학교 데이터베이스 시간에 배웠던 자료를 다시 한 번 훑어보겠습니다.
관계 대수와 SQL
관계 대수란?
릴레이션을 처리하기 위한 연산자 집합
or 릴레이션을 조작하기 위한 절차적 언어
관계 연산자 종류
종류를 여러 가지로 나눌 수 있습니다.
-
필수 연산자 vs 유도된 연산자
-
단항 연산자 vs 이항 연산자
여기서 1번 필수 연산자, 유도된 연산자를 기준으로 개념 공부를 해보자
셀렉션(selection)
셀렉션 조건을 만족하는 튜플들의 부분집합을 구하는 필수 관계 연산자
프로젝션(projection)
프로젝션 조건을 만족하는 애트리뷰트들의 부분집합을 구하는 필수 관계 연산자
특징 : 중복된 애트리뷰트는 중복 제거하고 보여줌
집합 연산자
피연산자인 두 개의 릴레이션은 합집합 호환 조건을 만족해야 집합 연산자를 사용할 수 있음
합집합 호환 조건이란?
R(A1, A2, A3, ..., An)와 S(B1, B2, B3, ..., Bm) 테이블이 있을 때
1번 조건 차수가 같고(n=m이고)
2번 조건 도메인이 같으면( domain(Ai) == domain(Bi) ) "합집합 호환 조건"을 만족한다고 할 수 있다.
합집합 연산자
중복을 제거한 R과 S의 모든 튜플들로 만든 릴레이션을 구하는 필수 관계 연산자
교집합 연산자
R과 S의 모두에 속한 튜플들로 이루어진 릴레이션을 구하는 필수 관계 연산자
차집합 연산자
R - S는 R에만 있는 튜플들로 이루어진 릴레이션을 구하는 유도된 관계 연산자
카티션 곱 연산자
R과 S의 모든 가능한 조합으로 이루어진 릴레이션을 구하는 필수 관계 연산자
카디날리티(튜플의 개수)가 i이고 차수(애트리뷰트의 개수)가 n인 R(A1, A2, A3, ..., An)테이블과 카디날리티가 j이고 차수가 m인 S(B1, B2, B3, ..., Bm)테이블의 모든 가능한 튜플 조합을 말한다.
그럼 R과 S의 카티션 곱은 (A1, A2, ..., An, B1, B2, ..., Bm)으로 차수가(n+m)이고 카디날리티가 (i*j)
관계 대수의 완전성
필수 관계 연산자 : 셀렉션, 프로젝션, 합집합, 차집합, 카티션 곱관계적 완전
임이의 질의어가 적어도 필수 관계 연산자만큼의 표현력을 가지고 있으면 관계적으로 완전(relationally complete)하다고 말한다.간단히 말해서 질의어가 필수 관계 연산자를 표현할 수 있으면 관계적으로 완전한 질의어다.
조인 연산자
두 개의 릴레이션으로부터 **공통 속성**을 이용해 연관된 튜플을 결합하는 연산자세타 조인
조인에 참여하는 두 릴레이션의 속성 값을 비교하여 조건을 만족하는 튜플만 반환동등 조인
세타 조인 중에서도 비교 연산자가 = 인 조인자연 조인
동등 조인에서 중복된 속성 중 하나를 제외한 조인외부 조인
세미 조인
릴레이션 S의 조인 속성으로만 구성한(프로젝트한) 릴레이션을 릴레이션 R에 자연 조인 ???디비전 연산자
R % S 에서 릴레이션 S의 모든 튜플 과 관련있는 릴레이션 R의 튜플로 결과를 구성
관계 대수의 한계
1. 산술 연산을 할 수 없음 2. 집단 함수(aggregate function)를 지원하지 않음 3. 정렬을 나타낼 수 없음 4. 데이터베이스를 수정할 수 없음 5. 프로젝션 결과에 중복된 튜플을 명시하지 못함이런 한계때문에 관계 DBMS의 표준 질의어인 SQL은 이런 요구사항을 모두 지원한다.
그래서 추가된 것들
- 집단 함수(SUM, AVG, MIN, COUNT) 말 그대롭니다.
- 그룹화 집단 함수를 사용하면 여러 개의 튜플들이 하나로 묶이기 때문에 그룹화된다고 함
- 외부조인 조인하는 릴레이션에 대응하지 못하는 튜플들과 널값인 튜플들을 나타내기 위한 조인
SQL 개요
정의 : Structured Query Language
특징 :
-
비절차적 언어(선언적 언어)이므로 사용자는 자신이 원하는 바(what)만 명시
하며, 원하는 것을 처리하는 방법(how)은 명시할 수 없음 -
자연어에 가까운 구문을 사용하여 질의를 표현할 수 있음
-
현재 DBMS 시장에서 관계 DBMS가 압도적인 우위를 차지하는데 중요한 요인의 하나
-
SQL은 IBM 연구소에서 1974년에 System R이라는 관계 DBMS 시제품을 연구할 때
관계 대수와 관계 해석을 기반으로, 집단 함수, 그룹화, 갱신 연산 등을 추가하여 개발
된 언어 -
1986년에 ANSI(미국 표준 기구)에서 SQL 표준을 채택함으로써 SQL이 널리 사용됨
-
다양한 상용 관계 DBMS마다 지원하는 SQL 기능에 다소 차이가 있음
오라클 SQL의 구성요소
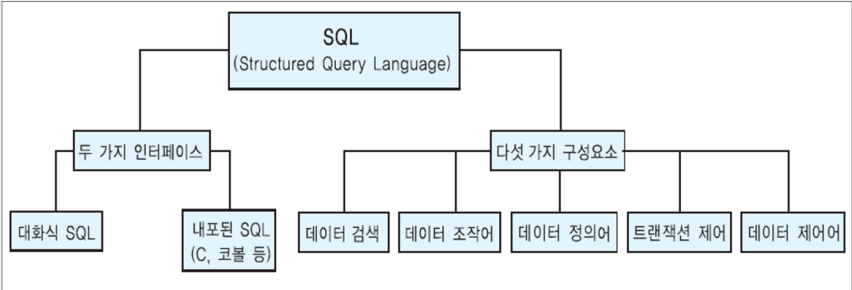
두 가지 인터페이스
- 대화식 SQL (interactive SQL)
- 내포식 SQL (embedded SQL)
다섯 가지 구성 요소
- 데이터 검색 : 데이터베이스로부터 데이터를 검색
- 데이터 조작어(DML, Data Manipulation language) : DB 스키마 내의 데이터를 삽입, 삭제, 수정
- 데이터 정의어(DDL, Data Definition Language) : 릴레이션, 애티리뷰트, 뷰, 인덱스를 생성 및 제거
- 트랜잭션 제어 : 트랜잭션의 시작, 철회, 완료를 제어
- 데이터 제어어(DCL, Data Control language) : 릴레이션에 대한 권한을 부여 또는 취소
애트리뷰트 제약조건
- NOT NULL : 널 값을 허용하지 않음
- UNIQUE : 동일한 애트리뷰트가 동일한 값을 가지지 않도록 보장
- DEFAULT : 값 지정 안하면 기본 지정 값 저장
- CHECK : 애트리뷰트가 가질 수 있는 값의 범위 지정, 관계 지정도 가능
- PRIMARY KEY : 기본 키를 지정함
- FORIEGN KEY : 참조 무결성 제약조건 정의함
- ON DELETE NO ACTION - RESTRICT와 같은 의미임 (삭제 연산 거절)
- ON DELETE CASCADE (연쇄 삭제)
- ON DELETE SET NULL (NULL 값 부여)
- ON DELETE SET DEFAULT (디폴트 값 부여)
- ON UPDATE NO ACTION - 오라클은 UPDATE에 대해서는 NO ACTION만을 지원함
SELCT 문
관계 DBMS(RDB)에서 정보를 검색하는데 쓰이는 SQL문
관계 대수의 셀렉션, 프로젝션, 조인, 카티션 곱 등을 결합한 것
기본적인 질의
SELECT와 FROM만 필수적인 절이고 나머지 WHERE, GROUP BY, HAVING, ORDER BY 등의 나머지 절은 선택 사항별칭(alias)
서로 다른 릴레이션에 동일한 애트리뷰트가 존재할 때 애트리뷰트 이름을 구분하기 위한 방법
FROM EMPLOYEE AS A, DEPARTMENT AS B 로 서술하고 AS는 생략 가능
부정 조건 검색
WHERE TITLE="과장" AND DNO <> 1; <>는 프로그래밍에서 자주 쓰이는 != 의 의미로 사용됩니다.범위를 사용한 검색 BETWEEN
급여가 30000 ~ 45000 인 사람들WHERE SALARY BETWEEN 30000 AND 45000;
급여가 30000이상 45000이하 인 사람들
WHERE SALARY BETWEEN SALARY >= 30000 AND SALARY <= 45000;
리스트를 사용한 검색 IN
부서번호(DNO)가 1,3인 것들
WHERE DNO IN (1,3);
SELECT 절에서 산술 연산자(+, -, *, /) 사용
현재 급여, 현재 급여가 10퍼센트 인상되었을 때 값 검색
SELECT SALARY, SALARY * 1.1 AS NEWSALARY FROM ~
널값 사용
DNO=NULL처럼 나타내면 안 됨 WHERE DNO = NULL; -> X
IS NULL, IS NOT NULL WHERE DNO IS NULL; -> O
널값을 포함한 연산 결과는 널 값
검색 조건에서 널값은 다른 값과 비교하면 결과는 모두 거짓
순서 정렬 ORDER BY
SELECT가 원래 데이터를 보여주는 순서는 튜플들이 삽입된 순서대로 보여줌디폴트 정렬 순서는 오름차순(ASC)
내림차순 정렬시 DESC 사용
여러 개의 애트리뷰트를 사용하여 정렬할 수 있다
집단 함수
여러 튜플 집단에 적용되는 함수SELECT절과 HAVING절에만 나타날 수 있음
사용시 키워드 DISTINCT의 순서 조심
집단 함수 앞에 사용되면 집단 함수가 적용되기 전에 먼저 중복을
제거함
그룹화 GROUP BY
특정 애트리뷰트의 값이 같은 튜플을 모아 그룹으로 묶을 때그룹 조건절HAVING
그룹에 대한 질의 조건은 HAVING 절에 명시HAVING 절에 나타나는 애트리뷰트는 반드시 GROUP BY절에 나타나는 애트리뷰트 또는
집단 함수에 포함되어야 한다
집합 연산
합집합 호환성을 가져야 사용 가능
합집합, 차집합, 교집합 등
조인
두 릴레이션의 공통 속성을 가지고 연관된 튜플을 결합체계를 만들기 애매한 것들
DISTINCT
중복된 튜플을 제거할 때 사용
LIKE 구문 사용법
쿼리문 WHERE절에 주로 사용되며 부분적으로 일치하는 칼럼을 찾을때 사용됩니다.
WHERE절에 사용되어 부분적으로 일치하는 문자열을 찾을 때 사용합니다.
SELECT * FROM EMPLOYEE WHERE EMP_NAME LIKE'김%'; -> 김으로 시작하는 사원
SELECT * FROM EMPLOYEE WHERE EMP_NAME LIKE '%김'; -> 김으로 끝나는 사원연산자 우선순위
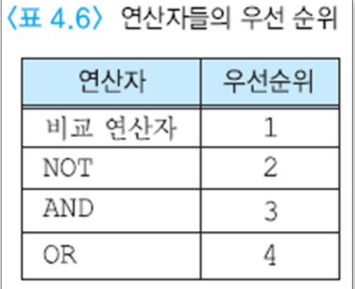
우선순위를 알고있다면 복잡한 쿼리문에서 오류를 피할 수 있을 겁니다.

좋은 글 이네요. 잘 봤습니다.