
백엔드 개발자가 되려면 SQL도 할 줄 알아야지!!
그래서 알고리즘에 이어 SQL 공부도 시작하기로 마음 먹었다!
프로그래머스 SQL 고득점 Kit SELECT
1. 평균 일일 대여 요금 구하기 Level 1
각설하고, 우선 내가 알고 있는 것들로만 먼저 시도해봤다!
1차 시도
-- 코드를 입력하세요
SELECT AVG(DAILY_FEE) AS AVERAGE_FEE
FROM CAR_RENTAL_COMPANY_CAR
WHERE CAR_TYPE = "SUV"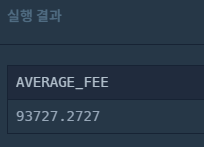
값이 올바른지는 모르겠지만, 일단 소수점 조건을 만족시키지 못 한다..
기억이 잘 안 나니까 구글링을 해보자!
ROUND(반올림)
- 소수점 자리수를 지정할 수 있다
- ROUND(숫자, 반올림할 자릿수): 반올림할 자릿수 + 1 = 자릿수에서 반올림
- 즉, ROUND(123.456, 2)이라고 적으면, 2+1 = 3째 자리에서 반올림 한다는 의미다
그래서, 123.46이 될 것이다.
그렇다면 이 ROUND 함수로 AVG를 감싸주면 된다.
정답
-- 코드를 입력하세요
SELECT ROUND(AVG(DAILY_FEE), 0) AS AVERAGE_FEE
FROM CAR_RENTAL_COMPANY_CAR
WHERE CAR_TYPE = "SUV"정답이다!
반올림할 자릿수가 0 이라서 그냥 반올림할 자릿수를 입력하지 않고도 해봤는데, 정답이었다!
-- 코드를 입력하세요
SELECT ROUND(AVG(DAILY_FEE)) AS AVERAGE_FEE
FROM CAR_RENTAL_COMPANY_CAR
WHERE CAR_TYPE = "SUV"2. 3월에 태어난 여성 회원 목록 출력하기 Level2

1차 시도
-- 코드를 입력하세요
SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_OF_BIRTH
FROM MEMBER_PROFILE
WHERE DATE_OF_BIRTH.YEAR() = 3
ORDER BY ASC그냥 생각나는 대로 한 번 써봤다.
생일은 년, 월, 일이 다 있길래 그냥 .YEAR()로 해봤는데 맞는 거? 같다.
근데 오류가 하나 떴다.

ㅋㅋㅋㅋ... ASC 아니었나..? DESC는 뭔가 기억나는데, ASC는 맞는 거 같기도 하고 , 아닌 거 같기도 하고,,,
아... 문제를 다시 읽어보니 회원ID를 기준으로 정렬하라고 했는데,
무엇을 기준으로 정렬할 지를 안 적어줬다..
2차 시도
-- 코드를 입력하세요
SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_OF_BIRTH
FROM MEMBER_PROFILE
WHERE DATE_OF_BIRTH.YEAR() = 3
ORDER BY MEMBER_ID ASC
.YEAR() 이라는 문법은 없나보다..
그래서 DATE_OF_BIRTH.YEAR 전체를 컬럼이라고 생각해서 찾아봤는데, 해당 컬럼이 없다고 한 거 같다..
3차 시도
.YEAR 이 아니라면, 괄호안에 DATE_OF_BIRTH 컬럼을 넣어보자!
여기까지 해보고 안 되면, 구글링 해보는 걸로~..
-- 코드를 입력하세요
SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_OF_BIRTH
FROM MEMBER_PROFILE
WHERE YEAR(DATE_OF_BIRTH) = 3
ORDER BY MEMBER_ID ASC오..! 에러없이 돌아갔다..!
그런데, 웬 걸 ㅋ
아무것도 안 나왔다..
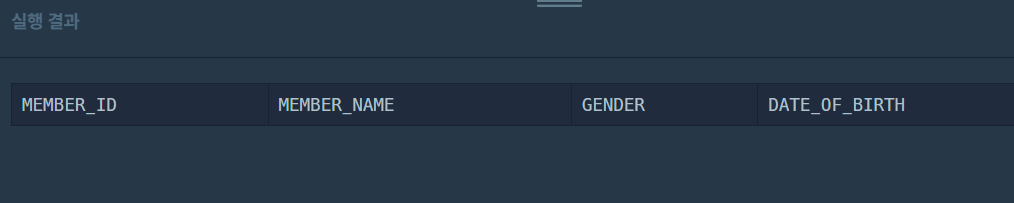
아.. 바보 이런 바보... 3월이라고 했는데, 어찌 YEAR를 생각했지...
4차 시도
MONTH 바꾸고 바로 재시도
-- 코드를 입력하세요
SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_OF_BIRTH
FROM MEMBER_PROFILE
WHERE MONTH(DATE_OF_BIRTH) = 3
ORDER BY MEMBER_ID ASC땡!
문제를 제대로 읽자...

5차 시도
-- 코드를 입력하세요
SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_OF_BIRTH
FROM MEMBER_PROFILE
WHERE MONTH(DATE_OF_BIRTH) = 3 && TLNO IS NOT NULL
ORDER BY MEMBER_ID ASC또 틀렸다...
출력이 이렇게 나오는데, 생일 부분에 시간이 출력돼서 그런 거 같다..

문제 젤 밑에 이런 조건이 있었다..!

음...
6차 시도
-- 코드를 입력하세요
SELECT MEMBER_ID, MEMBER_NAME, GENDER, FORMAT(DATE_OF_BIRTH, "YYYY-MM-DD")
FROM MEMBER_PROFILE
WHERE MONTH(DATE_OF_BIRTH) = 3 && TLNO IS NOT NULL
ORDER BY MEMBER_ID ASC
ㅋㅋㅋㅋㅋㅋ...
그냥 검색해보자 이건..
7차 시도
-- 코드를 입력하세요
SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_FORMAT(DATE_OF_BIRTH, "%Y-%m-%d") AS DATE_OF_BIRTH
FROM MEMBER_PROFILE
WHERE MONTH(DATE_OF_BIRTH) = 3 && TLNO IS NOT NULL
ORDER BY MEMBER_ID ASC
예시 출력과 똑같이 나온다!
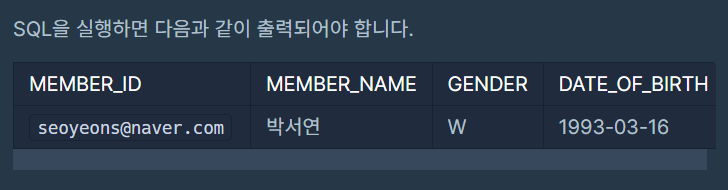
아니 이건 도대체 왜 틀렸을까..?
이젠 gpt에게 물어보자..
아... 문제를 제대로 읽자...
다시 한 번 복명 복창한다.
문제를 제대로 읽자..!!!

정답
어제 알고리즘을 풀고 자서 그런지, AND 대신 && 라고 적었는데 그것도 고쳤다.
-- 코드를 입력하세요
SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_FORMAT(DATE_OF_BIRTH, "%Y-%m-%d") AS DATE_OF_BIRTH
FROM MEMBER_PROFILE
WHERE GENDER = 'W'
AND MONTH(DATE_OF_BIRTH) = 3
AND TLNO IS NOT NULL
ORDER BY MEMBER_ID ASC드디어 정답이다..!
생일 출력 형식은 % 뒤에 대문자냐, 소문자냐에 따라서 달라진다. 궁금하면 직접 해보자!
지금 날짜 형식이 왜 저렇게 됐는지도 알아보자.
문제에서는 DATE_OF_BIRTH를 DATE 타입이라고 적어놨다.
그런데 이것을 출력할 때, 무엇으로 하냐에 따라 다른 거 같은데, 프로그래머스에서는 DATETIME 타입으로 출력을 하나보다.
그래서 출력 형식이 날짜와 시간이 함께 출력돼야 해서 00:00:00이 채워져있던 거다.
방금 막 정처기 필기를 치고 왔다.
시험이 8시 40분이라서 7시에 일어나서 준비하고 8시에 나왔는데 밖에 눈이 많이 와서, 버스도 너무 안 오고, 택시도 안 잡혀서 하마터면 못 치는 줄 알았다..!
지하철타고 내려서, 20분 걸어서 다행히 늦지 않게 도착했다.
그리고 다행히 78점이 나온 걸 확인하고 나왔다 후후..
일단 오늘은 시험도 치고 왔으니, 2주일 내내 봤던 CS 책은 조금 덮어두고,
SQL 문제를 좀 많이 풀어보자!!

3. 흉부외과 또는 일반외과 의사 목록 출력하기 Level 1

1차 시도
-- 코드를 입력하세요
SELECT DR_NAME, DR_ID, MCDP_CD, HIRE_YMD
FROM DOCTOR
WHERE MCDP_CD = (CS || GS)
ORDER BY HIRE_YMD DESC (ORDER BY DR_NAME)흉부외과(CS)이거나 일반외과(GS)인 이거 한 번에 될까해서 저렇게 작성해봤는데, 일단 정렬부터 오류가 발생했다.

- 정렬이 두 개면 어떻게 해야할까..?
ORDER BY절은 한 번만 사용해야 한다.
여러 정렬 기준을 사용하려면 ,(쉼표) 로 구분지을 수 있다!
흉부외과(CS)이거나 일반외과(GS)인
내가 적은||은 결합 연산자로 CS와 GS를 결합한다. 그래서 잘못된 결과가 나올 것이다.
그리고 
이런 오류도 발생했는데, 내가 벨로그 작성하면서 풀다보니 습관적으로 백틱으로 감쌌다. 그래서 CS를 문자로 인식한 게 아니라, 속성으로 인식해버려서 오류가 발생했다.
SQL문에서 문자열은 항상 작은 따옴표로 감싸야 한다!
그렇게 해서 출력해보니, 날짜 형식을 또 DATE로 변환해줘야 했다. 그래서 한 번 작성해봤다.
정답
-- 코드를 입력하세요
SELECT DR_NAME, DR_ID, MCDP_CD, DATE_FORMAT(HIRE_YMD, '%Y-%m-%d') AS HIRE_YMD
FROM DOCTOR
WHERE MCDP_CD IN ('CS', 'GS')
ORDER BY HIRE_YMD DESC, DR_NAME ASC
정답이다!
4. 과일로 만든 아이스크림 고르기 Level 1

JOIN이 나왔다.
두 테이블이 있고, FLAVOR속성으로 연결 돼 있다.
일단은 문제에서 요구하는 대로 각각의 테이블에 대한 쿼리문을 작성해봤다.
SELECT FLAVOR
FROM FIRST_HALF
WHERE TOTAL_ORDER > 3000SELECT FLAVOR
FROM ICECREAM_INFO
WHERE INGREDIENT_TYPE = "fruit_based"이 때, 두 테이블은 FLAVOR 속성으로 연결 돼 있으니까, INNER JOIN을 해야한다.
INNER JOIN을 하는 방법
우선은 나머지 속성도 추가해서 실행 결과를 보면 다음과 같다.
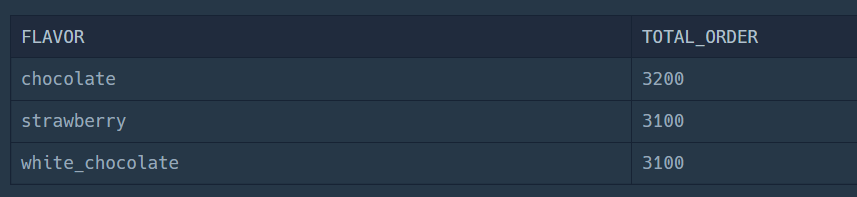
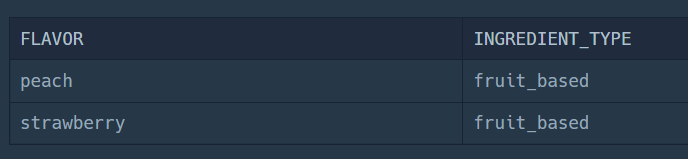
위의 두 쿼리문의 실행 결과를 보면 이렇게 된다.
그리고 우리가 구해야하는 건 이들의 교집합을 FLAVOR 속성을 통해서 구하는 것이다.
기본 INNER JOIN 형식
SELECT *
FROM A
JOIN B
ON A.공통컬럼 = B.공통컬럼이 때 공통컬럼이 조인의 기준이다.
(INNER JOIN의 경우에는 A, B 테이블의 순서를 신경쓰지 않아도 된다)
이걸 이 문제에 대입해보면 이렇게 된다.
SELECT *
FROM FIRST_HALF F
JOIN ICECREAM_INFO I
ON F.FLAVOR = I.FLAVOR일단 이렇게 작성하면 아래와 같은 결과가 나온다.
모든 컬럼을 출력하기 때문에 중복된 값이 있기는 하다.
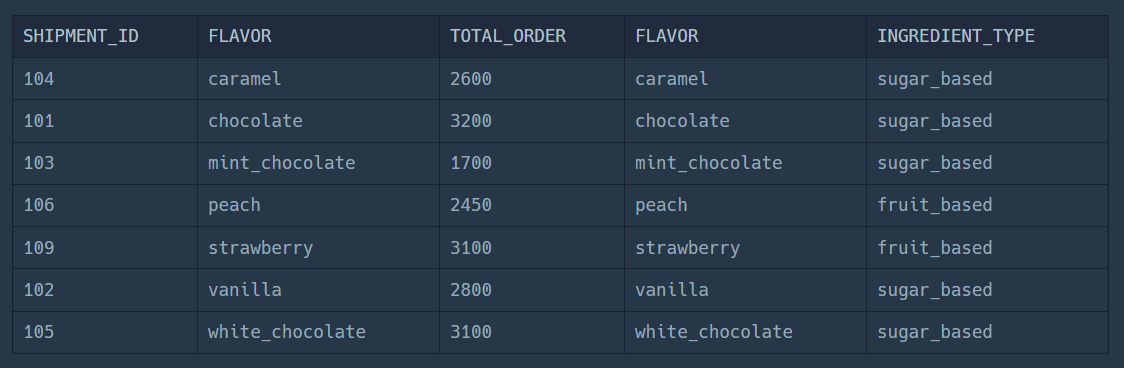
SELECT F.FLAVOR, I.INGREDIENT_TYPE
FROM FIRST_HALF F
JOIN ICECREAM_INFO I
ON F.FLAVOR = I.FLAVOR원하는 컬럼만 출력하도록 별칭.컬럼 형식으로 원하는 테이블의 원하는 컬럼을 적어주면 된다.
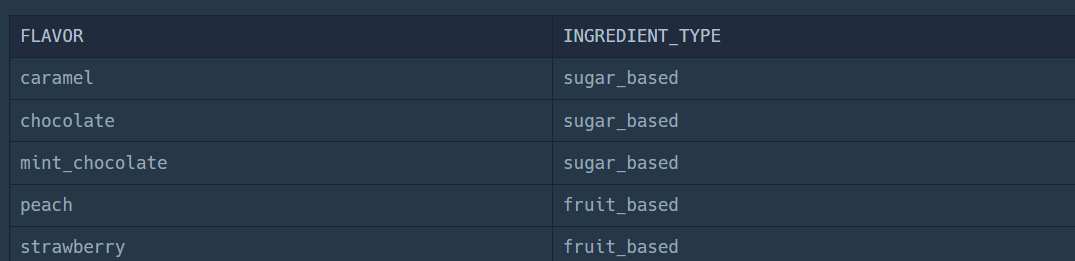
이제 여기에 문제에서 요구한 조건인, 3,000보다 높으면서 아이스크림의 주 성분이 과일인 부분만 WHERE 절에 적어주면 된다.
- 총 주문량은
FIRST_HALF테이블의 컬럼이므로,F.TOTAL_ORDER으로 접근 - 아이스크림의 주 성분은
ICECREAM_INFO테이블의 컬럼이므로,I.INGREDIENT_TYPE으로 접근
조건이 두 개 이므로 AND 연산자로 이어주면 된다.
그러면 다음과 같이 완성할 수 있다!
정답
SELECT F.FLAVOR
FROM FIRST_HALF F
JOIN ICECREAM_INFO I
ON F.FLAVOR = I.FLAVOR
WHERE F.TOTAL_ORDER > 3000
AND I.INGREDIENT_TYPE = 'fruit_based';아 그리고.. 쿼리문이 하나 완료됐다는 의미로 세미 콜론을 마지막에 입력해주어야 한다.
지금은 프로그래머스 환경에서 실행하는 것이기 때문에 상관없는데, 여러 쿼리문을 작성하는 경우는 한 쿼리문의 끝이라는 의미로 작성해야 한다. 그렇기에 그냥 항상 작성하는 것이 낫다!
5. 강원도에 위치한 생산공장 목록 출력하기 Level 1

이번 문제는 주소 부분이 사진처럼 돼 있는데, 그 중에서 강원도를 포함하는 튜플들을 찾는 문제다.
즉, 와일드 카드를 사용할 줄 아는지 물어보는 것이다.

SQLD 공부할 때, % 사용법을 본적이 있어서 그걸 이용해서 바로 작성해봤다.
정답
SELECT FACTORY_ID, FACTORY_NAME, ADDRESS
FROM FOOD_FACTORY
WHERE ADDRESS LIKE '강원도%'
ORDER BY FACTORY_ID;
SQL의 기본 와일드 카드
%: 0개 이상의 문자와 일치
'강원도%':강원도로 시작하는 값 검색'%강원도%':강원도가 포함된 값 검색
_: 1개의 문자와 일치
'__패턴':문자패턴처럼패턴으로 끝나는 총 네 글자의 값 검색_코%:초코우유와 같은 값 검색
6. 인기있는 아이스크림 Level 1

어려울 게 하나도 없는 완전 기본 문제였다!
정답
SELECT FLAVOR
FROM FIRST_HALF
ORDER BY TOTAL_ORDER DESC, SHIPMENT_ID;7. 2세 이하인 여자 환자 목록 출력하기 Level 1

1차 시도
그냥 아는 대로 다 적었다.
SELECT PT_NAME, GEND_CD, AGE, TLNO
FROM PATIENT
WHERE AGE <= 12
ORDER BY AGE DESC, PT_NAME;- 여자인 환자라고 했는데, 빼먹었다
전화번호가 없는 경우, 'NONE'으로 출력이건 배운 적 없다..
COALESCE
COALESCE는 SQL 표준 함수로, 여러 개의 인자 중에서NULL이 아닌 첫 번째 값을 반환한다.
즉,NULL값을 다른 값으로 대체할 때 가장 범용적으로 사용된다.
기본 문법:
COALESCE(값1, 값2, 값3, ...)1. 테이블에서 NULL 처리하기
SELECT
PT_NAME,
COALESCE(TLNO, 'NONE') AS TLNO -- 전화번호가 NULL이면 'NONE' 출력
FROM PATIENT;2. 여러 개의 값 중 NULL이 아닌 값 반환
SELECT COALESCE(NULL, NULL, '첫 번째 NULL이 아닌 값', '두 번째 NULL이 아닌 값') AS RESULT;3. 여러 개의 열 중 NULL이 아닌 값 선택하기
SELECT
COALESCE(EMAIL, PHONE, ADDRESS, '연락처 없음') AS CONTACT_INFO
FROM USERS;정답
SELECT PT_NAME, PT_NO, GEND_CD, AGE, COALESCE(TLNO, 'NONE') AS TLNO
FROM PATIENT
WHERE AGE <= 12 AND GEND_CD = 'W'
ORDER BY AGE DESC, PT_NAME;
8. 조건에 맞는 도서 리스트 출력하기 Level 1
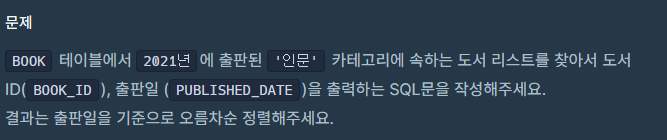
정답
다 아는 것들이라서 한 번에 풀 수 있었다.
특히 DATE_FORMAT은 3일 전에 풀어봤던 3월에 태어난 여성 회원 목록 출력하기 문제에서 배웠던 거라서 쉬웠다.
SELECT BOOK_ID, DATE_FORMAT(PUBLISHED_DATE, '%Y-%m-%d') AS PUBLISHED_DATE
FROM BOOK
WHERE YEAR(PUBLISHED_DATE) = 2021 AND CATEGORY = '인문'
ORDER BY PUBLISHED_DATE;9. 조건에 부합하는 중고거래 댓글 조회하기 Level 1

1차 시도
INNER JOIN은 저번에 배웠기에 쉽게 사용할 수 있었다.
2022년 10월에이 부분은 년과 월이 둘다 있어서 어떻게 해야할지 조금 고민됐는데, 그냥 AND연산자로 한 번 더 적어주었더니 오류없이 잘 돌아갔다.
SELECT B.TITLE, B.BOARD_ID, R.REPLY_ID, R.WRITER_ID, R.CONTENTS,
DATE_FORMAT(B.CREATED_DATE, '%Y-%m-%d') AS CREATED_DATE
FROM USED_GOODS_BOARD B
JOIN USED_GOODS_REPLY R
ON B.BOARD_ID = R.BOARD_ID
WHERE YEAR(B.CREATED_DATE) = 2022 AND MONTH(B.CREATED_DATE) = 10
ORDER BY B.CREATED_DATE, B.TITLE;정답
문제를 다시 읽어보니, 출력하는 내용은 게시글이 아닌 댓글 작성일이었고, 정렬 기준도 댓글 작성일기준이었다..
문제를 제대로 읽자..!
SELECT B.TITLE, B.BOARD_ID, R.REPLY_ID, R.WRITER_ID, R.CONTENTS,
DATE_FORMAT(R.CREATED_DATE, '%Y-%m-%d') AS CREATED_DATE
FROM USED_GOODS_BOARD B
JOIN USED_GOODS_REPLY R
ON B.BOARD_ID = R.BOARD_ID
WHERE YEAR(B.CREATED_DATE) = 2022 AND MONTH(B.CREATED_DATE) = 10
ORDER BY R.CREATED_DATE, B.TITLE;10. 재구매가 일어난 상품과 회원 리스트 구하기 Level 2

1차 시도
중복된 데이터를 찾으라는 건데, 중복 제거는 DISCTINCT라고 알고 있는데, 중복된 값을 찾는 건 어떻게 해야할까..
일단은 COUNT가 그나마 생각이 나서 작성해봤다.
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
WHERE COUNT(USER_ID) >= 2
ORDER BY USER_ID, PRODUCT_ID DESC;
이렇게 쓰는 것이 아니란다..
음 생각해보면 예전에 이런 집계 함수는 그룹화할 때만 사용가능하다 했던 거 같기도 하고..
또 그룹화를 할 때는 WHERE를 사용하는 것이 아니라, HAVING을 사용해야만 했던 거 같다.
이 참에 책을 뒤져서 공부하고 넘어가자!
GROUP BY란?
특정 컬럼을 기준으로 데이터를 그룹화(group)해서, 각 그룹에 대해 집계 작업(합계, 평균 등)을 할 수 있게 해주는 SQL 명령어
이 문제 같은 경우에 기본적인 그룹화를 해서 이해해보자!
COUNT 사용 예시
SELECT USER_ID, COUNT(PRODUCT_ID)
FROM ONLINE_SALE
GROUP BY USER_ID;위와 같은 SQL문을 실행하면 어떻게 될까?
위 SQL문의 의미는 USER_ID별로 그룹화를 진행하고, 그 때 USER_ID와 USER_ID로 그룹화한 PRODUCT_ID의 개수를 함께 출력한다.
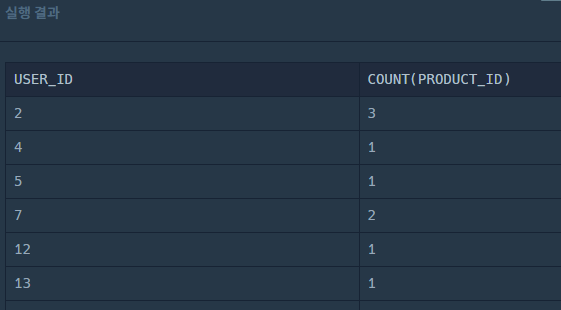
그래서 보면 USER_ID가 2인 회원은 총 3번의 구매를 한 것을 알 수 있다.
자주 사용되는 집계 함수
COUNT(): 그룹에 속한 행의 수SUM(): 그룹에 속한 값들의 합AVG(): 그룹에 속한 값들의 평균MAX(): 그룹에 속한 값들 중 최소값MIN(): 그룹에 속한 값들 중 최대값
주의할 점
GROUP BY를 사용하면, SELECT에 나온 컬럼들은 모두 GROUP BY 절에 포함되거나 집계 함수에 포함되어야 한다.
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
GROUP BY USER_ID;즉, 이렇게 사용하면 안 된다.
앞서 보여준 예시는 GROUP BY에 사용되지 않은 PRODUCT_ID를 집계 함수 COUNT로 감싸서 문제가 없었지만,
이번에는 감싸지 않았기에 오류가 발생할 수 있다.
물론 일부 DBMS에서는 허용되기도 하지만, 이상한 결과가 나올 수 있고 그렇게 하는 것은 표준에 맞지 않는 동작이다.
HAVING 절
일반 SQL문을 사용할 때와 다르게 GROUP BY를 사용해서 데이터를 그룹화한 후 그 그룹에 대해 조건을 걸고 싶으면 HAVING절을 사용한다.
즉, WHERE절은 개별 행에 조건을 걸 때 사용하고, HAVING절은 그룹화된 데이터에 조건을 걸 때 사용한다.
(그리고 GROUP BY절 다음, ODERR BY절 앞에 사용한다.)
예를 들어서 회원별로 상품 ID가 20 이상인 상품 구매 내역만 보고 싶다면 이렇게 작성할 수 있다.
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
HAVING PRODUCT_ID >= 20;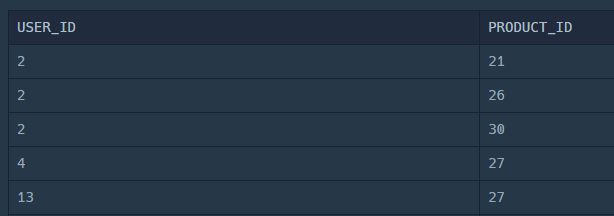
그럼 이제 다시 문제를 풀어보자!
일단은 표시해야할 값부터 적어보자.
회원이 재구매한 데이터니까, 회원별로 출력하되 상품 ID도 같이 출력해야한다.
따라서 SELECT 절에는 USER_ID와 PRODUCT_ID가 있어야 한다.
그렇다면 일단 회원 ID로 그룹화를 해야하는데, 반면에 상품 ID는 그대로 출력하기를 요구하고 있다.
그렇다면 SELECT 절에서 집계 함수로 감싸지 않는 대신 GROUP BY절에 같이 적어주면 될 거 같다!
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID;여기까지 해보면 출력이 이렇게 나온다!
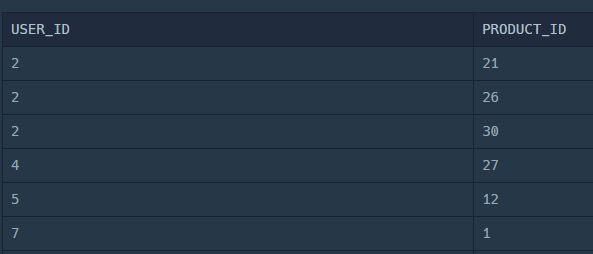
정렬은 그냥 기존에 하던 대로 적는 대신 HAVING 절 뒤에 적으면 될 거 같고,
재구매한 데이터인 것은 어떻게 출력할까?
아까 배운 집계 함수 COUNT를 사용하면 된다.
상품을 재구매한 경우를 따지는 것이니까, COUNT 값이 2이상인 값을 출력하면 된다.
그래서 코드는 최종적으로 이렇게 된다.
정답
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
HAVING COUNT(PRODUCT_ID) >= 2
ORDER BY USER_ID, PRODUCT_ID DESC;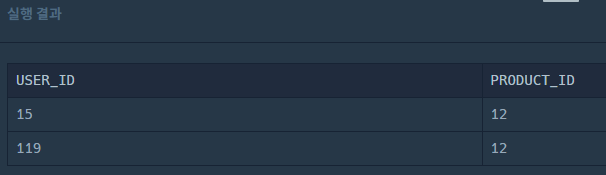
잘 출력한 것이 맞는지 확인하기 위해서 이렇게도 작성해봤다.
같은 회원이 같은 상품을 재구매해서 정답에서 그런 출력이 나왔던 것이다!
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
WHERE USER_ID = 15;
11. 모든 레코드 조회하기 Level 1

난이도가 뒤죽박죽인 거 같다.
정답
SELECT ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, SEX_UPON_INTAKE
FROM ANIMAL_INS
ORDER BY ANIMAL_ID;12. 역순 정렬하기 Level 1

정답
SELECT NAME,DATETIME
FROM ANIMAL_INS
ORDER BY ANIMAL_ID DESC;13. 아픈 동물 찾기 Level 1

정답
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE INTAKE_CONDITION = 'Sick'
ORDER BY ANIMAL_ID;14. 어린 동물 찾기 Level 1


1차 시도
Level 1 중에서 간만에 틀렸다..
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE NAME IN ('Diablo', 'Miller', 'Cherokee')
ORDER BY ANIMAL_ID;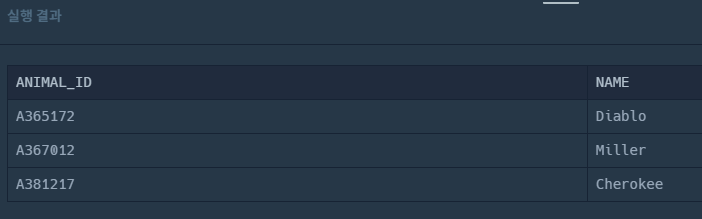
실행 결과는 문제에서 요구하는 것과 똑같은데, 왜 틀렸을까
정답
문제에서 젊은 동물이라고 했는데, 그게 출력 예시처럼 이름을 그대로 찾으라는 게 아니라

이 부분을 말하는 거였다.
문제를 제대로 읽자 -_-...
상식적으로 생각해봐도 이름으로 젊은 동물을 찾는 건 말이 안 되긴 했다..
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE INTAKE_CONDITION != 'Aged'
ORDER BY ANIMAL_ID;15. 동물의 아이디와 이름 Level 1

이제 Level 1은 너무 쉽다!
정답
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
ORDER BY ANIMAL_ID;16. 여러 기준으로 정렬하기 Level 1

정답
SELECT ANIMAL_ID, NAME, DATETIME
FROM ANIMAL_INS
ORDER BY NAME, DATETIME DESC;17. 상위 n개 레코드 Level 1

정답
SELECT NAME
FROM ANIMAL_INS
ORDER BY DATETIME
LIMIT 1;이걸로 통과하긴 했는데, 혹시나 해서 GPT에게 물어봤다.
위와 같은 LIMIT는 MySQL, PostgreSQL, SQLite에서 사용 가능하고,
범용적으로 사용 가능한 ANSI SQL 표준 기반으로는 아래와 같이 작성해야한다.
SELECT NAME
FROM ANIMAL_INS
WHERE DATETIME = (SELECT MIN(DATETIME) FROM ANIMAL_INS);작성과정은 이렇게 된다.
SELECT MIN(DATETIME)
FROM ANIMAL_INS;먼저 이렇게 날짜의 최소값을 찾는 SELECT 문을 작성한다.
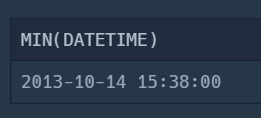
그러면 이런 결과가 나오고,
이 DATETIME과 일치하는 튜플의 이름을 출력하도록 SELECT문을 다시 한 번 더 작성하고,
기존의 SELECT문을 WHERE절에 넣는다.
그러면 가장 오래된 날짜의 이름만 정확히 한 개 출력된다!
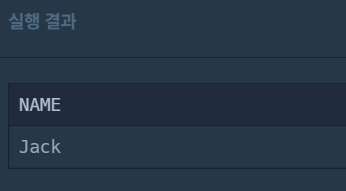
근데 또 N개 출력할 때는 LIMIT를 써야한다..
ANSI SQL대로 하니까 MySQL에서는 동작하지 않는다..
그냥 나중에 코테칠 때, DBMS뭔지 보고 상황에 맞게 추가적인 문법 공부를 하자..ㅠ

18. 조건에 맞는 회원수 구하기 Level 1

정답
SELECT COUNT(USER_ID)
FROM USER_INFO
WHERE YEAR(JOINED) = 2021 AND AGE >= 20 AND AGE <= 29;19. Python 개발자 찾기 Level 1
보면 SKILL 필드가 여러 개 있다.
전에는 특정 필드 하나에 속하는 여러 가지 값들을 출력하려면,
필드 IN (값1, 값2, 값3, ...) 이런 식으로 작성했었다.
근데 이번에는 상황이 반대다.
값 IN (필드1, 필드2, 필드3)인데, 될지 안 될지 몰랐지만 우선 해봤다.
근데 정답이었다!
정답
SELECT ID, EMAIL, FIRST_NAME, LAST_NAME
FROM DEVELOPER_INFOS
WHERE 'Python' IN (SKILL_1, SKILL_2, SKILL_3)
ORDER BY ID;20. 잔챙이 잡은 수 구하기 Level 1

1차 시도
쉽다 생각했는데, 틀렸다..
결과가 아무것도 조회가 안 된다..
SELECT COUNT(*) AS FISH_COUNT
FROM FISH_INFO
WHERE LENGTH = NULL;생각해보니 SQL에서 NULL값은 직접 비교가 안 된다..!
NULL은 알 수 없는 값이기 때문에 = NULL이 아니라 IS NULL을 사용해야 한다!!
정답
SELECT COUNT(*) AS FISH_COUNT
FROM FISH_INFO
WHERE LENGTH IS NULL;21. 가장 큰 물고기 10마리 구하기 Level 1
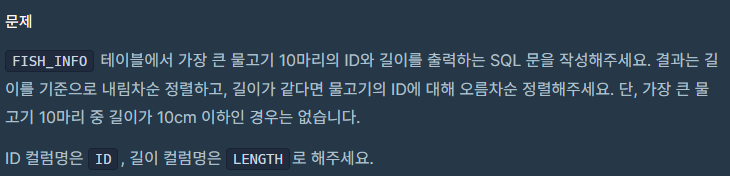
어제 사용했던 LIMIT을 활용하면 바로 풀리는 간단한 문제였다.
정답
SELECT ID, LENGTH
FROM FISH_INFO
ORDER BY LENGTH DESC, ID
LIMIT 10;22. 특정 형질을 가지는 대장균 찾기 Level 1


갑자기 2진수가 등장해서 조금 당황스러웠다..
SELECT COUNT(ID) AS COUNT
FROM ECOLI_DATA
-- WHERE GENOTYPE IN ('1101', '0101', '1100', '0100', '1001', '0001');
WHERE GENOTYPE IN (13, 5, 12, 4, 9, 1);이런 식으로 하드코딩하듯이 해야하나했지만, 저게 몇까지 있는지 알 수가 없어서 일일이 하드코딩하는 건 거의 불가능하기도 하고 문제에서 의도하는 바가 아니다..!
이럴 때는 비트 연산자를 사용해야한다.
1. 2번 형질은 없어야 한다 -> 2와 AND 연산을 했을 때, 0이 돼야 한다.
- 2는 2진수로 000010(예를 들어 6비트일 경우)이고, 다른 비트는 몇이든 0이 나오고, 2번 째 자리가 0일 때 결과값이 0이 된다.2. 1번이나 3번 형질을 있어야 한다 -> 5와 AND 연산을 했을 때, 5 또는 4또는 1이 돼야 한다. 즉, 양수여야 한다.
- 5는 2진수로 000101이라서, 1번째와 3번째 자리중에 하나 이상이 1이어야 한다.그래서 조건 부분을
WHERE (GENOTYPE & 2) = 0
AND (GENOTYPE & 5) > 0;이렇게 작성할 수 있다.
정답
SELECT COUNT(ID) AS COUNT
FROM ECOLI_DATA
WHERE (GENOTYPE & 2) = 0
AND (GENOTYPE & 5) > 0;이로써 Level 1은 모두 다 풀었다..!
이제 Level 2를 풀어보자!!
23. 업그레이드 된 아이템 구하기 Level 2

Level 2로 오니까 역시나 테이블이 두 개 등장했다.
이건 JOIN을 써야할까?
결과로 출력하는 정보는 한 테이블에 다 있으니까, 굳이 JOIN을 사용하지 않아도 된다.
그 대신 서브쿼리를 사용하면 된다.
다만, 한 번에 생각하려고 하지 않고, 한 가지 과정씩 생각하면서 작성하고 조립하면 된다.
정답(서브쿼리만으로)
1. ITEM_INFO 테이블에서 아이템 희귀도가 RARE인 아이템을을 찾는다.
SELECT ITEM_ID
FROM ITEM_INFO
WHERE RARITY = 'RARE'2. (서브쿼리)해당 아이템의 다음 아이템을 찾는다.
SELECT ITEM_ID
FROM ITEM_TREE
WHERE PARENT_ITEM_ID IN (
SELECT ITEM_ID
FROM ITEM_INFO
WHERE RARITY = 'RARE'
)3. 출력할 필드를 적고, 정렬한다.
SELECT ITEM_ID, ITEM_NAME, RARITY
FROM ITEM_INFO
WHERE ITEM_ID IN (
SELECT ITEM_ID
FROM ITEM_TREE
WHERE PARENT_ITEM_ID IN (
SELECT ITEM_ID
FROM ITEM_INFO
WHERE RARITY = 'RARE'
)
)
ORDER BY ITEM_ID DESC;ps.. G선생이 JOIN을 쓰면 관계가 명확해서 더 보기 좋단다..!
그러니 JOIN으로 다시 한 번 풀어보자..
정답(JOIN)
1. ITEM_INFO 테이블에서 아이템 희귀도가 RARE인 아이템을 찾는다.
SELECT ITEM_ID
FROM ITEM_INFO
WHERE RARITY = 'RARE';2. ITEM_TREE 테이블에서 해당 아이템들의 업그레이드 아이템을 찾는다.
- 업그레이드 아이템이는 자식 아이템이니까, `ITEM_ID` 이다.SELECT ITEM_ID
FROM ITEM_TREE
WHERE PARENT_ITEM_ID IN (
SELECT ITEM_ID
FROM ITEM_INFO
WHERE RARITY = 'RARE'
)3. JOIN으로 해당 아이템들의 정보를 출력한다.
현재 바깥의 SELECT 문은 ITEM_TREE의 테이블을 참조하고 있다.
여기에는 문제에서 요구하는 필드가 없기에 이제 JOIN이 필요한 것이다.
SELECT I.ITEM_ID, I.ITEM_NAME, I.RARITY
FROM ITEM_TREE T
JOIN ITEM_INFO I
ON T.ITEM_ID = I.ITEM_ID
WHERE T.PARENT_ITEM_ID IN (
SELECT ITEM_ID
FROM ITEM_INFO
WHERE RARITY = 'RARE'
);4. 정렬한다.
SELECT I.ITEM_ID, I.ITEM_NAME, I.RARITY
FROM ITEM_TREE T
JOIN ITEM_INFO I
ON T.ITEM_ID = I.ITEM_ID
WHERE T.PARENT_ITEM_ID IN (
SELECT ITEM_ID
FROM ITEM_INFO
WHERE RARITY = 'RARE'
)
ORDER BY ITEM_ID DESC;24. 조건에 맞는 개발자 찾기 Level 2
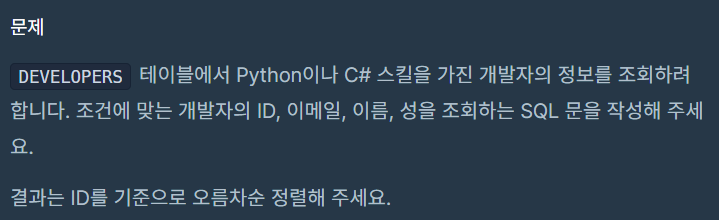
어제 풀어봤던 22번 문제와 비슷하게 비트 연산을 통해서 푸는 거 같아서 쉽게 작성했다.
SELECT ID, EMAIL, FIRST_NAME, LAST_NAME
FROM DEVELOPERS
WHERE (SKILL_CODE & 1280) > 0
ORDER BY ID;근데 틀렸단다..
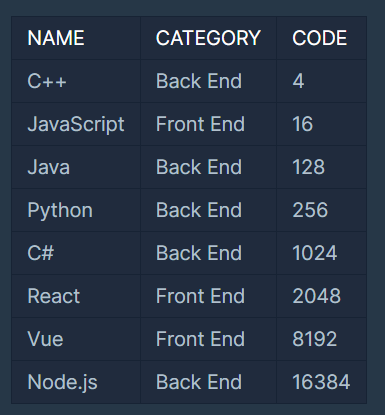
분명 문제의 SKILLCODE 테이블에서 Python과 C#이 256과 1024니까 둘의 합인 1280과 비트연산하면 맞을 줄 알았는데.. 왜 틀렸을까..?
그건 바로.. 위 테이블은 예시였으니까..
그래서 Python과 C#이라는 NAME필드의 값으로 코드를 찾아야 한다..
그러고 나서 두 값을 합해서 비트 연산을 하면 정답이다.
정답
솔직히 좀.. 낚인 기분이 든다..
SELECT ID,
EMAIL,
FIRST_NAME,
LAST_NAME
FROM DEVELOPERS
WHERE (
SKILL_CODE & (
SELECT SUM(CODE)
FROM SKILLCODES
WHERE NAME IN ('Python', 'C#')
)
) > 0
ORDER BY ID;25. 특정 물고기를 잡은 총 수 구하기 Level 2
서브쿼리를 사용하고, 집계함수 COUNT를 사용하면 풀 수 있는 Level 2 치고는 상당히 쉬운 문제였다.
정답
SELECT COUNT(ID) AS FISH_COUNT
FROM FISH_INFO
WHERE FISH_TYPE IN (
SELECT FISH_TYPE
FROM FISH_NAME_INFO
WHERE FISH_NAME IN ('BASS', 'SNAPPER')
);26. 부모의 형질을 모두 가지는 대장균 찾기 Level 2

말이 조금 어려워서 그런지 이해하는 데 조금 시간이 걸렸다.
1. 부모 대장균의 형질을 찾는다.
먼저 WHERE 절을 통해서만 연결하면 아래처럼 할 수 있다.
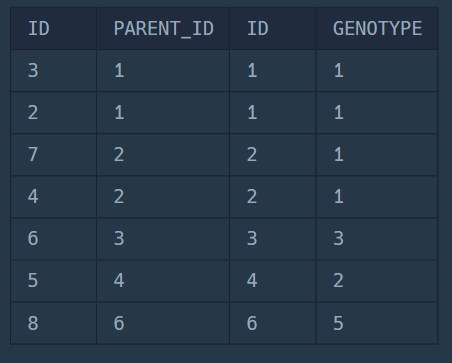
SELECT C.ID,
C.PARENT_ID,
P.ID, P.GENOTYPE
FROM ECOLI_DATA C
JOIN ECOLI_DATA P
WHERE P.ID = C.PARENT_ID;아래의 결과를 보면 조금 더 이해가 될 것이다.
이걸 이제 WHERE 절 부분을 ON 절로 바꿔주기만 하면 된다.
SELECT C.ID,
C.PARENT_ID,
P.ID,
P.GENOTYPE
FROM ECOLI_DATA C
JOIN ECOLI_DATA P
ON C.PARENT_ID = P.ID;본인의 부모 ID에 해당하는 형질을 잘 조회하고 있다.
2. 부모 형질을 잘 조회했으니, 해당 부모 형질을 모두 포함하는 자식 형질을 조회하면 된다.

이 문제도 이전 문제와 마찬가지로 이진수로 형질의 정보를 표시한다.
&(AND 비트 연산자)를 사용한 값은 교집합 결과를 나타낸다.
따라서 부모 형질과 자식 형질을 서로 교집합 연산을 수행하면 서로 어떤 형질들을 공통으로 갖고 있는지 알 수 있다.
그런 다음에 그 결과가 부모 형질과 동일하다면, 자식 형질은 부모 형질을 모두 포함하는 것이 된다.
식으로 적어보자면 이렇게 된다
WHERE P.GENOTYPE = (C.GENOTYPE & P.GENOTYPE)
그러면 이제 문제에서 요구하는 필드만 출력하고, 정렬 조건도 추가해주면 정답이 된다.
정답
SELECT C.ID,
C.GENOTYPE,
P.GENOTYPE AS PARENT_GENOTYPE
FROM ECOLI_DATA C
JOIN ECOLI_DATA P ON C.PARENT_ID = P.ID
WHERE P.GENOTYPE = (P.GENOTYPE & C.GENOTYPE)
ORDER BY C.ID;27. 대장균들의 자식의 수 구하기 Level 3
테이블은 하나 있는데, 그 안에 필드들을 이용해서 집계를 해야 한다.
이럴 때는 JOIN, GROUP BY 둘 중 어떤 것을 써야 할까?
정답은 둘 다 써야 한다.
1. JOIN
공통된 필드끼리 연결해야 하기 때문에 JOIN을 해야 한다.
같은 테이블이 두 개 있다고 생각해 보자.
왼쪽 테이블을 부모 테이블로 사용하고, 오른쪽 테이블을 자식 테이블로 사용하자.
이때 왼쪽 부모 테이블의 ID와 오른쪽 자식 테이블의 PARENT_ID 필드를 서로 일치하게 JOIN을 하면 된다.

SELECT
P.ID,
C.PARENT_ID
FROM ECOLI_DATA P
JOIN ECOLI_DATA C
ON P.ID = C.PARENT_ID
ORDER BY P.ID;그러면 아래와 같은 결과가 나온다.

2. LEFT JOIN
자식 개체가 없는 대장균도 표시해야 되기 때문에 LEFT JOIN을 해야 한다.
일반적인 JOIN은 두 테이블 간에 공통되는 내용만 표시한다.
그런데 우리는 자식 개체가 없는 대장균도 표시를 해야 하기 때문에 부모 테이블의 필드들은 모두 누락 없이 표시해야 한다. 그렇기 때문에 LEFT JOIN을 사용해야 한다.
이전 코드에서 LEFT JOIN으로 바꿔주면 아래와 같이 결과가 바뀐다.
보면 모든 부모 테이블의 필드가 누락 없이 표시되는 것을 볼 수 있다.
A LEFT JOIN B: A(왼쪽 테이블)의 모든 행을 유지하면서, B(오른쪽 테이블)과 매칭되는 값이 있으면 가져오고, 없으면 NULL
A RIGHT JOIN B: B(오른쪽 테이블)의 모든 행을 유지하면서, A(왼쪽 테이블)과 매칭되는 값이 있으면 가져오고, 없으면 NULL
3. GROUP BY
자식 개체가 몇이나 있는지 집계를 해야 하기에 GROUP BY를 사용해야 한다.
그냥 특정 조건의 필드를 세는 것이라면 COUNT로 간단하게 사용하면 되지만, 여기서는 같은 PARENT_ID 값을 가진 행들을 COUNT해야 하기 때문에 GROUP BY와 함께 사용해야 한다.
당연히 부모 ID를 기준으로 집계를 할 것이기 때문에 GROUP BY 절에는 P.ID를 적어야 한다.
그래서 최종적으로 코드를 작성해 보면 이렇게 된다!
SELECT
P.ID,
COUNT(C.PARENT_ID) AS CHILD_COUNT
FROM ECOLI_DATA P
LEFT JOIN ECOLI_DATA C
ON P.ID = C.PARENT_ID
GROUP BY P.ID
ORDER BY P.ID;28. 대장균의 크기에 따라 분류하기 1 Level 3

CASE 문: CASE WHEN THEN END
이 문제는 CASE문을 아냐 모르냐 묻는 문제이다.
코딩을 조금이라도 해봤다면 IF 문을 접해봤을 것이고, SQL의 CASE 문도 비슷한 방식으로 동작한다.
기본적인 문법은 이렇다.
CASE
WHEN 조건1 THEN 결과1
WHEN 조건2 THEN 결과2
...
ELSE 결과
ENDCASE문은 출력할 필드를 결정하는 연산이라서,SELECT문에서 출력할 필드의 한 값으로서 사용한다.- CASE와END를 통해서 열고 닫는다.
- WHEN 뒤에는 조건을, THEN에는 해당 조건이 참일 때 반환할 결과값을 적는다.
- 아무 조건에도 해당하지 않는 경우에는 ELSE를 사용한다.
-ELSE는 필수가 아니라서 생략도 가능하다!
그래서 이 문제는 기본적인 문법만 지켜서 적용하면 바로 정답이다!
SELECT ID,
CASE
WHEN SIZE_OF_COLONY <= 100 THEN 'LOW'
WHEN SIZE_OF_COLONY <= 1000 THEN 'MEDIUM'
ELSE 'HIGH'
END AS SIZE
FROM ECOLI_DATA
ORDER BY ID;29. 대장균의 크기에 따라 분류하기 Level 3

이전 28번 문제에서 CASE WHEN THEN (ELSE) END를 배웠고, 이번에는 거기에 더해 NTILE까지 활용해서 푸는 문제다.
NTILE
NTILE(n) 함수는 데이터를 n 개의 그룹으로 균등하게 나누는 함수다.
그리고 그 그룹마다 번호를 지정해서 호출할 수 있다.
NTILE(n) OVER (ORDER BY 컬럼명 (DESC))- n 개의 그룹으로 나누어진다.
- 특정 컬럼을 기준으로 오름차순이나 내림차순으로 정렬
문제에서는 4가지 등급으로 분류했고, 그 기준점이 25% 50% 75%이기 때문에 n에 4를 넣으면 된다.
그리고 SIZE_OF_COLONY를 기준으로 오름차순 정렬을 하면 1이 LOW가 되고, 내림차순 정렬을 하면 1이 HIGH가 된다.
둘중에 편한 걸로 하면 된다.
SELECT ID,
CASE
WHEN NTILE(4) OVER (ORDER BY SIZE_OF_COLONY DESC) = 1 THEN 'CRITICAL'
WHEN NTILE(4) OVER (ORDER BY SIZE_OF_COLONY DESC) = 2 THEN 'HIGH'
WHEN NTILE(4) OVER (ORDER BY SIZE_OF_COLONY DESC) = 3 THEN 'MEDIUM'
ELSE 'LOW'
END AS COLONY_NAME
FROM ECOLI_DATA
ORDER BY ID;30. 서울에 위치한 식당 목록 출력하기 Level 4

문제에서 요구하는 조건
- 서울에 위치한 식당
- 식당들의 리뷰 평균 점수
- 정렬하기
1. 서울에 위치한 식당 정보와 리뷰 정보를 JOIN
SELECT
FROM
JOIN ON
WHERE일단은 서울에 위치한 식당 정보와 식당의 리뷰 정보가 함께 나오도록 작성해 보자!
ADDRESS LIKE '서울%' 이렇게 작성하면 서울로 시작하는 주소를 가진 모든 식당 정보를 조회할 수 있다.
SELECT *
FROM REST_INFO I
JOIN REST_REVIEW R ON I.REST_ID = R.REST_ID
WHERE ADDRESS LIKE '서울%';짜잔 결과가 잘 나온다!
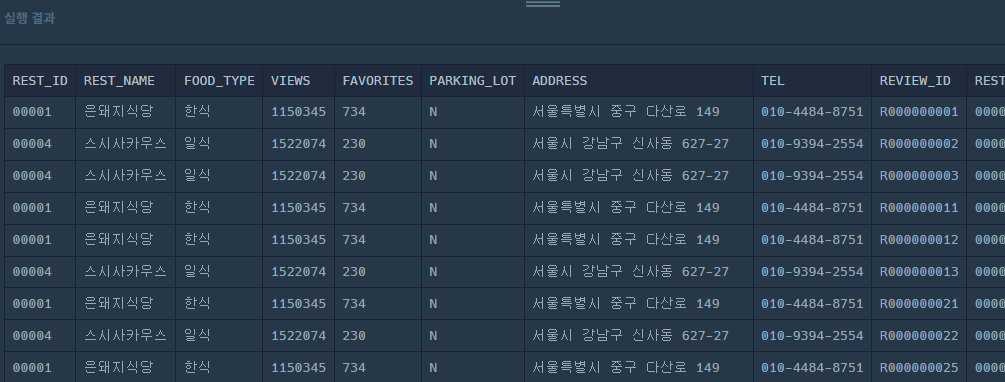
2. 식당별로 그룹화(GROUP BY)해서 리뷰 점수의 평균 구하기
식당별로 그룹화를 할 것이기 때문에 REST_ID로 GROUP BY를 한다.
평균은 AVG로 계산하고, 소수점 세 번째 자리에서 반올림하라고 했기 때문에 둘째 자리까지 구하도록 ROUND(컬럼, 2)를 한다.
SELECT I.REST_ID,
ROUND(AVG(R.REVIEW_SCORE), 2) AS SCORE
FROM REST_INFO I
JOIN REST_REVIEW R ON I.REST_ID = R.REST_ID
WHERE ADDRESS LIKE '서울%'
GROUP BY I.REST_ID;그러면 결과가 이렇게 나온다.
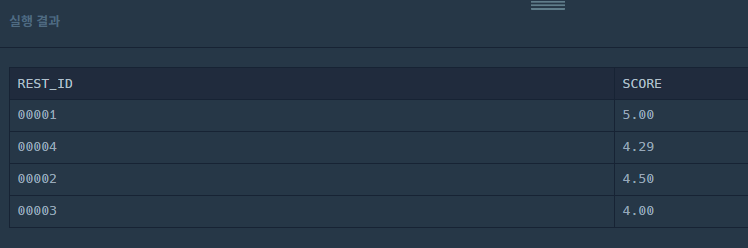
3. ORDER BY로 정렬하기
ORDER BY 컬럼명1 DESC, 컬럼명2 DESC 로 정렬하고, 출력을 요구하는 필드들만 SELECT 문에 적어주면 끝이다!
SELECT I.REST_ID,
I.REST_NAME,
I.FOOD_TYPE,
I.FAVORITES,
I.ADDRESS,
ROUND(AVG(R.REVIEW_SCORE), 2) AS SCORE
FROM REST_INFO I
JOIN REST_REVIEW R ON I.REST_ID = R.REST_ID
WHERE ADDRESS LIKE '서울%'
GROUP BY I.REST_ID
ORDER BY SCORE DESC,
I.FAVORITES DESC;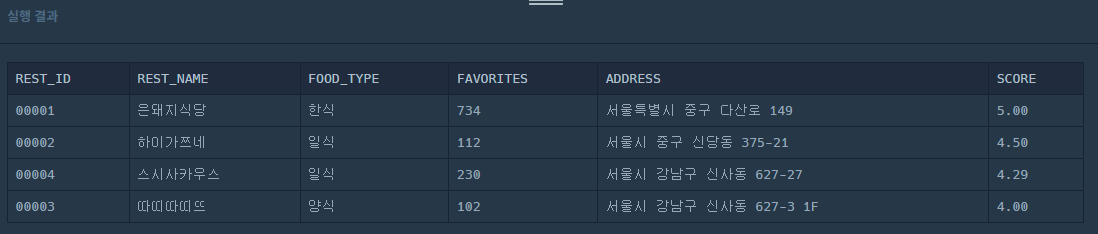
31. 오프라인/온라인 판매 데이터 통합하기 Level 4

1. UNION ALL로 오프라인/온라인 판매 테이블을 합친다.
UNION ALL을 할 때는 두 테이블의 컬럼 개수와 데이터 타입이 일치해야 한다!
SELECT SALES_DATE, PRODUCT_ID, USER_ID, SALES_AMOUNT
FROM ONLINE_SALE
UNION ALL
SELECT SALES_DATE, PRODUCT_ID, NULL AS USER_ID, SALES_AMOUNT
FROM OFFLINE_SALE이때 오프라인 판매 테이블에는 USER_ID가 없는데, 문제에서는 NULL로 표시하라고 하고 있다.
그래서 그냥 NULL AS USER_ID로 표시명은 USER_ID로 하고, 값은 NULL로 채우면 된다,
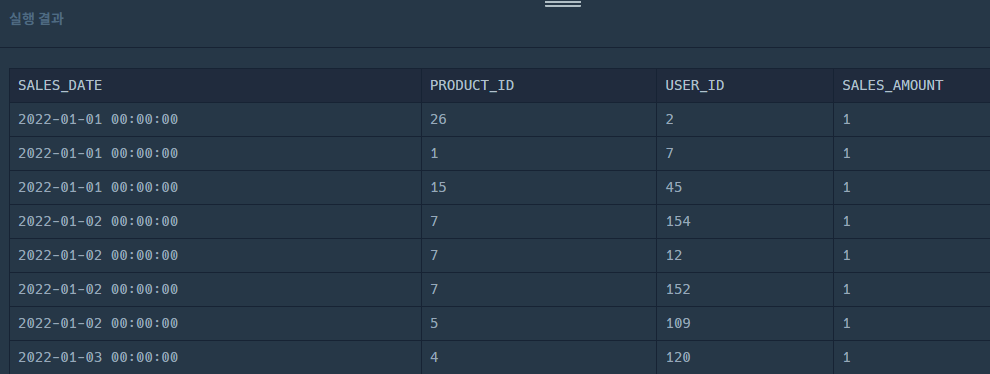
그러면 이렇게 빈값이 있음에도 같이 출력 된다!
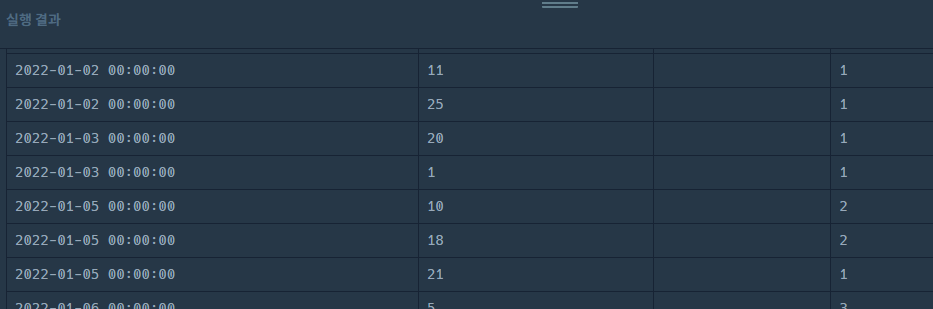
2. 날짜 조건 추가(DATE FORMAT, WHERE 절)
SELECT DATE_FORMAT(SALES_DATE, '%Y-%m-%d') AS SALES_DATE, PRODUCT_ID, USER_ID, SALES_AMOUNT
FROM ONLINE_SALE
WHERE YEAR(SALES_DATE) = 2022
AND MONTH(SALES_DATE) = 3
UNION ALL
SELECT DATE_FORMAT(SALES_DATE, '%Y-%m-%d') AS SALES_DATE, PRODUCT_ID, NULL AS USER_ID, SALES_AMOUNT
FROM OFFLINE_SALE
WHERE YEAR(SALES_DATE) = 2022
AND MONTH(SALES_DATE) = 3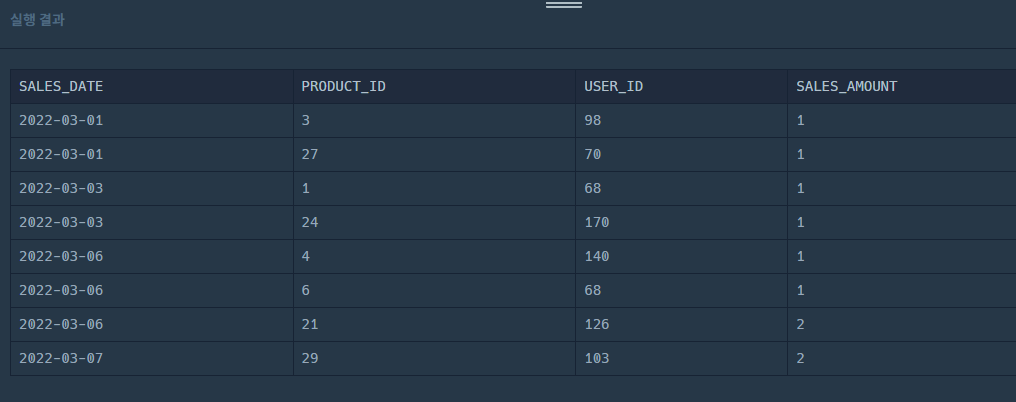
3. 최종적으로 ORDER BY 추가
SELECT
DATE_FORMAT (SALES_DATE, '%Y-%m-%d') AS SALES_DATE,
PRODUCT_ID,
USER_ID,
SALES_AMOUNT
FROM
ONLINE_SALE
WHERE
YEAR (SALES_DATE) = 2022
AND MONTH (SALES_DATE) = 3
UNION ALL
SELECT
DATE_FORMAT (SALES_DATE, '%Y-%m-%d') AS SALES_DATE,
PRODUCT_ID,
NULL AS USER_ID,
SALES_AMOUNT
FROM
OFFLINE_SALE
WHERE
YEAR (SALES_DATE) = 2022
AND MONTH (SALES_DATE) = 3
ORDER BY
SALES_DATE,
PRODUCT_ID,
USER_ID;
32. 특정 세대의 대장균 찾기 Level 4

3세대를 찾기 위해서는 3단계를 거치면 된다.
1. 1세대 찾기
1세대는 부모가 없는 개체다.
SELECT ID
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL;2. 2세대 찾기
1세대를 부모로 갖는 개체가 2세대다.
SELECT ID
FROM ECOLI_DATA
WHERE PARENT_ID IN (
SELECT ID
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
);3. 3세대 찾기
2세대를 부모로 갖는 개체가 3세대다!
SELECT ID
FROM ECOLI_DATA
WHERE PARENT_ID IN (
SELECT ID
FROM ECOLI_DATA
WHERE PARENT_ID IN (
SELECT ID
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
)
);여기에 ORDER BY 조건만 추가해주면 정답이다!!
33. 멸종위기의 대장균 찾기 Level 5

드디어 마지막 문제다!!
Level 5라서 그런지 생각을 하는데 조금 어질어질했다..
- 부모가 없는 개체를 찾는 것도 아니고, 자식이 없는 개체를 찾는 것이다..
- 세대별로 번호를 부여해야한다.
아마도 START WITH(MySQL이라서 안 됨.. WITH RECUTSIVE 써야함)나, JOIN으로 연결한 테이블을 사용하고 그것과 차집합을 해야할 거 같았다.
WITH RECURSIVE
혹시나 WITH RECURSIVE를 모른다면 이 문제를 풀 수 없다..
모르면 지금 바로 배워보자..!
CTE 기본 문법
이건 재귀 CTE 라고 불리는데, 공통 테이블 표현식인 Common Table Expression를 줄여서 CTE 이라고 한다.
아래와 같은 기본 구조를 가진다.
WITH RECURSIVE CTE_NAME AS (
-- 1. 기초 쿼리(시작점, ANCHOR)
SELECT 초기값 FROM 테이블 WHERE 조건
UNION ALL
-- 2. 재귀 쿼리(RECURSIVE PART)
SELECT 새로운 값 FROM 테이블 JOIN CTE_NAME ON 조건
)
SELECT * FROM CTE_NAME;- 기초 쿼리 (Anchor): 재귀의 시작점이다.
- 재귀 쿼리 (Recursive Part): 이전 결과를 기반으로 다음 데이터를 가져온다.
UNION ALL을 사용하여 이전 결과와 새로운 결과를 합친다.
1부터 5까지 출력하는 간단한 재귀
간단한 예시를 보면서 문법을 익혀보자
WITH RECURSIVE NUMBERS AS (
-- 1. 기초 쿼리: 첫 번째 숫자는 1부터 시작
SELECT 1 AS NUM
UNION ALL
-- 2. 재귀 쿼리
SELECT NUM + 1 FROM NUMBERS WHERE NUM < 5
)
SELECT * FROM NUMBERS;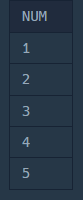
직원 계층 구조 조회
아래와 같은 EMPLOYEE 테이블이 있다고 생각해보자.
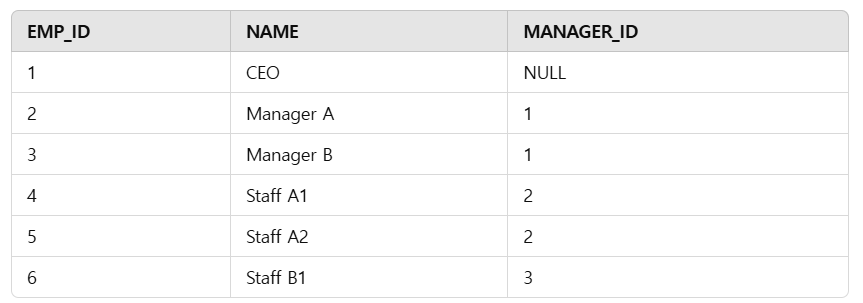
이 테이블에서 직원 계층 구조를 조회하는 SQL문은 이렇게 작성할 수 있다.
- ANCHOR: 회사의 CEO는 MANAGER_ID 가 없기 때문에
WHERE MANAGER_ID IS NULL로 재귀의 시작점을 정할 수 있다. - Recursive Part:
JOIN문을 통해서 이전 테이블과 이후 테이블을 연결한다. 여기서는E.MANAGER_ID = H.EMP_ID로 연결했다. E는 노동자고, H는 고용주다. 즉, 노동자의 매니저 ID와 고용주의 ID가 같은 테이블끼리 연결한다는 것이다. UNION ALL을 사용하여 연결한 결과들을 합친다.
이렇게 작성하고, SELECT * FROM CTE_NAME으로 모두 조회하고 정렬 조건을 추가하면 된다!
WITH RECURSIVE EMP_HIERARCHY AS (
-- 1️⃣ 기초 쿼리: CEO부터 시작 (MANAGER_ID가 NULL)
SELECT EMP_ID, NAME, MANAGER_ID, 1 AS LEVEL
FROM EMPLOYEES
WHERE MANAGER_ID IS NULL
UNION ALL
-- 2️⃣ 재귀 쿼리: 직속 상사의 LEVEL + 1을 하여 직원 계층을 탐색
SELECT E.EMP_ID, E.NAME, E.MANAGER_ID, H.LEVEL + 1
FROM EMPLOYEES E
JOIN EMP_HIERARCHY H ON E.MANAGER_ID = H.EMP_ID
)
SELECT * FROM EMP_HIERARCHY ORDER BY LEVEL, EMP_ID;그러면 이런 결과가 나온다!
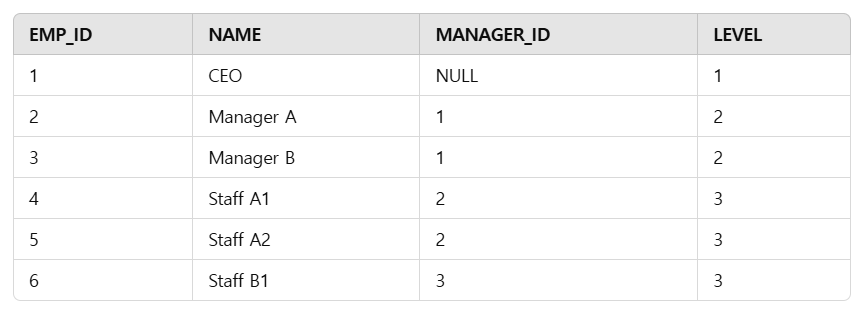
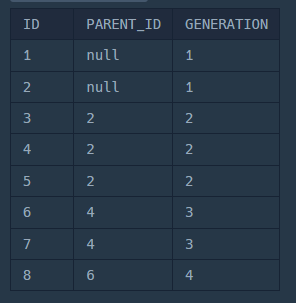
1. 1세대 개체 찾기
PARENT_ID IS NULL로 찾으면 바로 1세대 개체를 찾을 수 있다.
SELECT ID, 1 AS GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL;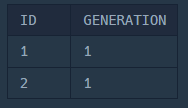
2. 다음 세대 찾기
START WITH는 ORACLE에서 사용하고, MySQL에서는 WITH RECURSIVE를 사용해서 계층 구조를 탐색한다.
위에서 찾은 1세대 개체를 시작으로 해서 UNION ALL을 통해서 2세대 3세대를 찾으면 계속 테이블끼리 합치는 과정을 반복하는 문법이다.
WITH RECURSIVE ECOLI_GENERATION AS (
-- 1. Anchor: 첫 세대 찾기
SELECT ID, PARENT_ID, 1 AS GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
-- 3. UNION ALL
UNION ALL
-- 2. Recursive Part: 다음 세대 찾기
SELECT C.ID, C.PARENT_ID, GENERATION + 1
FROM ECOLI_DATA C
JOIN ECOLI_GENERATION P ON P.ID = C.PARENT_ID
)
SELECT * FROM ECOLI_GENERATION;짠! 세대를 나타내는 수와 계층 구조가 잘 보인다!
LEFT JOIN
LEFT JOIN은 웬만해서는 잘 알 것이다.
A LEFT JOIN B를 하면, A와 B의 교집합과 A에는 존재하지만, B에는 존재하지 않는 것들도 나온다.
그리고 출력하는 컬럼을 A와 B테이블에서 모두 사용하면, A에만 존재하고 B에는 존재하지 않는 것들은 그 값이 NULL로 나온다.
그러면 이 때 WHERE절을 사용해서 B의 컬럼이 NULL인 것들만 출력한다면, B에만 존재하는 것들이 나오게 된다. 즉, LEFT JOIN을 통해서 A-B인 차집합을 구할 수 있는 것이다.
이걸 활용해서 자식이 없는 개체를 찾아보자.
3. 자식이 없는 개체 찾기
부모는 있지만 자식이 없는 개체를 찾아야 한다.
바로 이전의 결과에서 힌트를 얻어야 하는데, 결과 사진을 보면 자식이 없는 세대를 어떻게 찾을 수 있을까?
두 번째 컬럼인 PARENT_ID를 보면, 저기에 PARENT_ID가 없는 ID들은 모두 자식이 없는 개체들이다.
자식이 없기 때문에 누구의 부모도 아니기 때문에 저 결과에서 나오지 않는 것이다.
그러면 여기서 JOIN을 통해서 WITH RECURSIVE의 결과인 ECOLI_GENERATION과 ECOLI_DATA 테이블을 GENERATION.ID = ECOLI_DATA.PARENT_ID이 조건을 통해서 연결하면 어떻게 될까?
뜻으로 생각해보면 부모와 자식이 연결되니까, 자식을 가진 가진 개체들이 나오게 된다.
그리고 여기서 JOIN이 아니라 LEFT JOIN을 하면 어떤 결과가 추가되는 걸까?
바로 자식이 없는 개체가 추가 된다.
왜 그럴까?
그림을 보자.
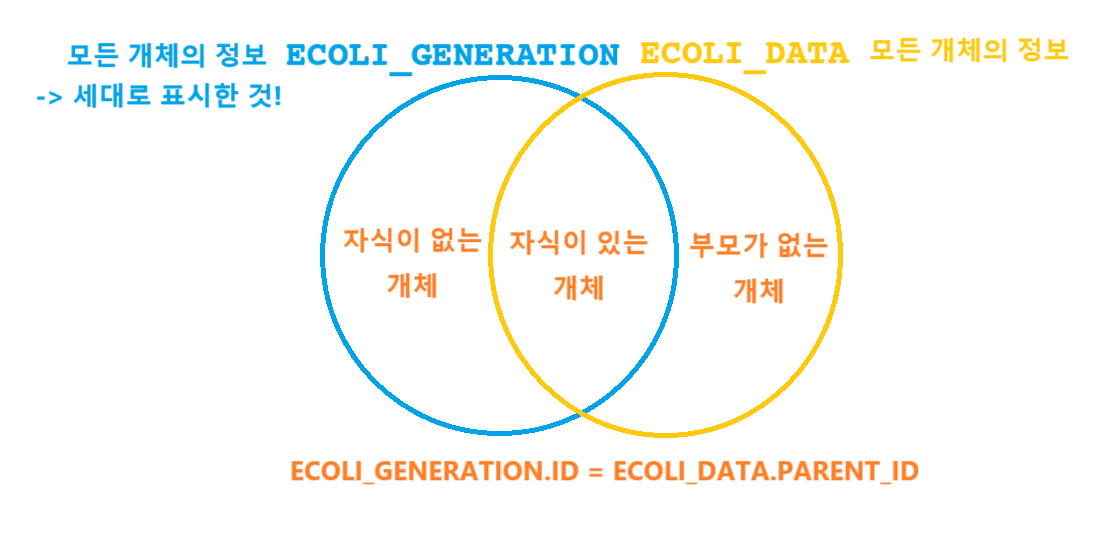
왼쪽의 CTE인 ECOLI_GENERATION나 오른쪽 테이블 ECOLI_DATA나 둘다 모든 개체의 정보를 포함하고 있고, 단순히 세대 표시를 위해 작업의 유무 차이 뿐이다.
그리고 오른쪽 테이블의 PARENT_ID와 왼쪽 테이블의 ID를 연결한 것이기 때문에,
LEFT JOIN을 하면 자식이 없는 개체가
RIGHT JOIN을 하면 부모가 없는 개체가 추가되는 것이다.
SQL문을 작성하면서 그 결과를 하나씩 살펴보자.
- 먼저
JOIN을 하면 자식이 있는 개체들이 나온다.
SELECT EG.ID, E.PARENT_ID
FROM ECOLI_GENERATION EG
JOIN ECOLI_DATA E ON EG.ID = E.PARENT_ID;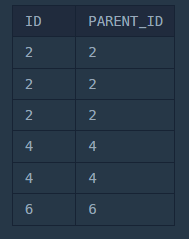
LEFT JOIN을 하면 자식이 없는 개체들의 정보도 포함 된다.
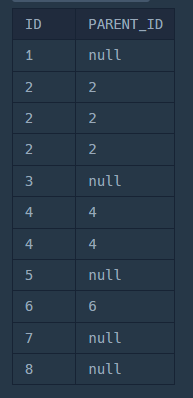
아까 미리 구해놨던, ECOLI_GENERATION의 결과와 한 번 비교해보자.
첫 번째 사진, LEFT JOIN의 결과에서PARENT_ID가 null로 표시된 개체들은 모두 자식이 없는 개체들이다.
왜냐면 코드를 보면, ECOLI_DATA의 PARENT_ID를 출력하려고 했는데, 그 값이 ECOLI_GENERATION에서 찾을 수 없기 때문에 null이 나온 것이다.
SELECT EG.ID, E.PARENT_ID
FROM ECOLI_GENERATION EG
LEFT JOIN ECOLI_DATA E ON EG.ID = E.PARENT_ID;즉, 자식이 없으니까, 자식 입장에서 당연히 부모를 찾을 수 없는 것이고, 그래서 null로 표시된 것이다.
마찬가지로 아래의 ECOLI_GENERATION의 결과에서 보면 PARENT_ID 컬럼에서 그 개체들의 ID가 한 번도 등장하지 않았다.
그러면 이 때, E.PARENT_ID IS NULL을 WHERE 절에 추가해주면 자식이 없는 개체들만 나오지 않을까?
WHERE E.PARENT_ID IS NULL추가
당연하게도 자식이 없는 개체들만 잘 나온다!

4. 세대별로 자식 없는 개체 수 구하기
마지막 단계는 쉽다!
기존에 SELECT 문에서 출력하던 컬럼들 대신 요구하는 대로,
세대로별로 COUNT를 해서 출력하면 된다.
GROUP BY절에 ECOLI_GENERATION에 미리 만둘어둔 컬럼인 GENERATION을 통해서 그룹화를 하고, 집계함수 COUNT를 통해서 세대별로 세어주면 된다.
그리고 정렬도 수행하면 끝이다!
최종 답이니까 프리티어로 정렬도 해줬다ㅎ
WITH RECURSIVE ECOLI_GENERATION AS (
-- 1. Anchor: 첫 세대 찾기
SELECT ID,
PARENT_ID,
1 AS GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL -- 3. UNION ALL
UNION ALL
-- 2. Recursive Part: 다음 세대 찾기
SELECT C.ID,
C.PARENT_ID,
GENERATION + 1
FROM ECOLI_DATA C
JOIN ECOLI_GENERATION P ON P.ID = C.PARENT_ID
)
SELECT COUNT(EG.ID) AS COUNT,
EG.GENERATION
FROM ECOLI_GENERATION EG
LEFT JOIN ECOLI_DATA E ON EG.ID = E.PARENT_ID
WHERE E.PARENT_ID IS NULL
GROUP BY EG.GENERATION
ORDER BY EG.GENERATION;정답이다 ㅎ
이로써 SELECT 문 고득점 Kit 끝이다!
