[DL 11강] Training Neural Network II
SPS LAB 2025.02.13 신입생 세미나 4주차
- 본 내용은 Michigan University의 Deep Learning for Computer Vision 11강 Training Neural Networks II 강의를 듣고 정리한 내용입니다.
- 강의의 원본은 해당 링크에서 확인하실 수 있습니다.
1. Training dynamics
1. Learning rate schedules
- 비교
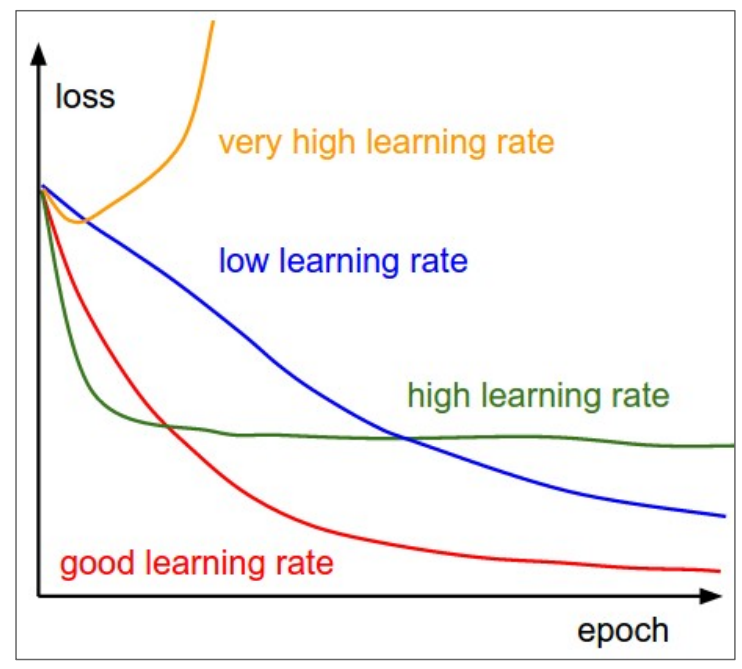
- very high: 손실이 폭발, 매우 빠르게 잘못될 수 있음
- high: 빨리 수렴하지만 최적값에 수렴하지 않을 수 있음
- low: 폭발하지 않지만 매우 느리게 수렴하여 학습 시간이 오래 걸릴 수 있음
- good: 이상적인 좋은 학습률로, 빠르게 수렴하면서 폭발하지 않음
- 아이디어
- 모든 것을 선택하는 것이 어차피 일반적이고, 비교적 높은 학습률로 시작하여 최적의 학습률을 찾는 것
- 방법론
- Step Schedules
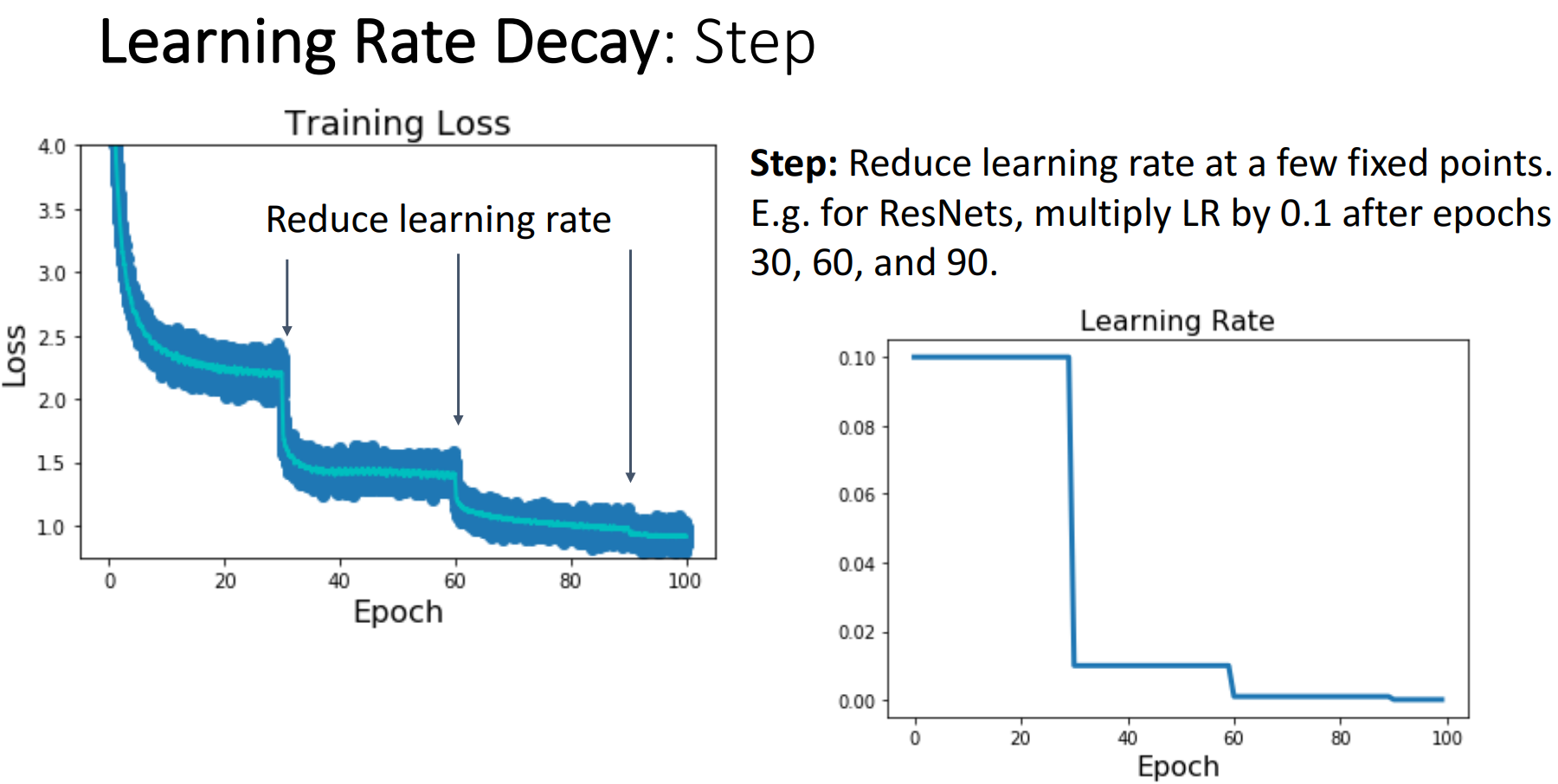
- 개념
- 높은 학습률로 학습을 진행하다가 특정 선택된 지점에서 학습률을 낮추는 방법
- ex) ResNets: 30, 60, 90 epoch마다 learning rate에 0.1을 곱함
- 문제점
- 많은 새로운 하이퍼파라미터를 도입해야 함
- 초기 학습률
- 어느 반복에서 학습률을 감소시킬 것인가
- 감소시킬 반복에서 선택할 새로운 학습률
- 시행 착오가 많이 필요함
- Cosine Schedules
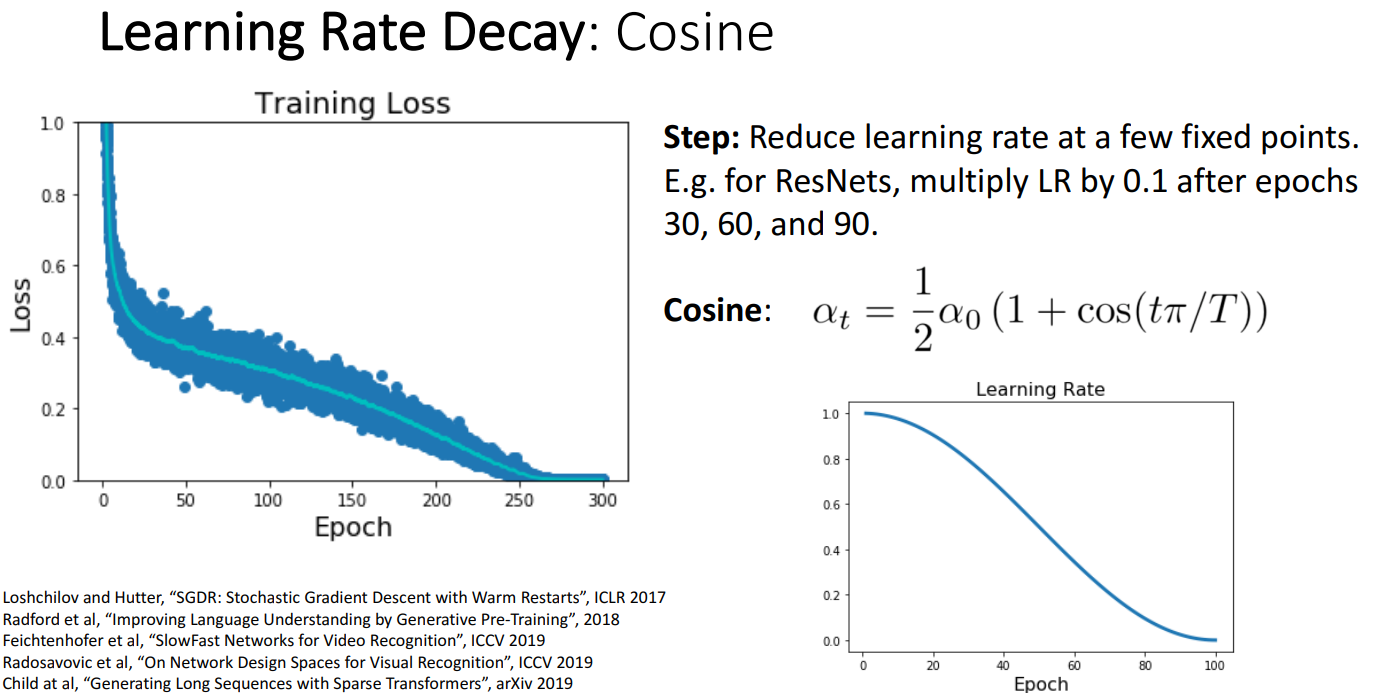
- 개념
- cosine 함수를 통해 모든 epoch마다 학습률을 설정하는 방법
- 학습률이 초기 높은 값에서 시작하고, epoch이 커질수록 학습률이 감소
- 주로 Computer Vision 프로젝트에서 사용 (확실 x)
- 장점
- Step Schedules보다 하이퍼파라미터(초기 학습률 = α0, epoch 수 = t)가 훨씬 적음
- 더 오래 학습할수록 더 잘 작동하는 경향이 있음
- Linear Schedules
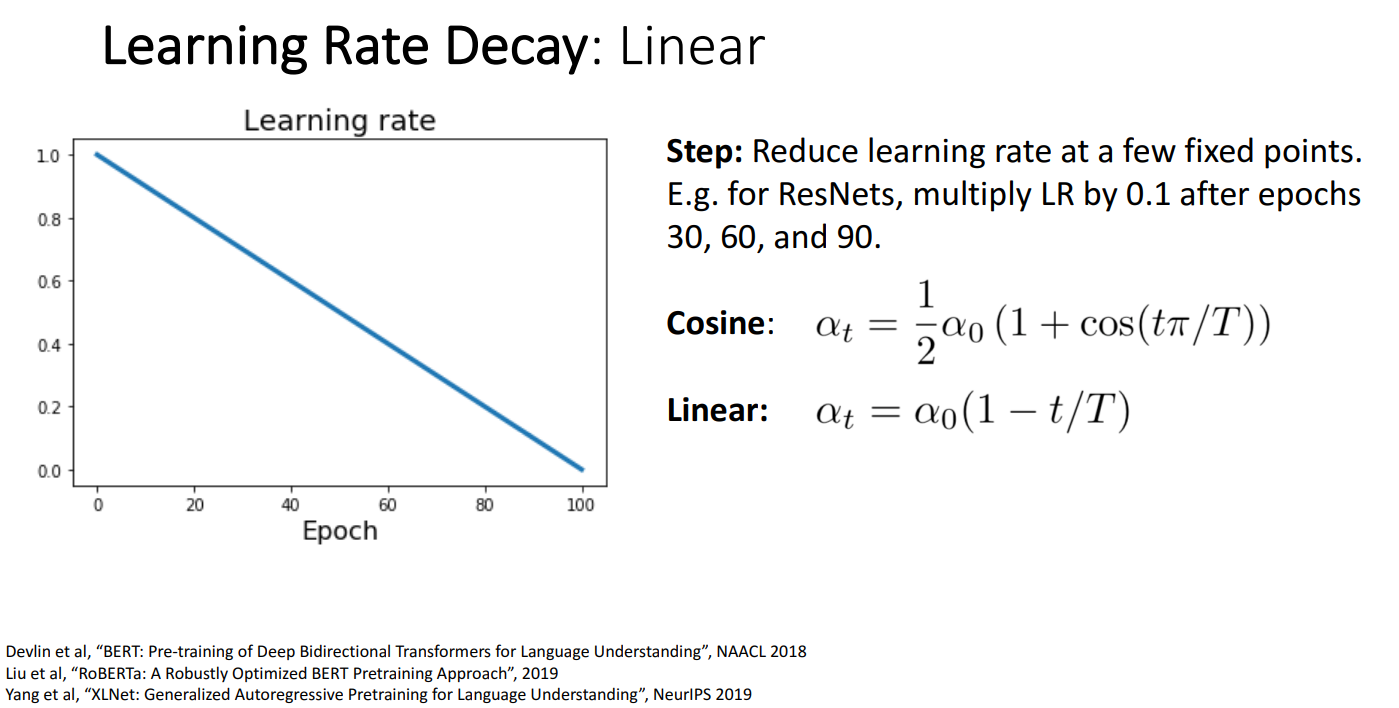
- 개념
- 학습 속도를 선형적으로 감소시키는 방법
- 주로 deep Neural Network를 사용하여 훈련된 대규모 NLP에서 사용 (확실 x)
- Inverse Sqrt Schedules

- 개념
- 역제곱근 활용하여 학습률을 감소시키는 방법
- Cosine, Linear보다 선호되지 않음
- 단점
- 모델이 초기 높은 학습률에 매우 적은 시간을 보냄
- Constant Schedules

- 개념
- 초기 학습 속도를 설정한 다음 이를 유지해주는 방법
- 실제로 많은 문제에 대해 잘 작동
- 관련 팁
- Momentum + SGD -> Learning Rate Schedule 선택이 중요
- RMSProp, Adam와 같은 복잡합 최적화 도구 -> Constanct 사용해도 좋음
- Eary Stopping
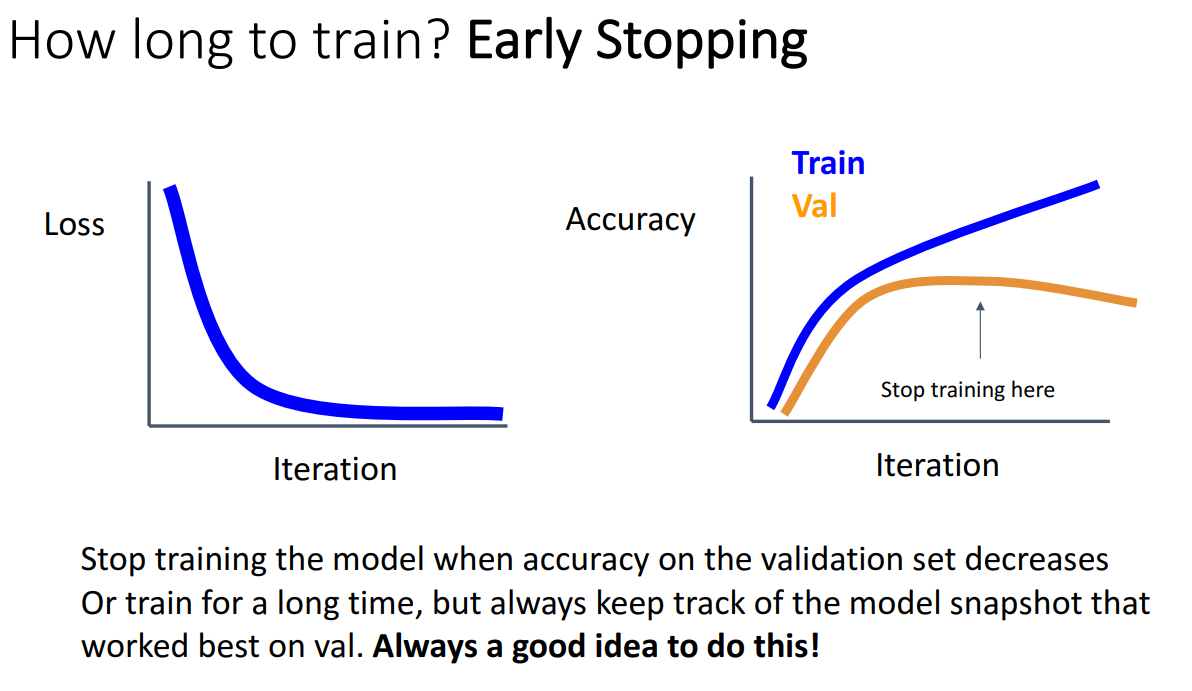
- 얼마나 오랫동안 훈련해야 하는지 선택하는 역할
- 특정 epoch마다 validation set의 정확도를 확인하고 가장 좋은 성능을 보인 해당 지점의 모델의 매개변수를 저장
2. Choosing Hyperparameters (With GPU)
- Grid Search

- 튜닝하려는 하이퍼 파라미터 집합에 몇 개의 후보 값을 정하고, 가능한 모든 조합을 평가하여 최적의 조합을 찾는 방법
- 일반적으로 로그 스케일(log-linearly spaced)로 선택하는 경우가 많음
- 조정하려는 하이퍼 파라미터 수에 따라 지수적으로 증가하는 GPU가 필요
- Random Search

- Grid Search처럼 모든 조합을 탐색하는 것이 아니라, 무작위(random)로 샘플링하여 실험
- 연산량 감소
- Grid Search vs. Random Search
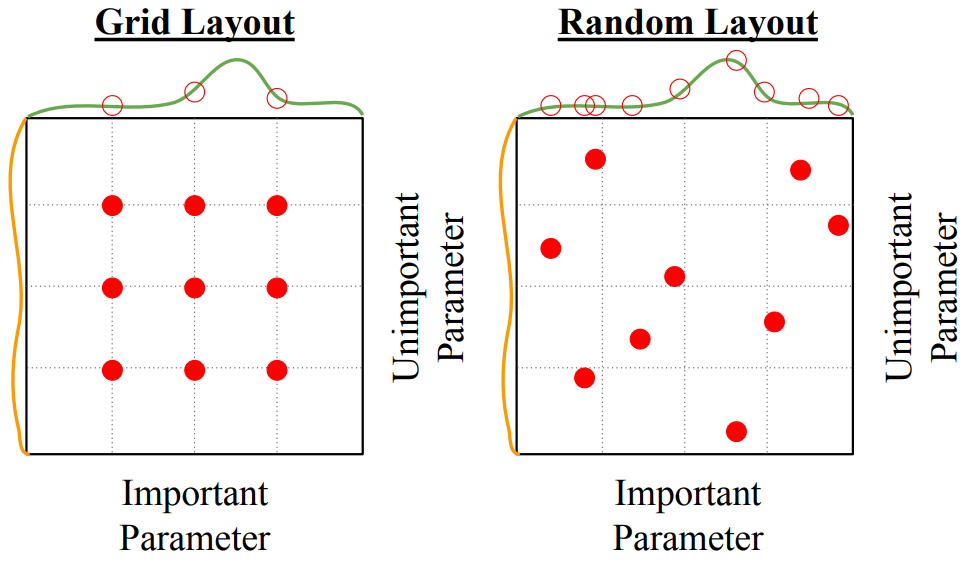
- Grid Search
- 고정된 간격(grid)으로 정해진 위치에만 샘플링 (빨간 점이 선택된 하이퍼파라미터 조합).
- 중요한 하이퍼파라미터(Important Parameter)에 대한 최적의 값을 찾기 어려울 수 있음.
- 만약 중요하지 않은 파라미터(Unimportant Parameter)에 많은 계산을 할당하면 비효율적인 탐색이 발생할 수 있음.
- Random Search
- 무작위로 하이퍼파라미터 값을 선택 (빨간 점이 불규칙하게 분포).
- Grid Search와 달리 중요한 파라미터 공간을 더 넓게 탐색할 가능성이 높음.
- 비효율적인 공간에 대한 연산 낭비를 줄이고, 최적의 값을 더 빠르게 찾을 가능성이 높음.
3. Choosing Hyperparameters (Without GPU)
- Step 1. 초기 loss를 check하기
- weight decay 없이 초기 loss 확인
- Step 2. small sample에 overfit하게 만들기
- 훈련 데이터의 작은 샘플(5~10 minibatches)에서 100% 정확도가 나오게 훈련을 진행
- regularization 없이 architecture, learning rate, weight initialization을 통해 진행
- 그래도 loss가 안 떨어지면 Learning rate를 낮추거나, 올바른 initialiation 방법을 선택해야 함
- Step 3. Loss가 감소하는 Learning rate 찾기
- 2단계에서 결정된 아키텍처를 사용하고 모든 학습 데이터를 사용
- weight decay를 켜고 손실을 유발하는 learning rate 찾음
- 100회 반복 이내에 손실 크게 감소
- Step 4. 하이퍼파라미터 grid를 1~5 epoch으로 훈련
- learning rate와 weight decay의 몇 가지 값을 선택하고, 몇 가지 모델을 훈련
- Step 5. Refine grid, train longer
- Step 4에서 가장 좋은 성능의 모델을 선택하고, learning rate decay 없이 10~20 epoch으로 더 오래 훈련을 진행
- Step 6. Learning Curves 확인
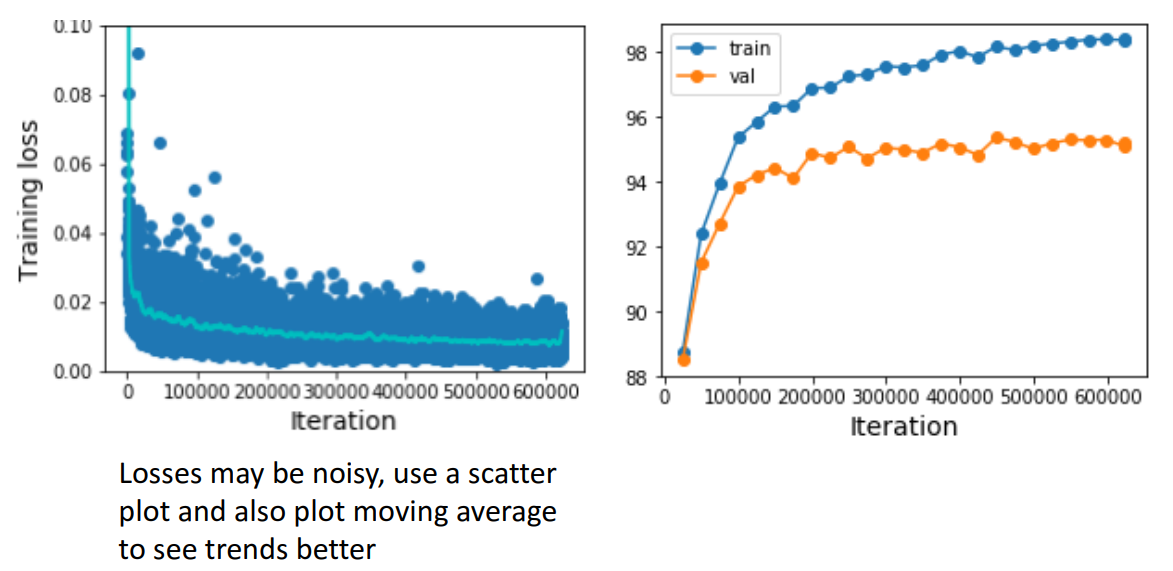
- Learning Curve를 보고 적절한 방안들을 적용해줘야 함
- train loss가 초기에 평평하다가 감소하는 경우
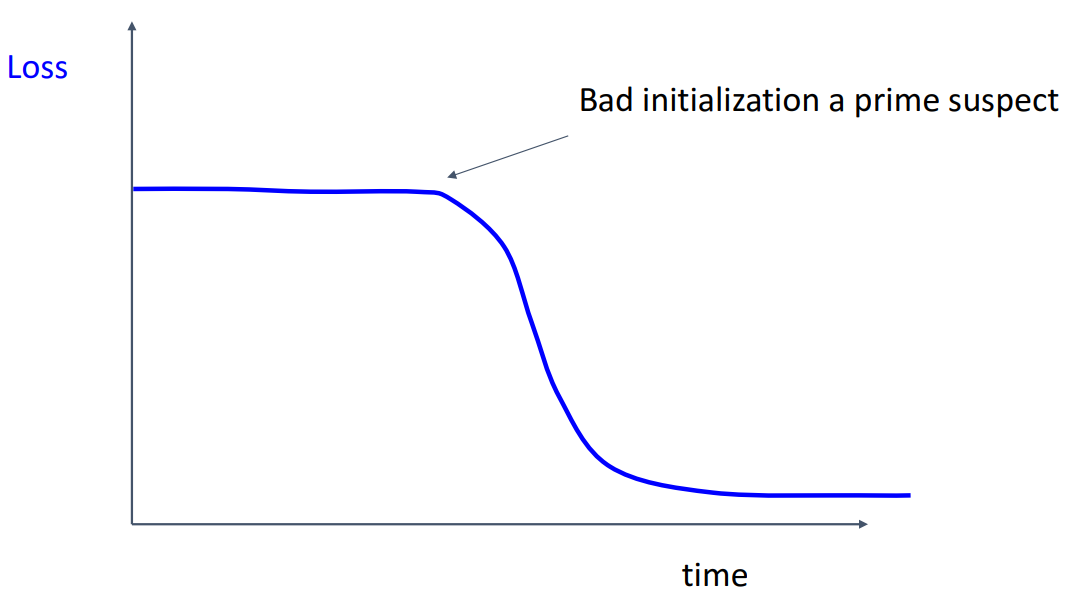
- 초기 가중치가 잘못된 것으로, 적절한 가중치 초기화 방법 적용 필요
- train loss가 감소하지만 최적값에 도달하지 못한 경우
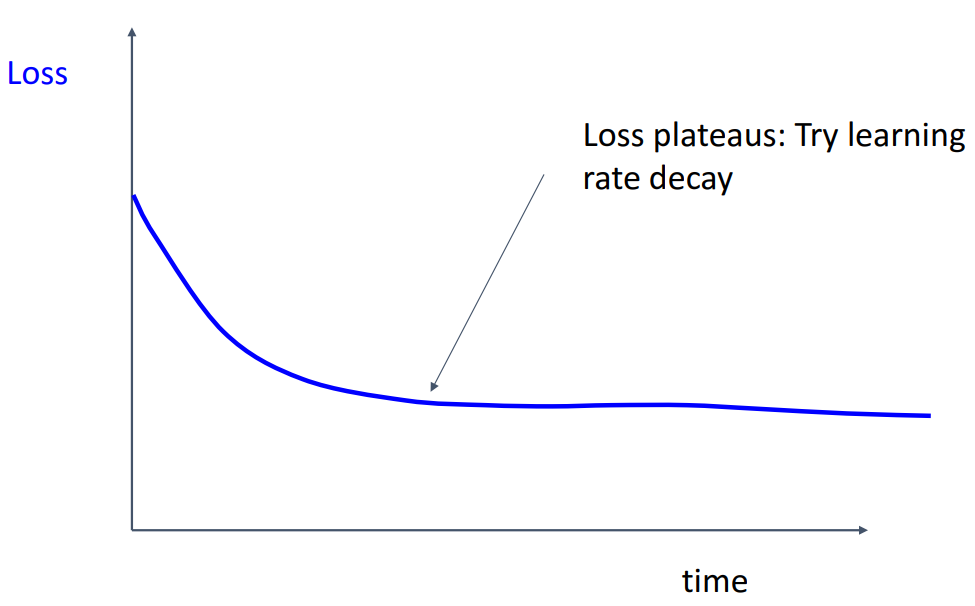
- Learning rate가 너무 높아 최적값에 도달하지 못함
- loss가 초반에 더 떨어질 수 있는 경우
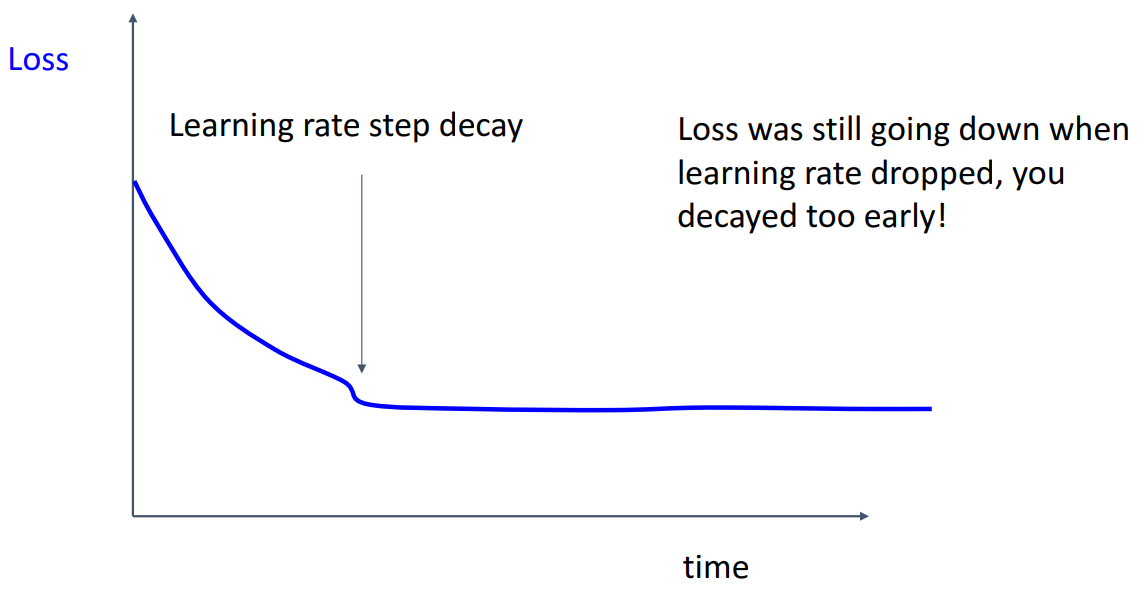
- Learning rate를 너무 빨리 낮추어 loss가 더 떨어지지 않음
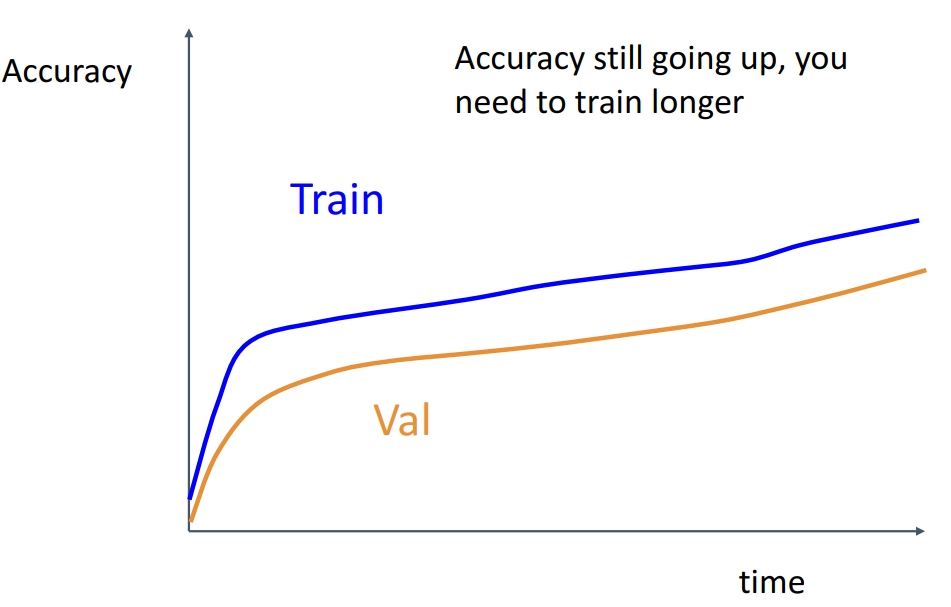
- train과 val의 정확도가 같이 올라가는 경우
- train과 val의 정확도 차이가 많이 나는 경우
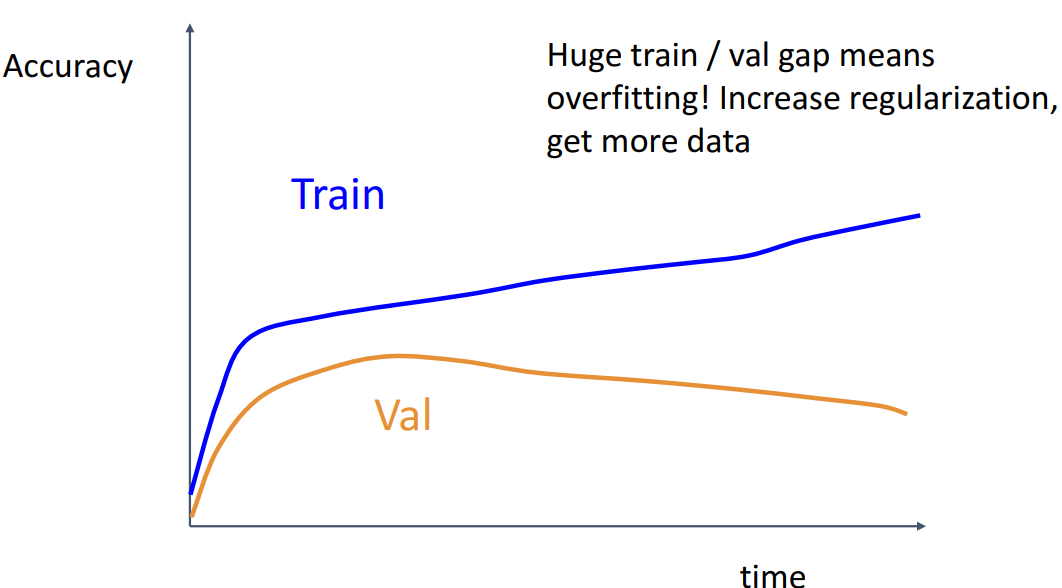
- overfitting이 된 케이스로, 적절한 regularization을 적용하거나 데이터를 추가로 사용해야 함
- train과 val의 정확도 차이가 거의 없는 경우
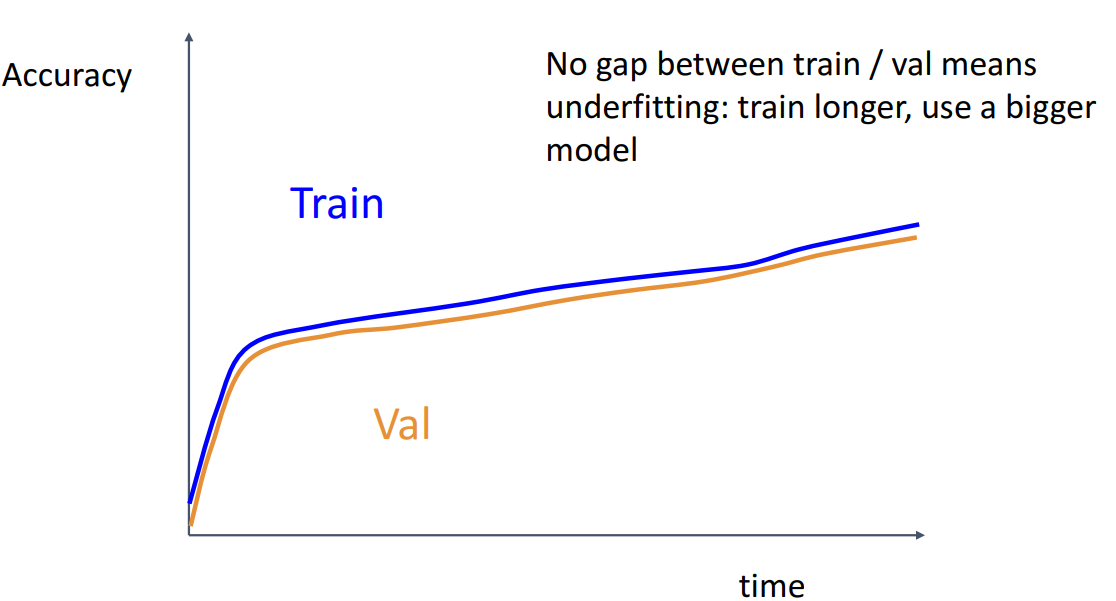
- underfitting이 된 케이스로, 훈련을 더 하거나 더 큰 모델을 사용해야 함
- Step 7. Step 5로 다시 돌아가기
- 계속 조정하며 best model을 찾는 단계
- network architecture, learning rate, decay schedule, update type, regularization 등을 수정
2. After training
1. Model Ensembles
- 개념
- 다양한 independent model을 훈련
- test 시 모든 모델을 사용하여 각 모델의 예측을 평균화
- 앙상블 시, 1~2% 더 나은 결과를 얻을 수 있음
- Tips and Tricks
- Learning rate 활용
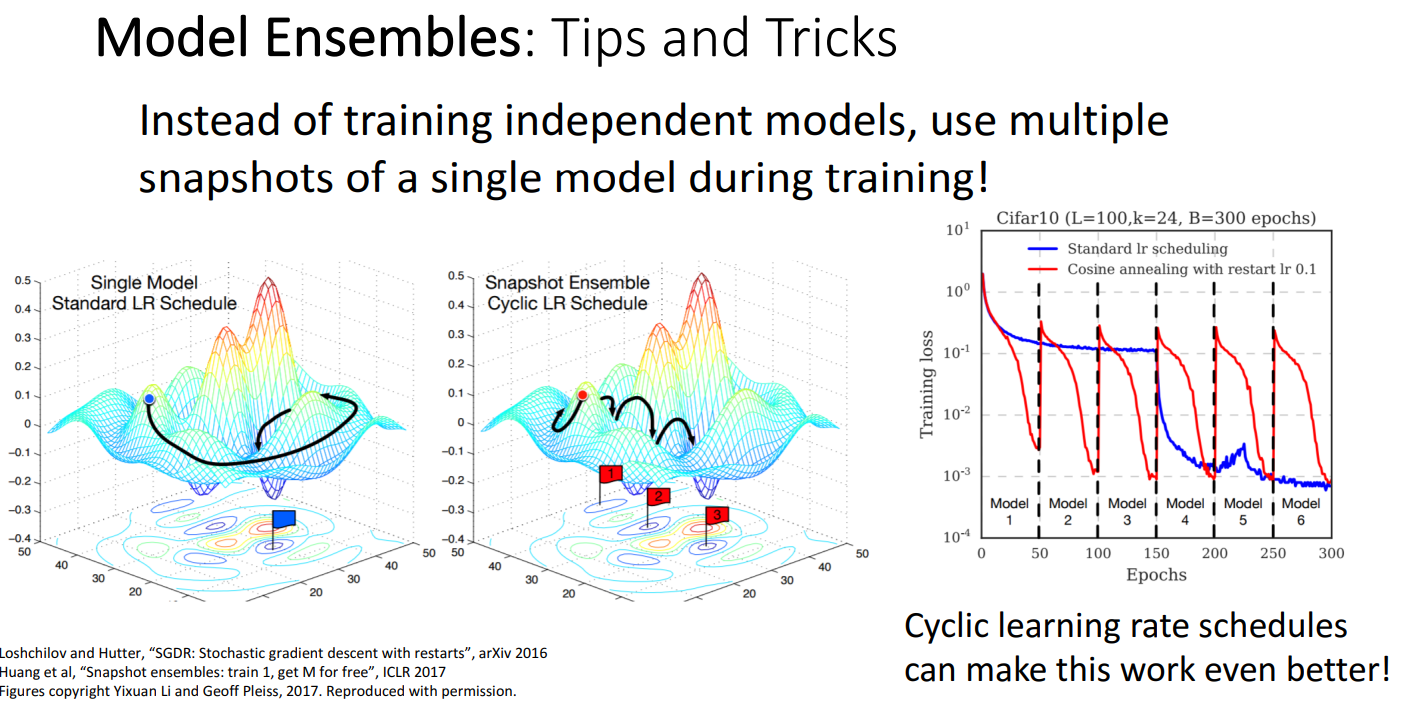
- 여러 개의 독립적인 모델을 학습하는 대신, 단일 모델의 multiple snapshots을 사용
- 특정 시점마다 Learing rate를 높게 설정하여 구간별로 모델의 snapshot을 저장
- 이러한 검사점의 결과를 평균화하여 더 향상된 성능을 얻는 아이디어
- Polyak averaging

- 훈련 이후 가중치를 사용하는 것이 아닌, 훈련 중에 보는 모델 가중치의 실행 평균을 유지하는 것
- Polyak Averaging 을 사용하면, 이전 가중치들의 지수 이동 평균(Exponential Moving Average, EMA)을 유지하면서 테스트 시 이 평균을 사용
2. Transfer Learning
- 아이디어
- CNN을 훈련하거나 사용할 때 많은 데이터가 필요하다는 문제를 해결하기 위해
- 정의
- 이미 학습된 모델을 새로운 작업(task)에 맞게 재사용하는 기법
- Computer Vision 분야에서 널리 사용되는 아이디어
- Transfer Learning with CNNs
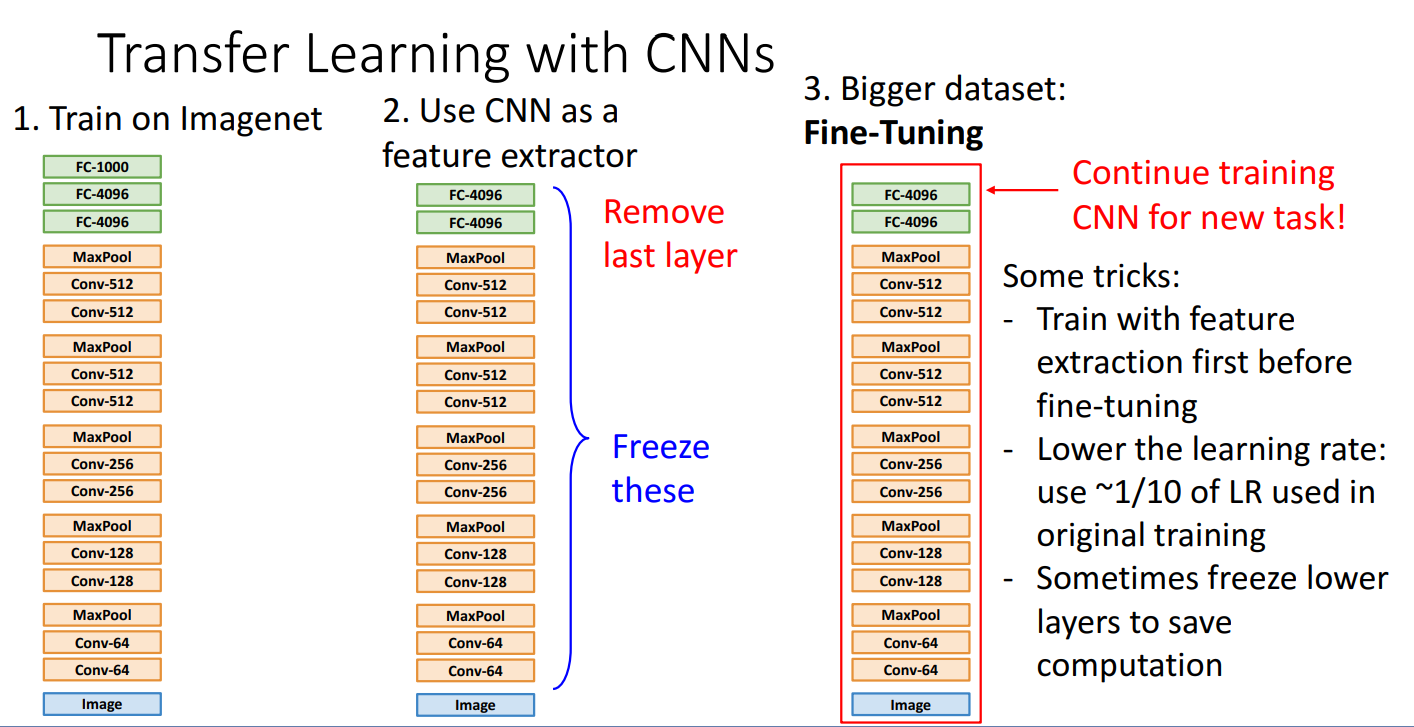
- Step 1. Imagenet과 같은 대규모 데이터로 CNN을 사전 학습
- 이 모델들은 이미 많은 이미지에서 유용한 특징(Edges, Shapes, Patterns 등)을 학습
- Step 2. 학습한 CNN 모델을 feature extarctor로 사용하기
- 마지막 FC layer 삭제하여 클래스 분류기 제거
- Conv layer는 freeze하여 학습되지 않도록 설정
- Step 3. 기존 모델의 출력층(Fully Connected Layer)을 새로운 태스크에 맞게 교체
- Step 4. Fine-tuning 진행
- 학습률(Learning Rate) 조절
- 원래 학습했던 모델보다 학습률(LR)을 1/10 수준으로 낮춤
- 너무 빠른 학습률을 사용하면 기존 가중치가 크게 변해 기존에 학습된 정보를 잃을 위험
- 낮은 레이어는 Freeze 가능
- 일반적으로 CNN의 하위 레이어(초기 Conv 레이어)는 기본적인 특징(Edge, Texture)을 학습
- 따라서 연산량을 줄이기 위해 낮은 레이어를 고정(Freeze) 하는 경우도 있음
- Architecture의 중요성
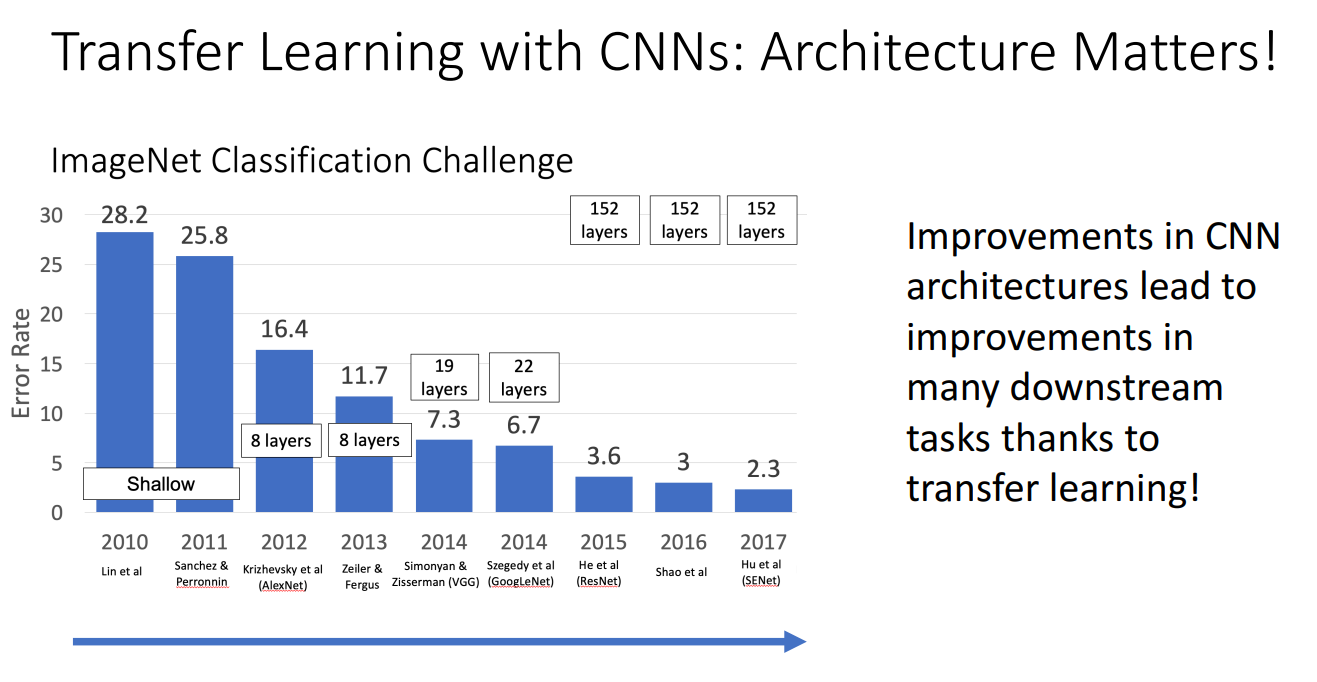
- CNN 구조가 개선될수록 ImageNet 분류 성능이 향상
- 더 깊은 네트워크(더 많은 레이어)를 사용할수록 오류율(Error Rate)이 감소
- 이러한 성능 향상은 전이 학습을 통해 다양한 다운스트림(task)에서도 긍정적인 영향을 미침
- Guide
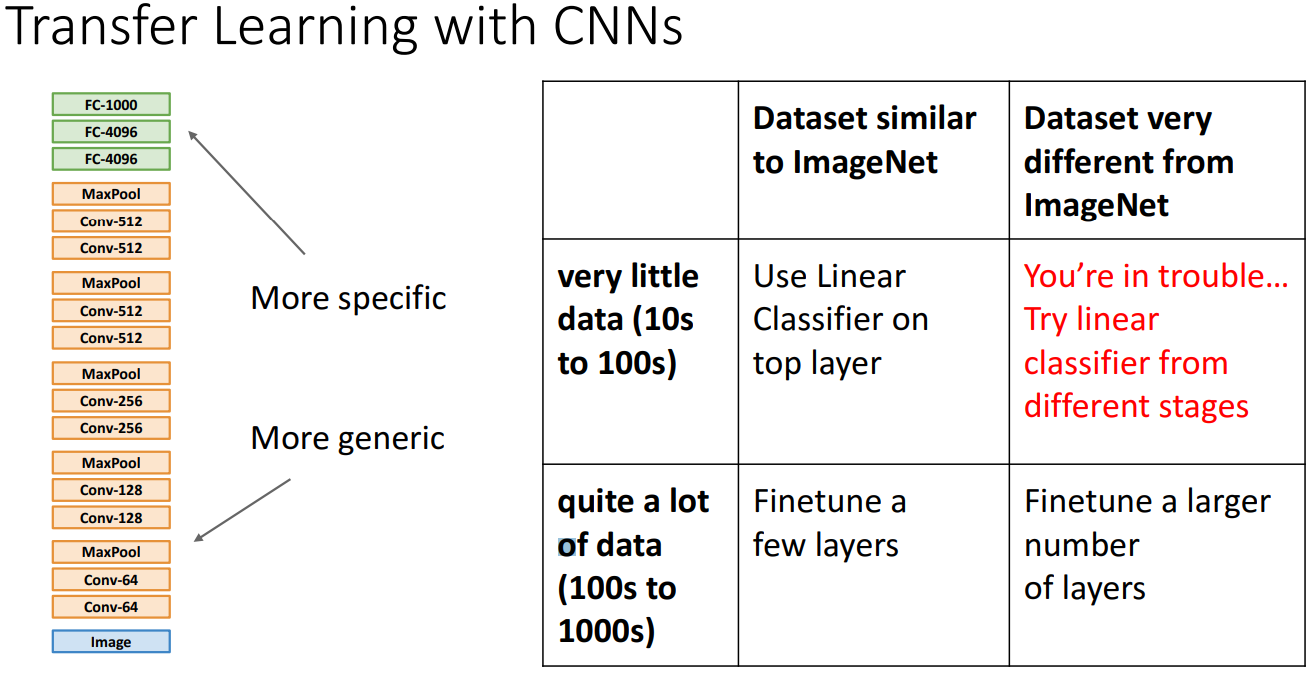
- 적은 데이터, 비슷한 데이터: 가장 윗 layer에 linear classifier 적용
- 적은 데이터, 다른 데이터: 가장 trouble... 여러 단계에 linaer classifer 적용
- 많은 데이터, 비슷한 데이터: 소수의 layer를 미세조정
- 많은 데이터, 다른 데이터: 많은 layer를 미세조정
- 사용 분야
- Object Detection
- Image Captioning
3. Distributed Training
- idea 1

- 레이어 일부를 각각 다른 GPU에 배치하는 방법
- GPU가 레이어 일부만 실행되는 것을 기다리는 데 많은 시간이 소요되어 좋은 아이디어 아님
- idea 2

- 모델을 여러 병렬 분기로 분할한 다음 각각 다른 GPU에서 실행하는 방법
- GPU 간에 동기화(Synchronizing)이 필요하고 GPU 간의 activation과 grad activation의 통신이 가능해야 하는데, 이는 너무 비쌈
- idea 3. Data Parallelism

- n개의 이미지 배치를 가져온 다음 두 GPU 장치 각각에서 모델을 복제하고 실행하는 방법
- GPU가 대부분의 처리를 독립적으로 수행할 수 있으며 GPU 간에 통신할 필요성이 줄어듦
4. Large-Batch Training
- 아이디어
- 하나의 GPU에서 매우 오랜 시간 학습하는 대신에 많은 GPU 세트에서 짧은 시간동안 학습하고자 함
- 방법
- 대표적으로 학습률 조정 방식을 활용

- 장치 수 K일 때 Batch Size가 K배 증가 (데이터 병렬 처리가 진행됨로)
- Batch Size를 K배 증가시키면 Learning Rate도 K배 증가
- Learning rate Warmup
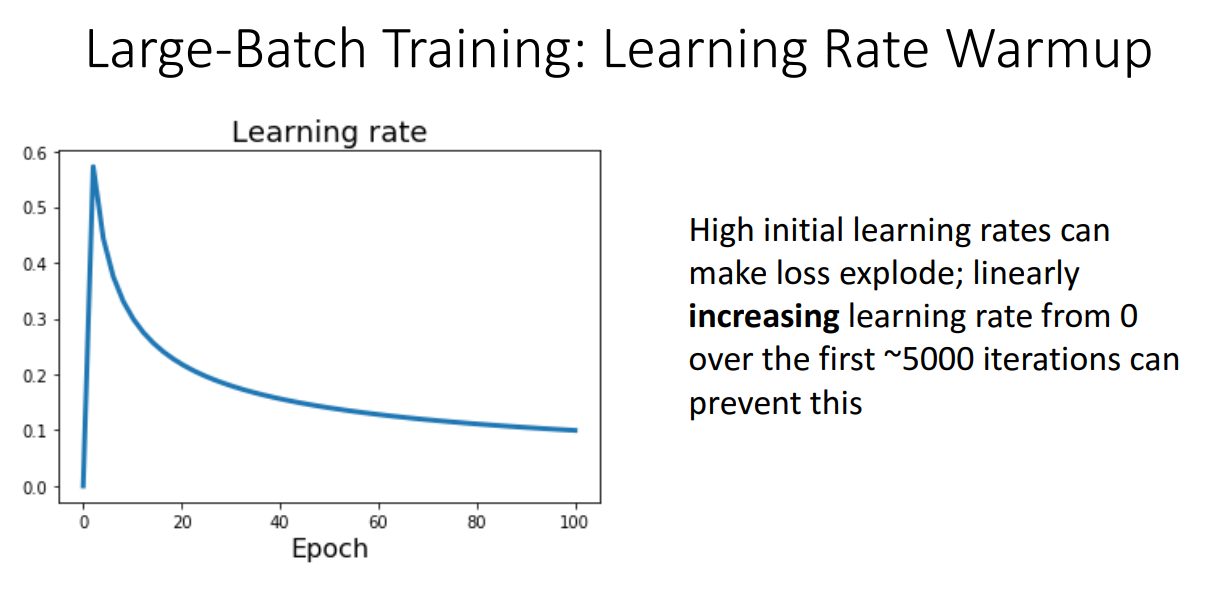
- learning rate를 0에서 시작한 다음 1~5000 반복동안 학습 속도를 점진적으로 증가시켜 loss가 폭발하는 것을 방지
