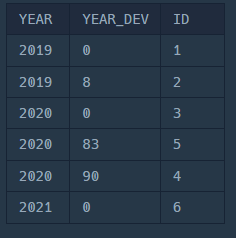
10. 물고기 종류 별 대어 찾기 Level 3

1. 물고기 종류 별로 가장 큰 물고기 찾기
SELECT
FISH_TYPE,
MAX(LENGTH)
FROM
FISH_INFO
GROUP BY
FISH_TYPE;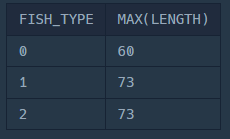
2. FISH_INFO 테이블과 JOIN하여 물고기 이름 가져오기
WITH MAX_FISH AS (
-- 1. 물고기 종류별 최대 LENGTH 찾기
SELECT
FISH_TYPE,
MAX(LENGTH) AS MAX_LENGTH
FROM FISH_INFO
GROUP BY FISH_TYPE
)
SELECT
FI.ID,
FI.FISH_TYPE,
FI.LENGTH
FROM FISH_INFO FI
JOIN MAX_FISH MF
ON FI.FISH_TYPE = MF.FISH_TYPE
AND FI.LENGTH = MF.MAX_LENGTH; -- 2. 최대 LENGTH의 물고기와 JOIN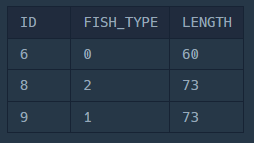
3. FISH_NAME_INFO 테이블과 한 번 더 JOIN해서 물고기 이름 가져오기
이 부분도 JOIN을 한 번 더 하는 것이 처음이긴 했지만, 기존의 JOIN과 똑같이 하면 되는 것이었다!
WITH MAX_FISH AS (
-- 1. 물고기 종류별 최대 LENGTH 찾기
SELECT
FISH_TYPE,
MAX(LENGTH) AS MAX_LENGTH
FROM FISH_INFO
GROUP BY FISH_TYPE
)
SELECT
FI.ID,
FN.FISH_NAME,
FI.LENGTH
FROM FISH_INFO FI
JOIN MAX_FISH MF
ON FI.FISH_TYPE = MF.FISH_TYPE
AND FI.LENGTH = MF.MAX_LENGTH -- 2. LENGTH와 MAX_LENGTH로 JOIN
JOIN FISH_NAME_INFO FN
ON FI.FISH_TYPE = FN.FISH_TYPE -- 2. FISH_TYPE으로 JOIN
ORDER BY FI.ID;이로써 SQL 고득점 Kit의 Kit SUM, MAX, MIN문제집도 끝이다!!
