인턴기
1.문제은행 DB 설계 분투기 1 - erdcloud 사용법
일단 DB에 관계자는 누가있는지그리고 해당 DB의 테이블은 크게 뭐가 있을지를 구상하고erdcloud.com에서 erd 다이어그램을 그리려고하니까 phisical name과 logical name이 있었다.그래서 찾아봤다.https://velog.io/@k90
2.문제은행 DB 설계 분투기 2 - 어떤 개념이던 시간이 지나면 까먹는다 자주 찾아보자

이제 v2 시험 응시 관련 DB를 만드려고 합니다.어떻게 진행되면 좋을까요?랜덤하게 문제를 뽑고싶다고 하셨는데그게 난이도가 있으면 랜덤함수를 넣어 돌리기 어렵다는 글을 어디서 본 것 같아 다시 한 번 읽어봅니다. - 링크그런데 랜덤 개념에 들어가기도 전에 허점을 발견했
3.문제은행 DB 설계 분투기 3 - 개념설계 발표 PPT 만들기

이제는 발표할 PPT를 만들어봅니다.PPT를 만들 때각 장의 쪽수를 자동 추적으로 만들어주면 좋겠네요자동 쪽수 만들기 방법 링크 - https://alluze.tistory.com/entry/How-to-Automatically-Insert-Numbers-in
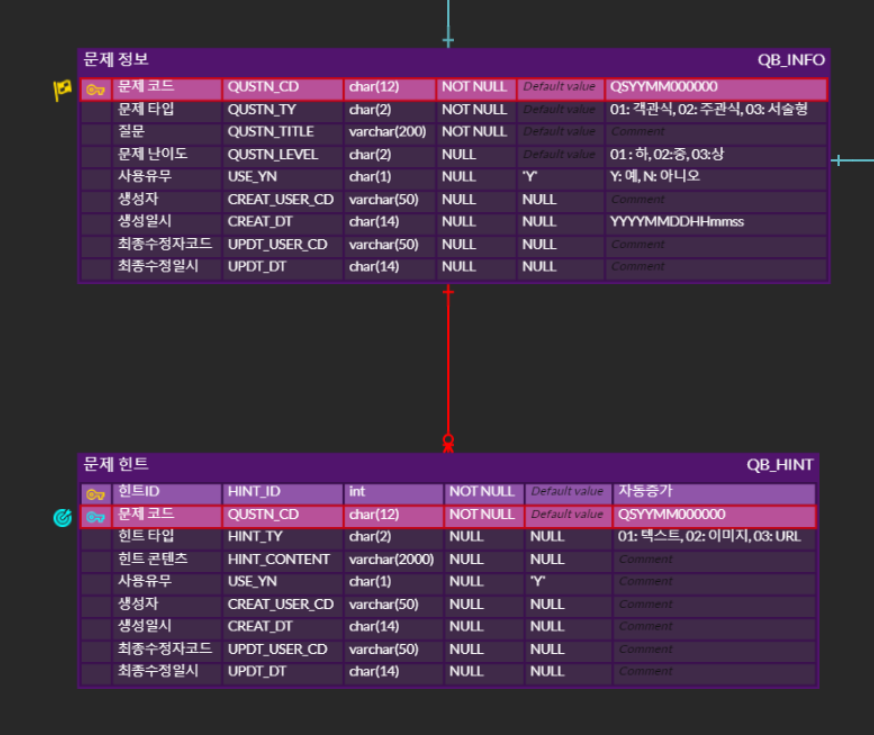
4.문제은행 DB 설계 분투기 4 - char과 varchar 중 선정, 새발 표기 꿀팁, 단어 길이 줄이기
제가 그린 ERD를 사수님께 보여드리니 네이밍 규칙을 참고해서 수정하라고 하셨습니다.그래서 수정하기 전 어떤 표기법들을 사용하는지 알아봤고그러면서 다양한 표기법들을 배워봤습니다.https://eblo.tistory.com/136대표적으로는 스네이크 표기법과 카
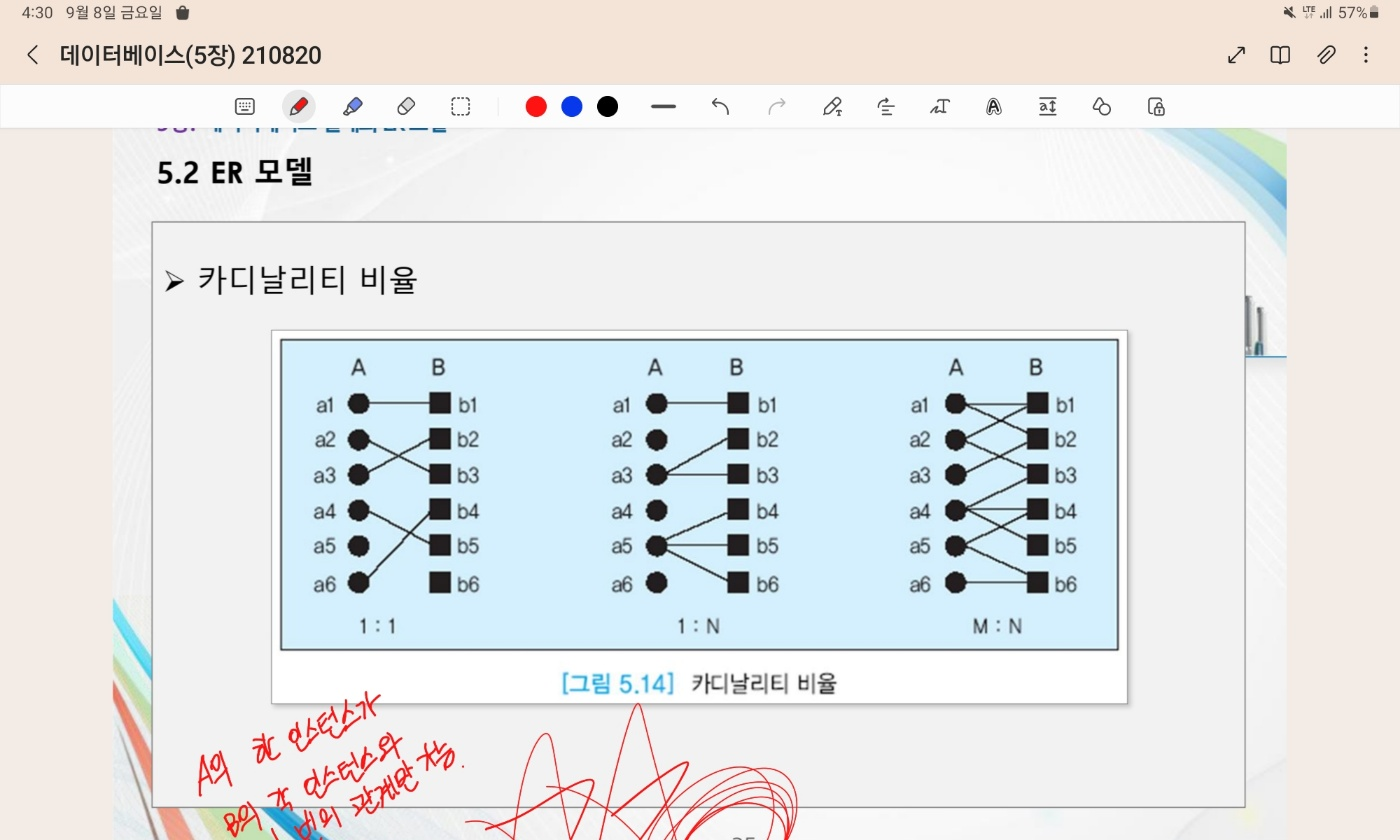
5.문제은행 DB 설계 분투기 5 - 스키마 정제, varchar와 text 타입의 차이
부분키가 무엇인가 하여찾아보았습니다.강한 엔티티 타입은자신이 가진 애트리뷰트만을 이용해서 엔티티를 고유하게 식별할 수 있는 타입을 말합니다.약한 엔티티 타입은자신이 가진 애트리뷰트만을 이용해서 엔티티를 고유하게 식별할 수 없는 타입을 말합니다.약한 엔티티 타입이 고유한
6.문제은행 DB 설계 분투기 6 - forign key 넣는 SQL문
만든 ERD를 가지고정규화와 역정규화를 진행해보려합니다.정규화는원래 릴레이션을 무손실 분해함으로써발생할 수 있는 갱신 이상과 중복을 최소화하여일관성과 정확성을 유지하기 위한 과정입니다.주어진 릴레이션 스키마를 함수적 종속성과 기본 키를 기반으로 분석합니다.정규화를 하기
7.문제은행 DB 설계 분투기 7 - TABLE 만들기 관련 SQL문
제가 회사 인턴을 하며 만든 문제은행 ERD와 회사에서 받은 ERD에는다른 점이 있습니다.네이밍 규칙이 존재테이블에 들어있는 애트리뷰트가 엄청 많음제가 작성한 사용자 테이블에는 아이디, 코드, 유입 서비스 명 만 들어있었다면회사에서 실제로 사용하는 이름, 이메일, 사용
8.문제은행 DB 설계 분투기 8 - SQL문에서 변수 선언하기, exports 와 module.exports의 차이
이제 데이터베이스의 select문으로 데이터들을 가져올 생각입니다.
9.문제은행 DB 설계 분투기 9 - 라우팅 엔드포인트 선언 순서, params와 query의 차이점

오늘은 어제 만들어봤던 로그인 API를 기반으로 다른 기능의 API도 만들 예정입니다.그래서 마이바티스를 학습하고 적용시켜볼 예정이구요일찍 끝나게 된다면 데이터베이스 공부를 하고있을 예정입니다.그 전에 이 프로젝트를 실행했을 때 무슨 미들웨어가 작동하는지, 어떤 동작이
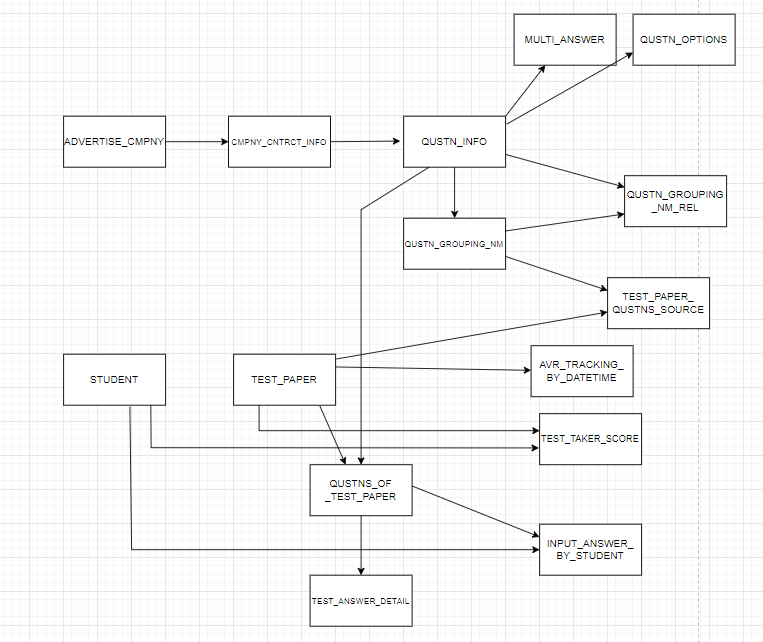
10.문제은행 DB 설계 분투기 10 - 문제은행 DB 관련 API 구조도
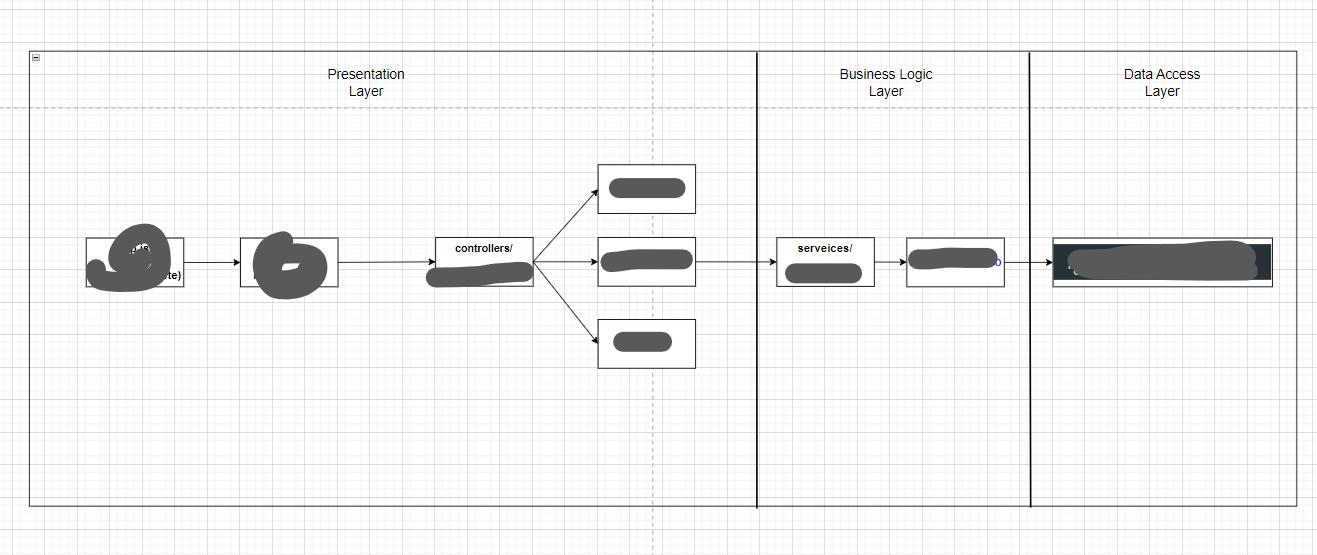
문제 DB 관련 API를 만들어보려합니다.근데 사람은 3개 초과된 개념들을 머리에 담기 힘들다는 사실 알고 계시나요?그렇기때문에 MVC패턴과 같은 3개 이상의 개념인 것들은 구조도를 그려서 진행하려합니다.이런 식으로 진행해봤습니다.이렇게 구조도를 그려서 가시성을 높이니
11.문제은행 DB 설계 분투기 11 - IDE 종료시 git commit 습관화하기
깃 브랜치를 병합하려합니다.git add , git commit을 습관화하지 않으면이런 귀찮은 일들이 생기네요.아침에 업무를 시작할 때 브랜치로 파서 작업을 시작하려다가 보니 git commit 안 한 파일이어서 부랴부랴 git commit을 진행하고 업무 시작할 때
12.문제은행 DB 설계 분투기 13 - 오타그만, 띄어쓰기 있으면 다른 string으로 인식

오늘은 CRUD를 모두 완성시켜볼 생각이다.업데이트 쿼리문은 잘 실행이 되는데result가 없다.왜 그런걸까이렇게 오타를 내놨기 때문에 그렇습니다.오류가 나는 부분을 점점 특정하여 쿼리문이 정상 실행되어도 아무런 영향이 없다는 것을 깨달았고, 그렇게 WHERE절의 문제
13.문제은행 DB설계 분투기 14
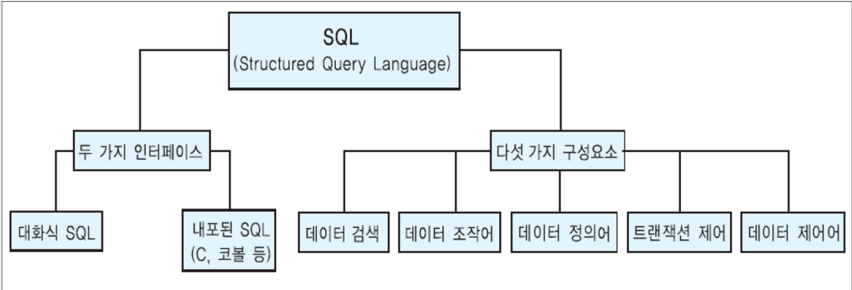
학교 데이터베이스 시간에 배웠던 자료를 다시 한 번 훑어보겠습니다.릴레이션을 처리하기 위한 연산자 집합필수 연산자 vs 유도된 연산자단항 연산자 vs 이항 연산자여기서 1번 필수 연산자, 유도된 연산자를 기준으로 개념 공부를 해보자사수님께서 SQL문을 사용하는 걸 중점
14.문제은행 DB설계 분투기 15
쿼리문을 공부해보도록 하겠습니다. 만약 이런 쿼리문이 있다고 했을 때 하나하나 분석해볼까요? SELECT, FROM, WHERE, ORDER BY, LIMIT 각각의 절들을 살펴보죠 SELECT는 말 그대로 저러한 데이터들을 행으로 가져오고 FROM : 이러한 테이블에