SPS LAB 2025.02.13 신입생 세미나 4주차
- 본 내용은 Michigan University의 Deep Learning for Computer Vision 12강 Recurrent Networks 강의를 듣고 정리한 내용입니다.
- 강의의 원본은 해당 링크에서 확인하실 수 있습니다.
1. RNN: Process Sequences
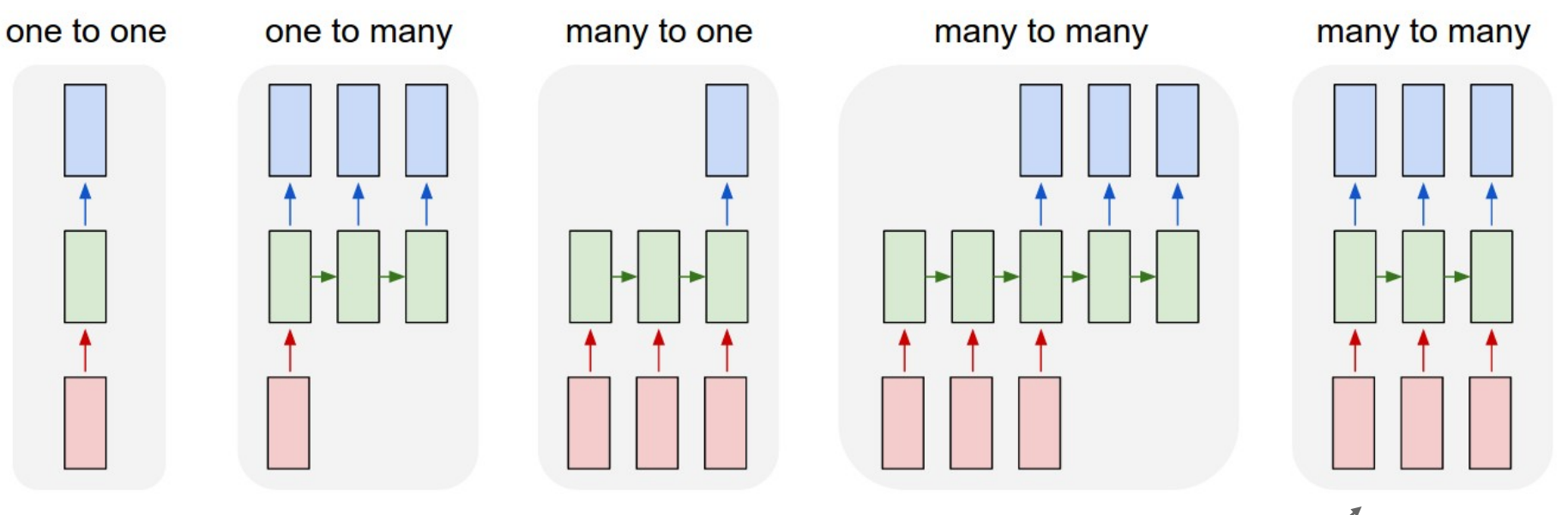
- RNN은 시퀀스 데이터를 처리하는 데 특화된 신경망으로, 입력과 출력의 형식에 따라 다양한 구조가 존재
- One-to-One
- 네트워크 하단에서 단일 입력을 받는 것
- ex) Image Classification (Image → Label)
- One-to-Many
- 하나의 입력을 기반으로 여러 출력을 생성
- ex) Image Captioning (Image → sequence of words)
- Many-to-One
- 여러 개의 입력(시퀀스)을 기반으로 단일 출력을 생성
- ex) Video classification (Sequence of images → Label)
- Many-to-Many (다른 길이)
- 입력 여러 개 → 출력 여러 개 (입력과 출력 길이가 다름)
- ex) Machine Translation (Sequence of words → Sequence of words)
- Many-to-Many (동일 길이)
- 입력 여러 개 → 출력 여러 개 (입력과 출력 길이가 동일)
- ex) Per-frame video classification (Sequence of images → Sequence of labels)
- One-to-One
2. Sequential Processing of Non-Sequential Data
- RNN을 구축하여 비순차적 데이터의 순차적 처리를 수행할 수 있음
- 방법 1

- 단일 피드포워드 신경망이 아닌 이미지를 여러 번 엿볼 수 있는 신경망을 구축
- 이미지의 한 부분을 보고, 다른 부분을 보고 각 시점에서 네트워크가 이미지에서 어디를 볼지에 대한 네트워크의 결정은 이전 모든 단계에서 추출한 정보에 따라 조건이 지정
- 이미지에서 많은 'glimpses'를 한 후 보고 있는 개체가 무엇인지에 대한 분류 결정을 진행
- 단일 피드포워드 신경망이 아닌 이미지를 여러 번 엿볼 수 있는 신경망을 구축
- 방법 2

- 숫자 이미지를 생성할 수 있는 신경망을 구축
- 한 번에 한 단계씩 출력 캔버스의 작은 시퀀스를 그리는 것
- 각 시점에서 신경망은 쓰고 싶은 위치와 쓰고 싶은 내용을 선택한 다음 시간이 지남에 따라 이러한 쓰기 결정이 통합되어 네트워크가 기본 작업이 순차적이지 않더라도 일종의 순차적인 처리를 사용하여 출력 이미지를 생성
- 숫자 이미지를 생성할 수 있는 신경망을 구축
- 방법 1
3. Recurrent Neural Networks
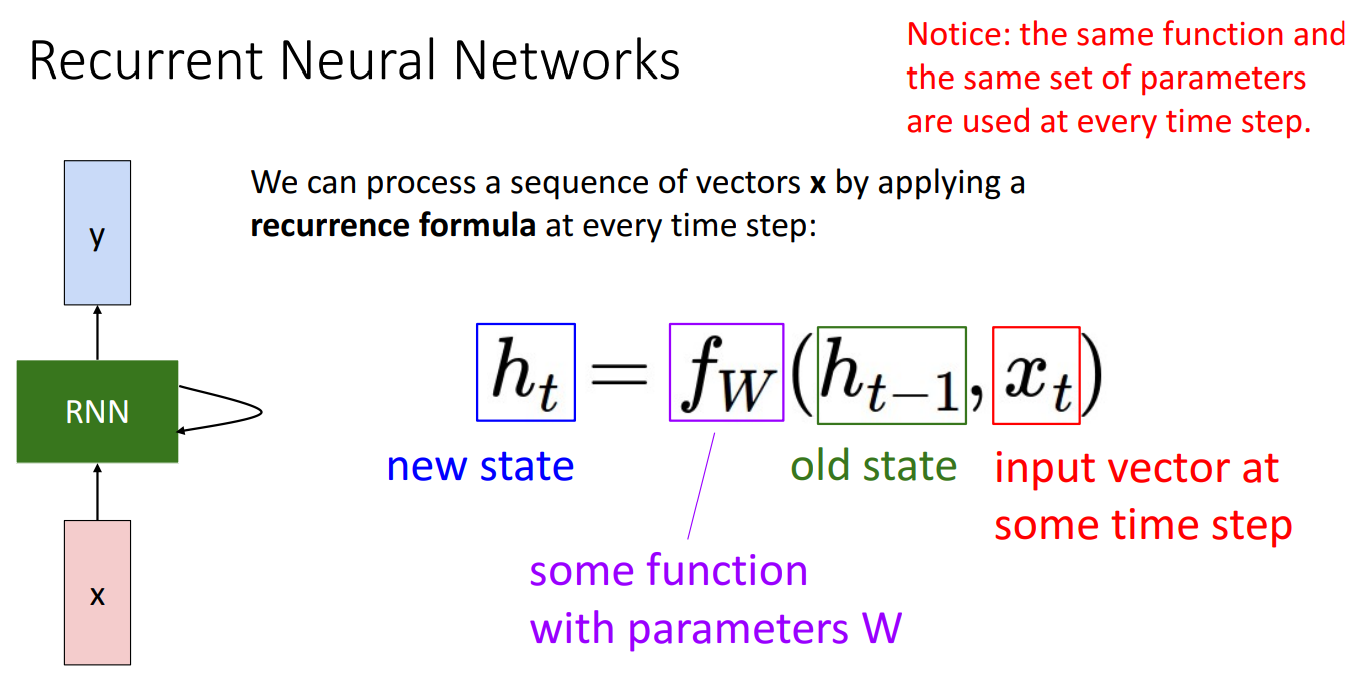
- 기본적으로 RNN은 시퀀스를 처리하고 있으므로 매 시간 단계마다 빨간색으로 표시된 일부 입력 행위를 수신하고 파란색으로 표시된 일부 출력을 방출
- 일종의 벡터인 hidden state를 갖게 되고 모든 시간 단계에서 해당 네트워크의 작업자는 시간의 입력을 사용하여 일종의 업데이트 공식을 사용하여 hidden state를 업데이트
- 업데이트된 hidden state 와 가 제공되면 현재 시간 단계에 대한 출력 가 방출
- 시퀀스의 모든 시간 단계에서 동일한 가중치 W를 사용하는 함수 를 사용
(Vanilla) Recurrent Neural Networks

RNN Computational Graph
순환 신경망을 구축할 때 만드는 계산 그래프에 대해 생각해보기
- 기본 계산 방법
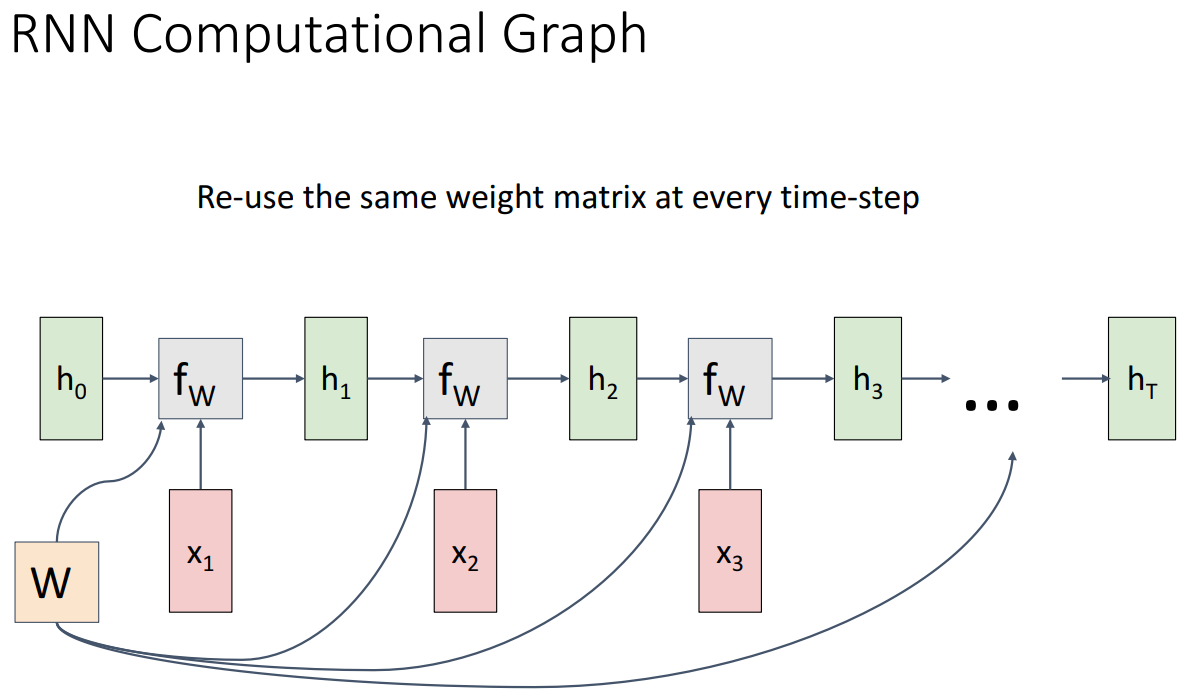
- 첫번째 hidden state인 를 0으로 초기화하는 것이 매우 일반적, 아니면 학습하는 방법도 있음
- 와 이 주어지면 hidden state 을 출력하는 재귀 관계 함수인 에 공급하고, 이를 반복하여 계속 다음 hidden state를 생성
- 여기서 중요한 점은 시퀀스의 모든 시간 단계에서 정확히 동일한 가중치 행렬을 사용한다는 것
- Many to Many
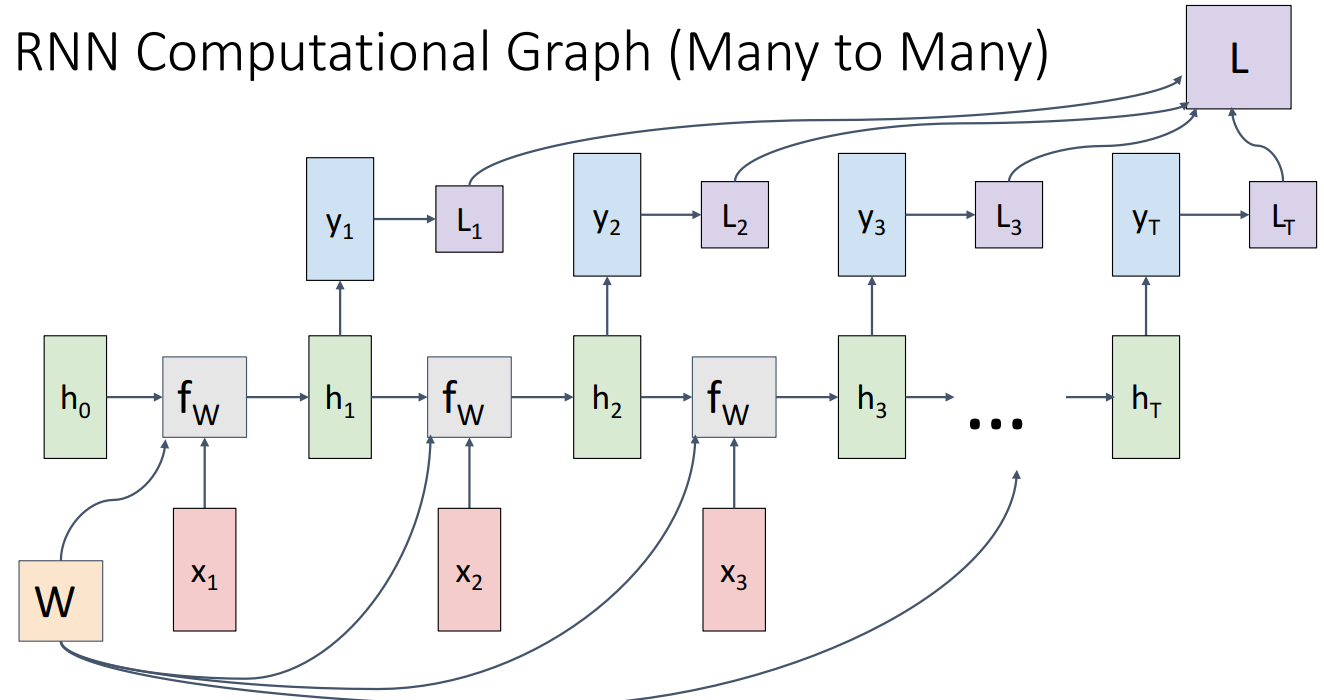
- 입력 시퀀스를 수신하고 시퀀스의 각 지점에 대한 결정을 내리는 것
- 시퀀스의 각 시간 단계에서 예측에 손실 함수를 적용하여 최종 손실 함수를 얻어 이를 통해 역전파 진행
- Many to One
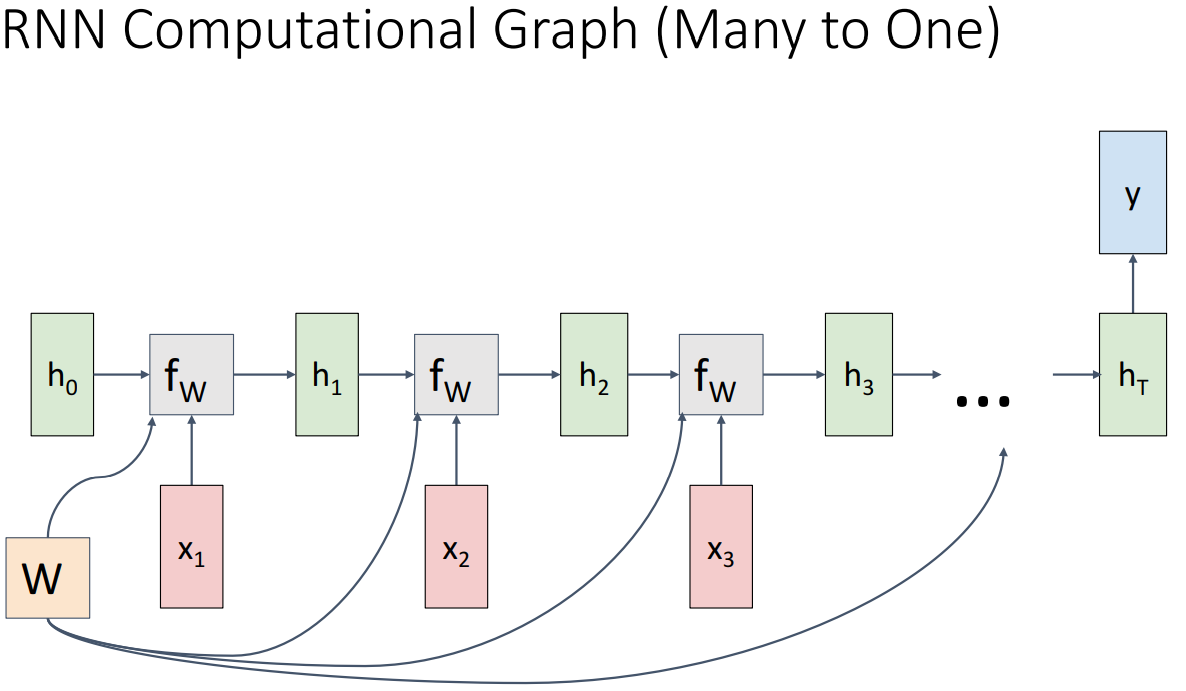
- 전체 시퀀스에 대한 단일 분류 레이블만 생성하려는 경우
- 순환 신경망의 최종 hidden state에서만 작동하는 시퀀스의 맨 끝에서 단일 예측을 만들 수 있음
- One to Many
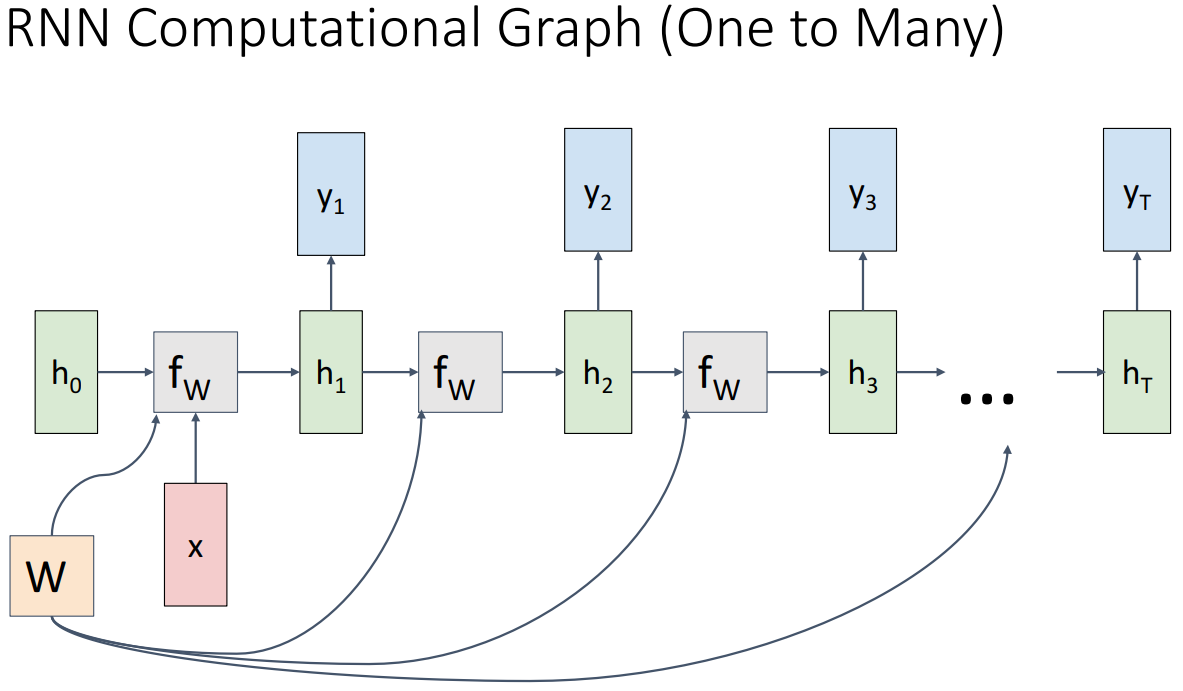
- 이미지와 같은 단일 요소를 입력한 다음 이미지를 설명하는 단어 시퀀스와 같은 요소 시퀀스를 출력하려는 경우
- Sequence to Sequence (seq2seq)
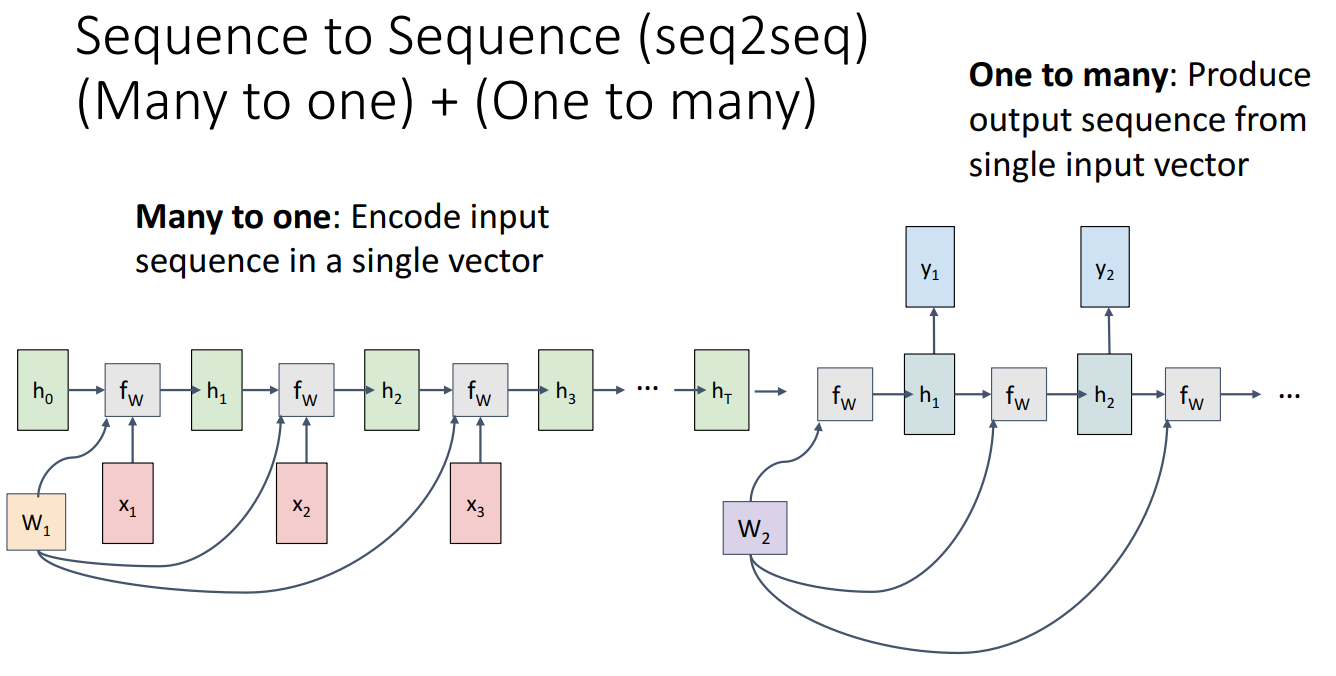
- Many to One + One to Many
- Encoder라고 하는 하나의 순환 신경망이 입력 시퀀스를 수신하고(Many to One) 이후 인코더 시퀀스의 끝에서 hidden vector를 가져와 Decoder라고 하는 두 번째 순환 신경망에 단일 입력으로 공급하여 출력으로 가변적인 시퀀스를 생성 (One to Many)
- Machine Translation에 주로 사용되며, 한 입력 시퀀스를 처리한 다음 길이가 다를 수 있는 시퀀스를 생성
- 영어로 된 단어 시퀀스를 입력한 다음 프랑스어로 된 단어 시퀀스를 출력하여 문장의 번역을 제공하는 것을 예시로 들 수 있음
4. Example: Language Modeling
주어진 문자 시퀀스를 입력받아, 다음 문자를 예측하는 언어 모델 예제
- Training Time
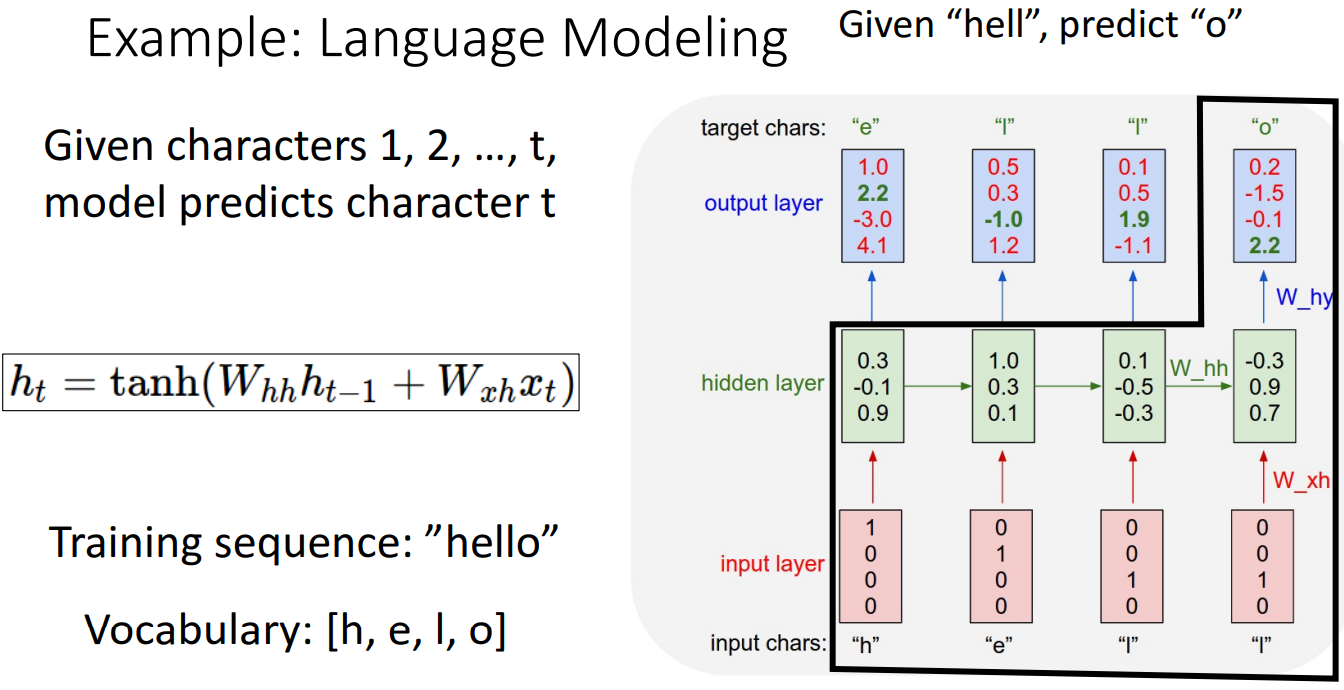
- 'hello' 각 문자를 one-hot vector로 변환하여 입력 시퀀스를 처리
- 순환 신경망을 사용하여 입력 벡터 시퀀스를 처리하고 이 hidden state 시퀀스를 생성할 수 있음
- 모든 시간 단계에서 시퀀스의 다음 요소가 올 확률을 예측한 출력 행렬이 결과로 나옴
- Test Time
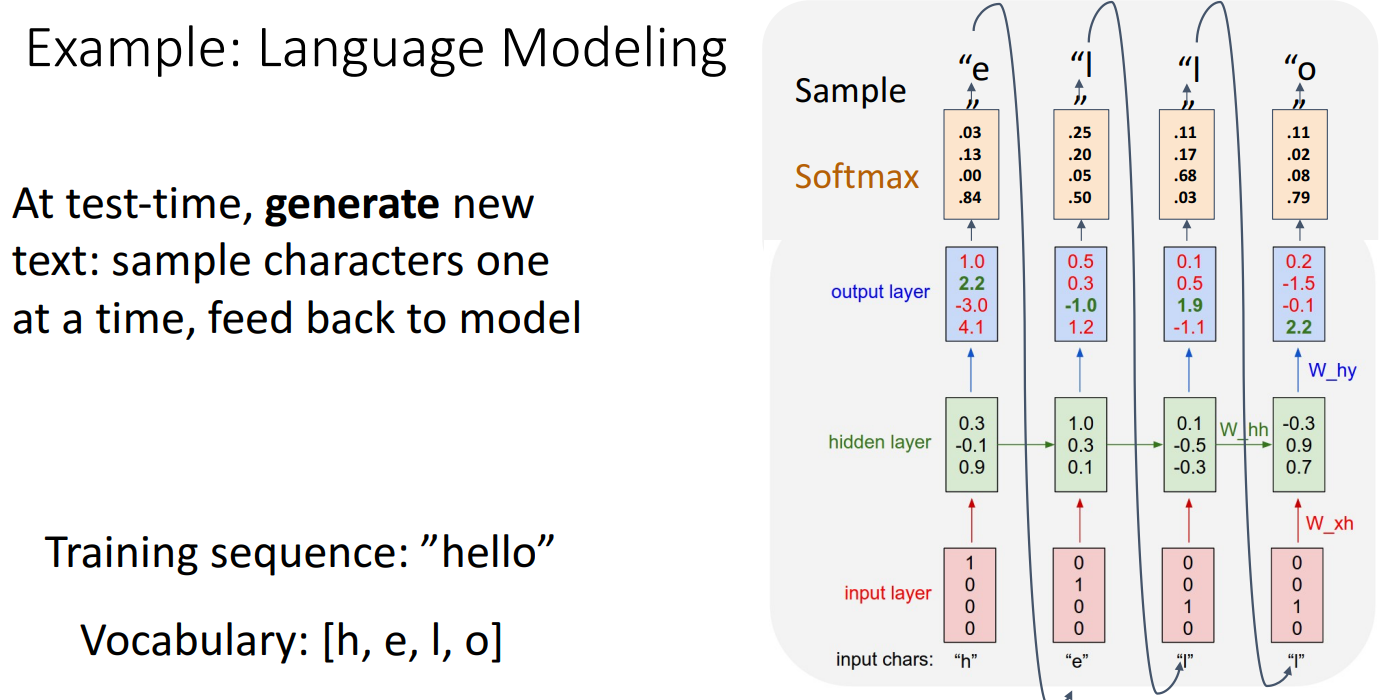
- 훈련된 언어 모델이 주어지면 초기 시드 토큰 'h'를 공급하여 새 텍스트를 생성하도록 함
- 입력 토큰 h를 원핫 인코딩한 벡터를 제공하고 다음 문자에 대한 예측 분포를 얻고, 가장 확률이 높아 샘플링된 출력을 가져와 네트워크의 다음 시간 단계에서 입력으로 다시 공급하며 이 프로세스를 계속 반복함
- 수식을 보면 one-hot vector를 가중치 행렬과 곱하면 특정 열(column)을 선택하는 효과가 있음. 실제로 행렬 곱셈 루틴으로 그것을 구현할 필요 없이 효율적으로 처리하기 위해 Embedding Layer를 삽입하여 처리할 수 있음
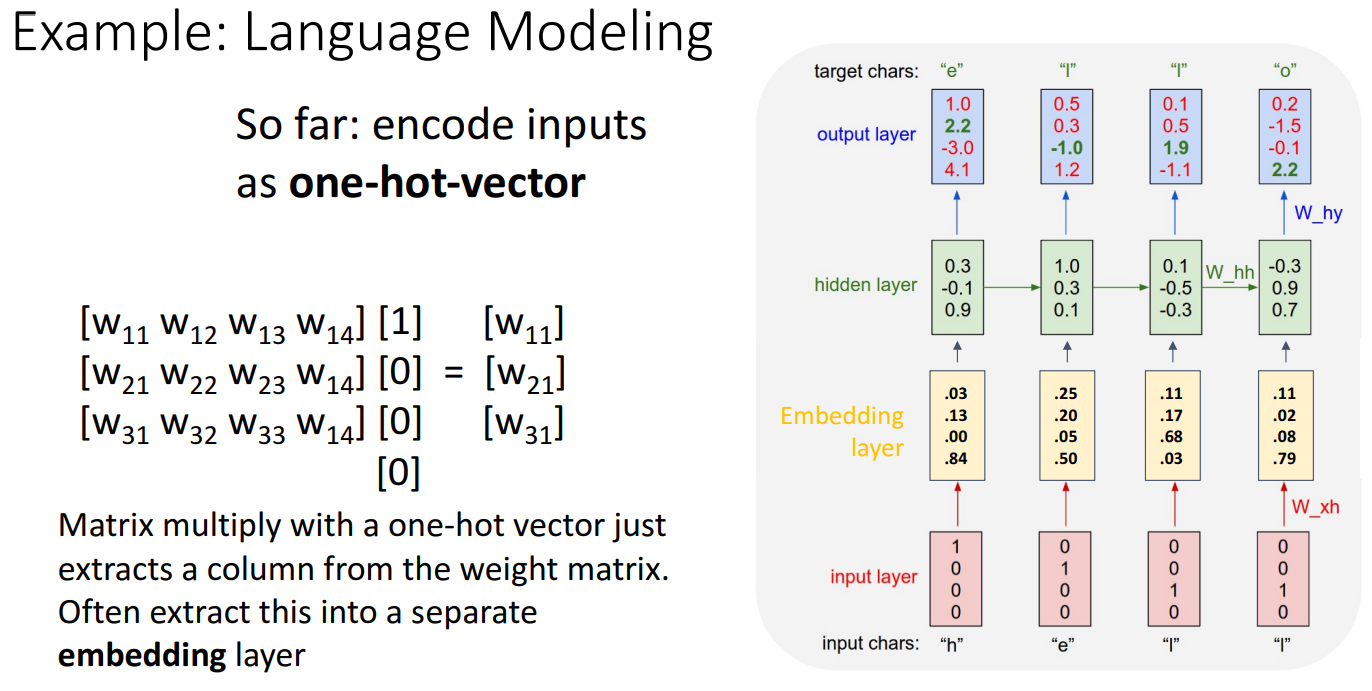
- Embedding Layer는 학습 가능한 Dense vector로 변환하는 레이어로, 예를 들어 'h', 'e', 'l', 'o' 각각을 저차원의 연속된 벡터로 변환할 수 있음
- 원-핫 벡터보다 더 작은 차원(dimension)을 사용하여 효율적
- 단어 간 유사성을 학습할 수 있음
5. Backpropagation Through Time
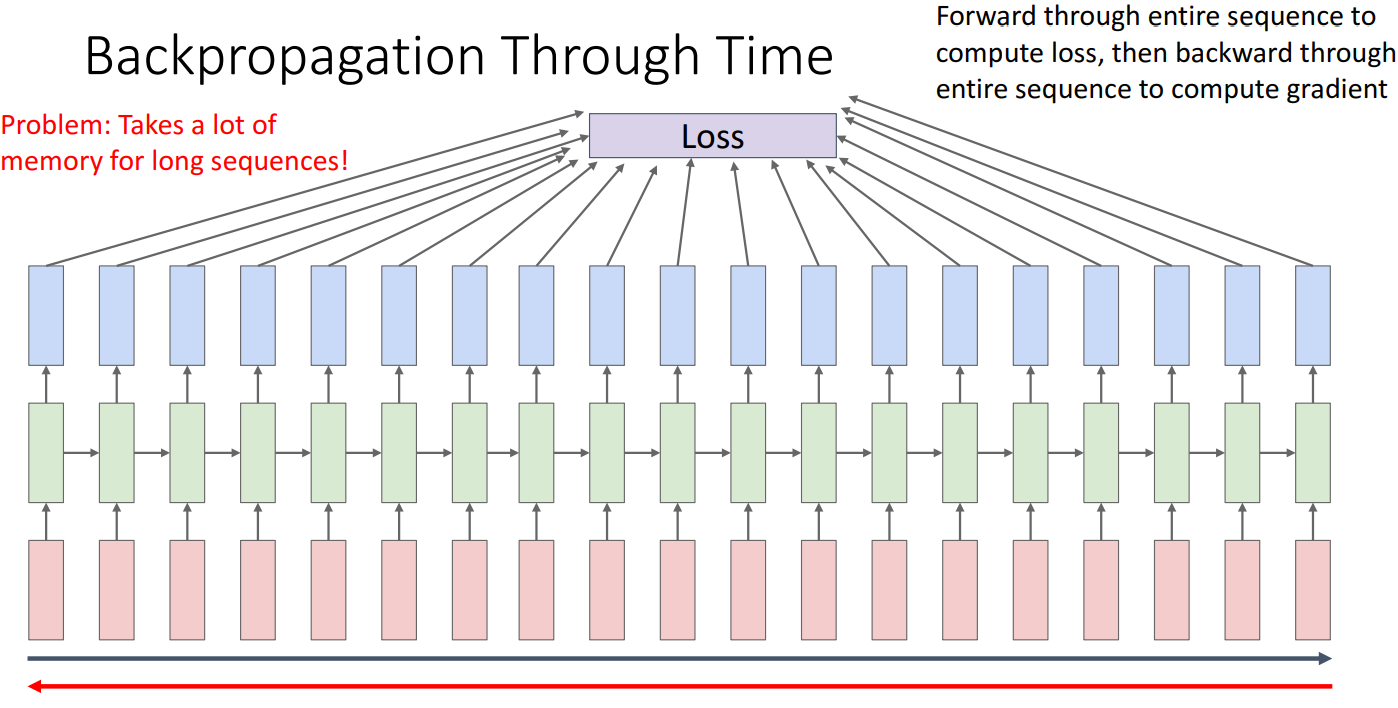
- 일반적인 신경망처럼 단순한 역전파(Backpropagation)가 아닌, 시간 축을 따라 역전파(Backpropagation Through Time, BPTT)를 수행.
- Forward Pass: 입력(빨간색 박스)을 순차적으로 처리하여 은닉 상태(녹색 박스)를 업데이트하고, 마지막에 전체 시퀀스에 대한 손실(Loss)을 계산.
- Backward Pass: 손실을 기반으로 시퀀스 전체를 거슬러 올라가며(빨간 화살표) 모든 시점에서 기울기(Gradient)를 계산.
모든 시간 단계에서 가중치를 업데이트.
- 문제점
- RNN은 모든 시간 단계의 은닉 상태를 저장해야 하므로, 시퀀스가 길어질수록 메모리 사용량이 증가
- 해결책
- Truncated Backpropagation Through Time
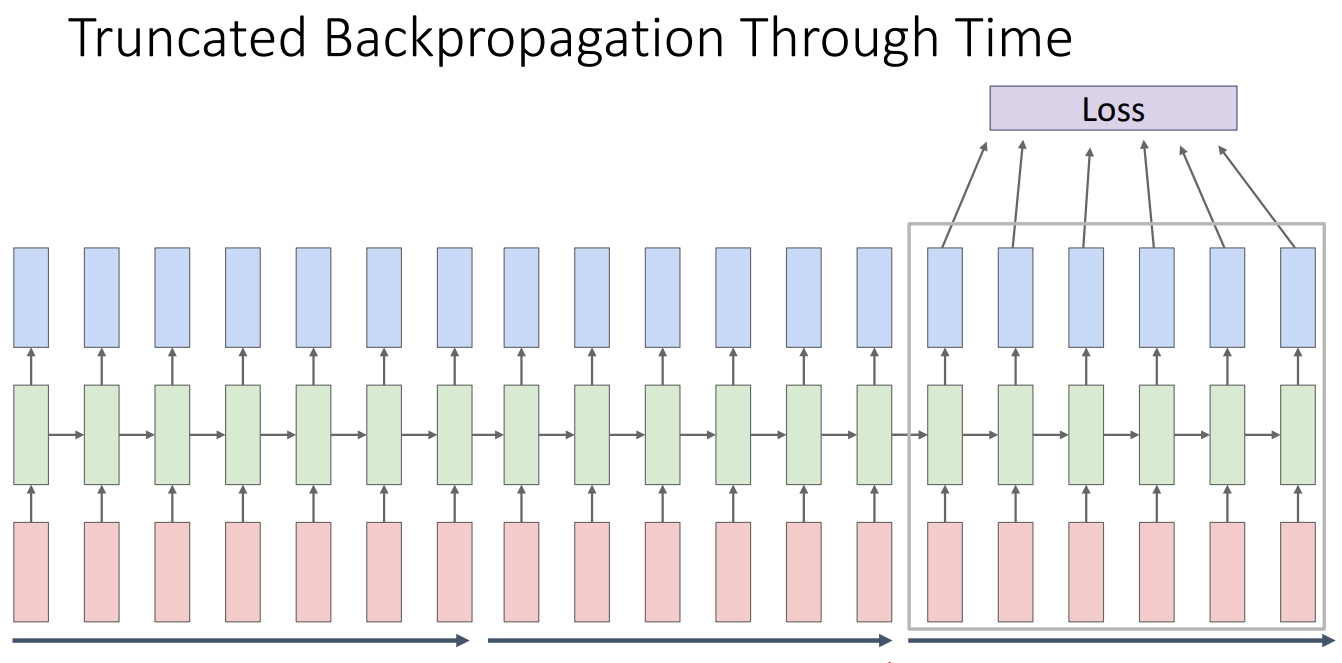
- 아이디어는 네트워크의 전체 무한 시퀀스에서 이 네트워크의 학습을 근사화하고 싶다는 것
- 시퀀스의 일부 하위 집합 chunk를 만들어 입력으로 넣고 손실을 계산한 다음 해당 chunk에 대해서만 역전파 진행. 가중치 행렬을 업데이트하고 이를 받아 시간 순서대로 계속 반복
- Truncated Backpropagation Through Time
6. Searching for Interpreatable Hidden Units
- 아이디어
- 우리가 순환 신경망 언어 모델이 다양한 유형의 시퀀스 데이터 세트에서 훈련할 때 무엇을 학습하는지에 대한 해석 가능성을 얻고자 한 것 (해석 가능한 유닛을 찾는 것)
- 방법론
- 순환 신경망을 가져와 여러 시간 단계동안 펼치고 다음 문자를 예측하는 에측 작업을 수행하는 것.
- 예측하는 과정에서 순환 신경망은 입력의 각 문자에 대해 하나의 hidden sate 시퀀스를 생성한 다음 출력에서 해당 문자를 생성하려고 하고, 이러한 hidden sate의 다른 차원이 무엇을 캡쳐하는지에 대해 알아야 함
- 예시 (hidden state 값을 사용하여 셀이 높은 경우가 빨간색, 낮은 경우가 파란색)
- 무엇을 찾는지 해석하기 어려운 경우

- quote detection cell

- 따옴표로 둘러싸인 문장을 감지하는 은닉 유닛을 시각화
- line length tracking cell

- 줄바꿈이 필요한 시점을 추적 (80글자 이상)
- if statement cell
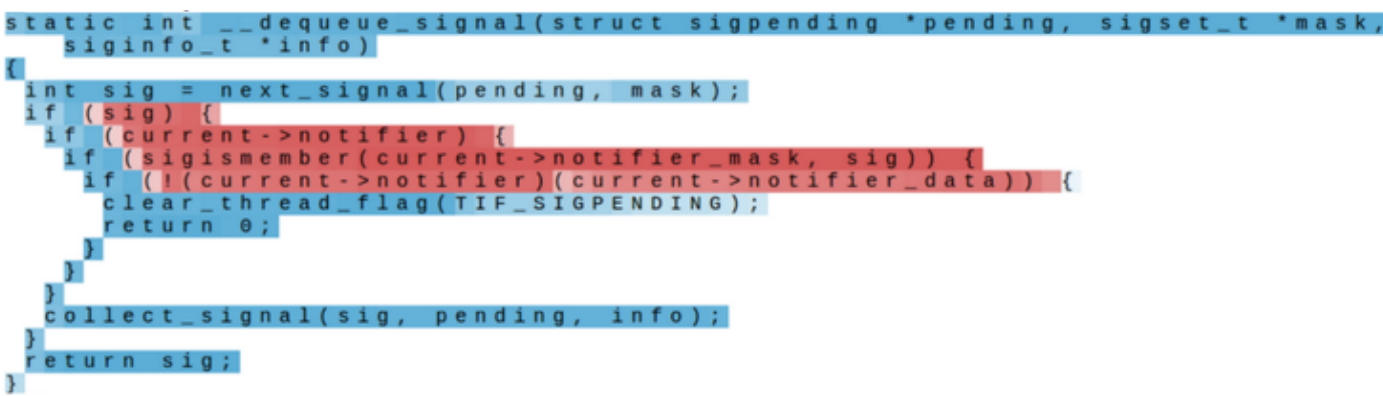
- if 문 내부를 추적
- quote/comment cell

- 주석 안에 있는 여부 확인
- code depth cell

- 코드 내부 들여쓰기 수준을 추적
- 무엇을 찾는지 해석하기 어려운 경우
7. Example: Image Captioning
합성곱 신경망에 이미지를 입력하고 이미지에 대한 기능을 추출한 다음 순환 신경망에 전달하여 이미지의 내용을 설명하는 단어를 생성
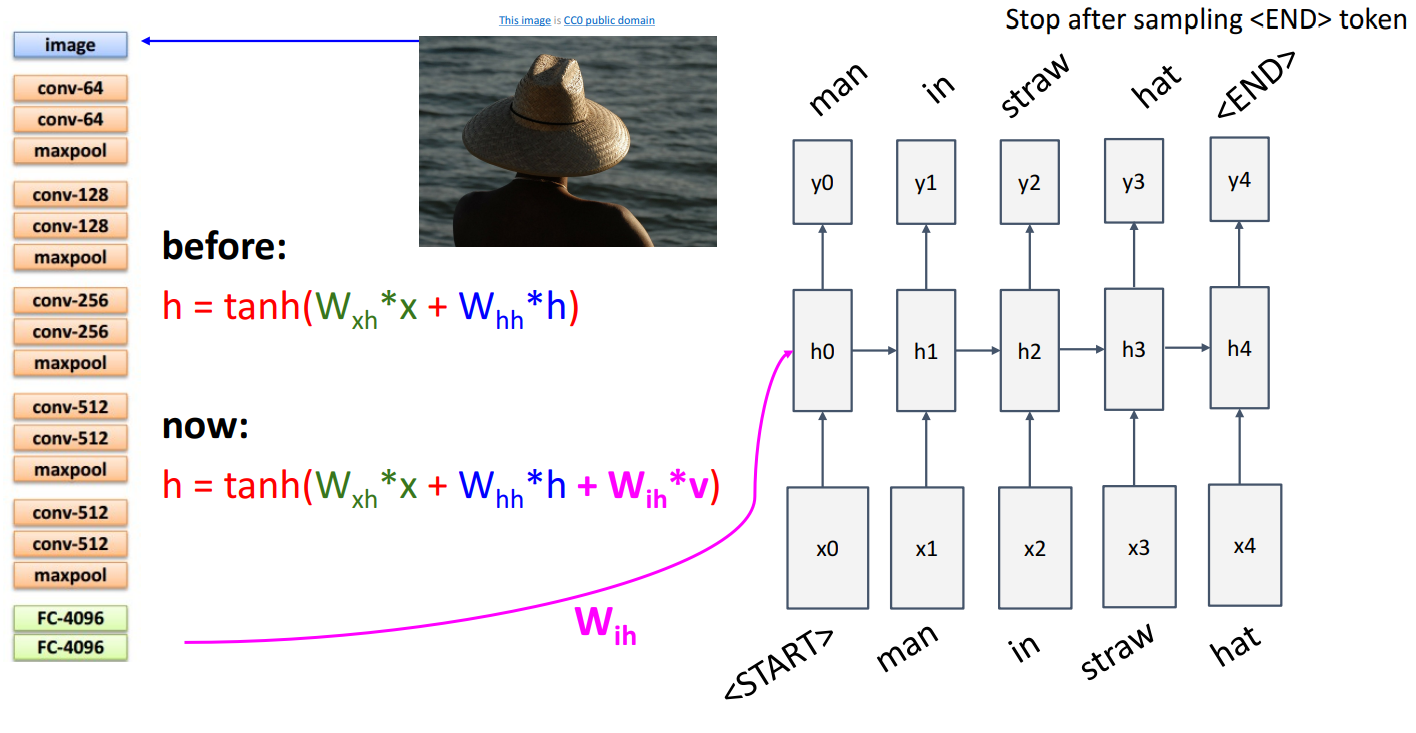
- 단계
- 주어진 이미지를 이미지넷에서 분류를 위해 미리 학습된 CNN 모델에 입력
- 합성 신경망의 상단에서 추출된 정보 를 반영하기 위해 순환 공식에 새로운 가중치 를 추가
- RNN이 CNN의 특징을 기반으로 문장 생성
- 시작 토큰 START> 입력되어 첫번째 hidden state 가 생성
- RNN이 단어를 하나씩 예측하면서 다음 hidden sate를 업데이트
- END 토큰 나올때까지 반복
- 성공 사례

- 실패 사례

8. Vanilla RNN Gradient Flow
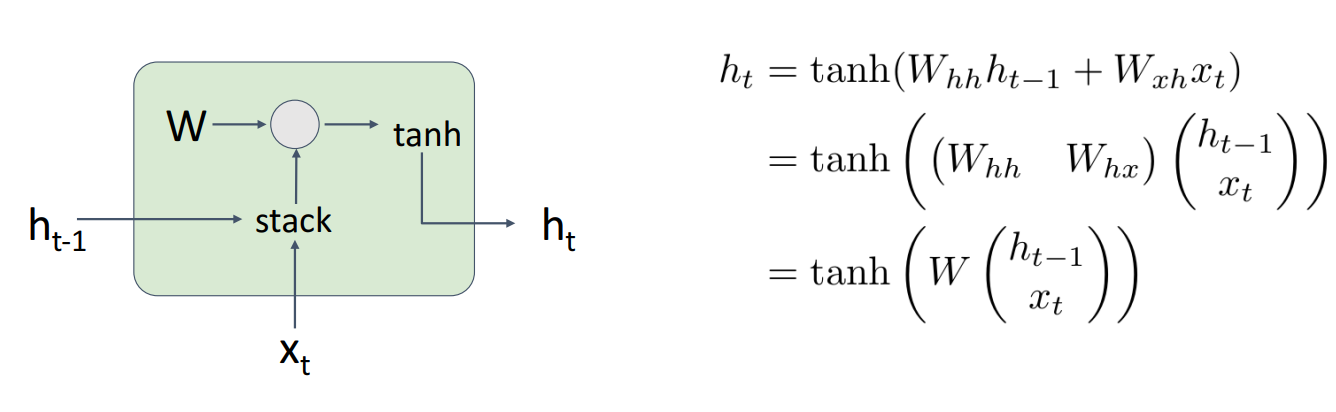
- 입력과 hidden state를 stack하고, 하나의 행렬 를 곱함
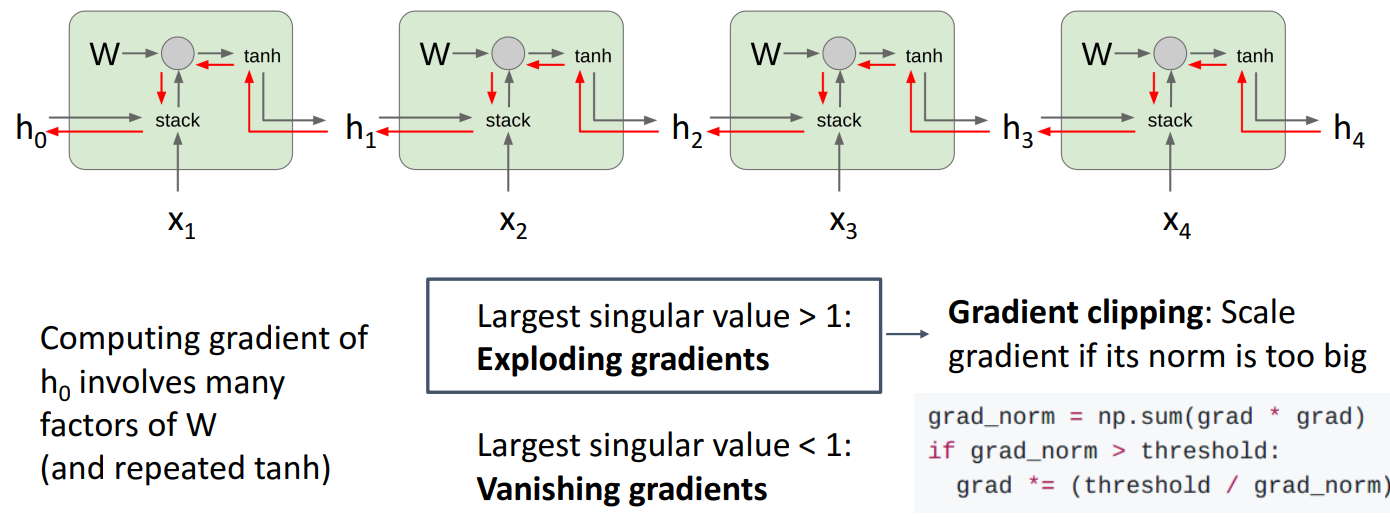
- gradient가 전체 시퀀스를 통해 역방향으로 흐를 때 가중치 행렬 전치행렬로 Upstream gradient에 계속 곱해지게 됨
- Largest singular value > 1: Exploding gradient, 그래디언트 폭발
- 해결책으로 grad_norm을 확인해서 일정 threshold를 넘으면 스케일을 조정하는 Gradient clipping 방법 있음
- Largest singular value < 1: Vanishing gradient, 그래디언트 소멸
- 해결책으로 RNN architecture를 LSTM으로 변경
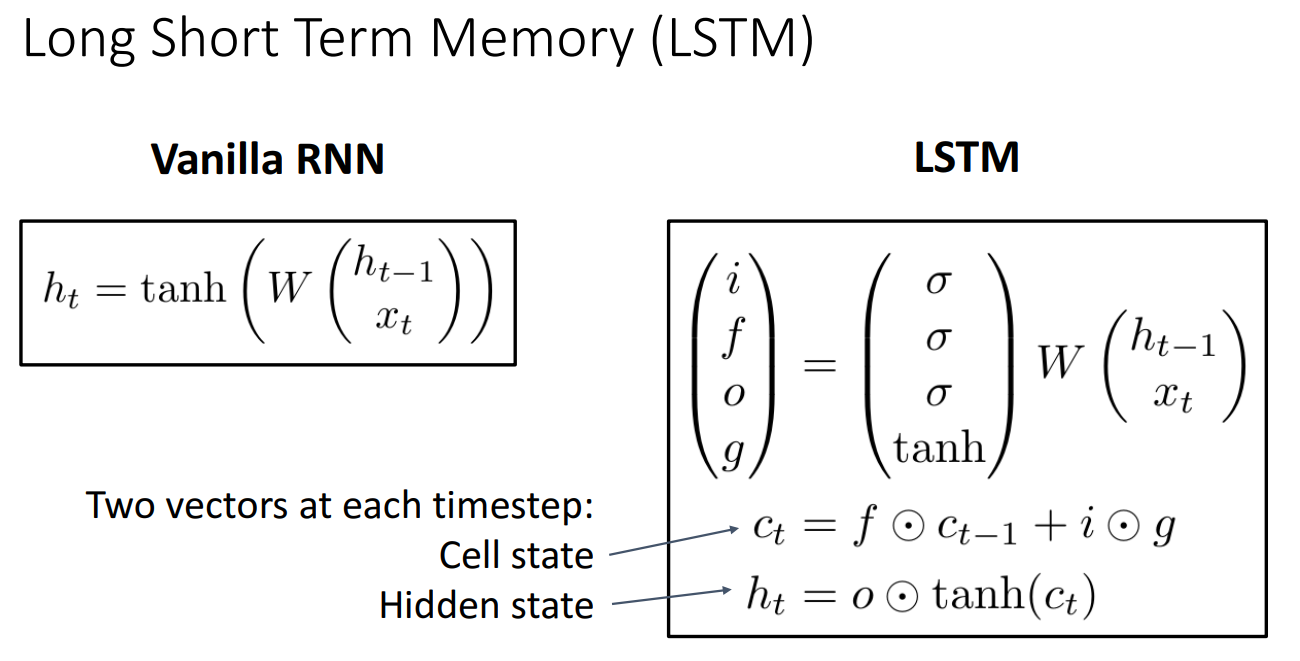
9. Long Short Term Memory (LSTM)
- Largest singular value > 1: Exploding gradient, 그래디언트 폭발
- 기본 아이디어는 모든 시간 단계에서 단일 hidden state를 유지하는 대신 2개의 다른 hidden vector를 유지하는 것
- 하나는 cell state인 , 다른 하나는 hidden state인
- 모든 시간 단계에서 이전 hidden state와 현재 input을 사용하여 다른 gate value 를 게산하고 이를 사용하여 업데이트된 cell state를 계산하고 업데이트되지 않은 hidden state를 계산하는 데 사용
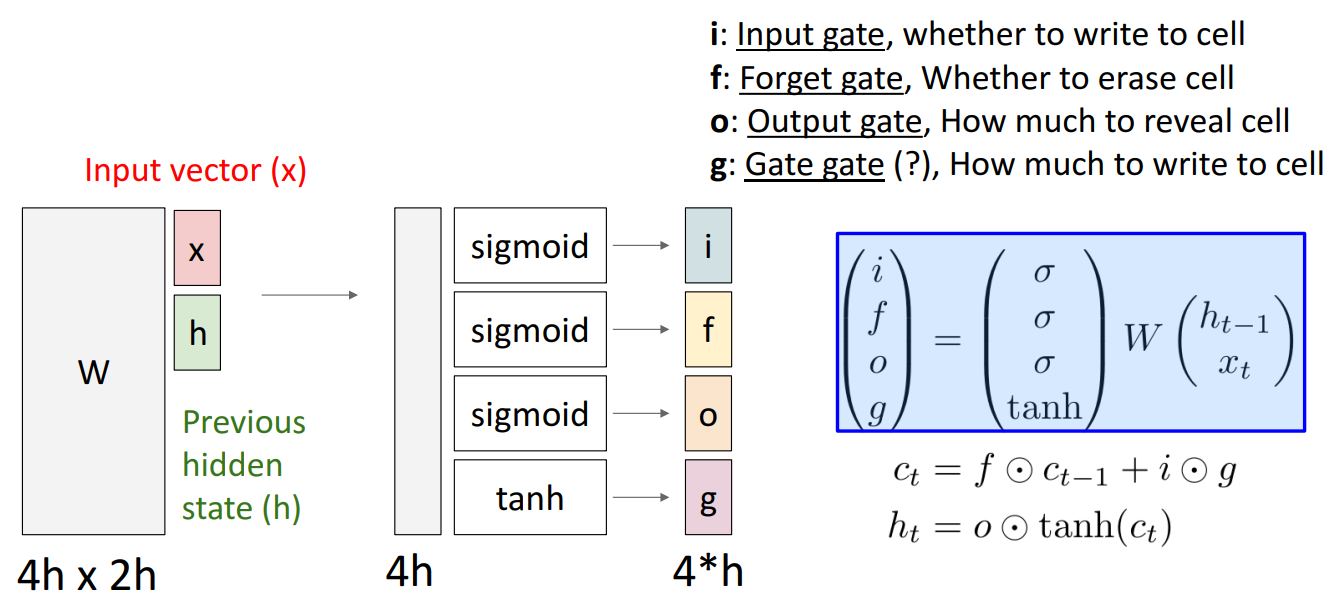
- 입력 벡터 와 이전 hidden state인 를 입력으로 받고, 이 두 개의 입력은 가중치 행렬 와 함께 처리
- 4개의 게이트를 생성하여 cell state와 hidden state를 업데이트
- Input gate : 현재 입력 를 얼마나 셀 상태 에 반영할지 결정
- Forget gate : 이전 셀 상태 의 정보를 얼마나 유지할지 결정
- Output gate : 새로운 hidden state 를 얼마나 활성화할지 결정
- Gate gate : 새로운 정보를 얼마나 반영할지 결정
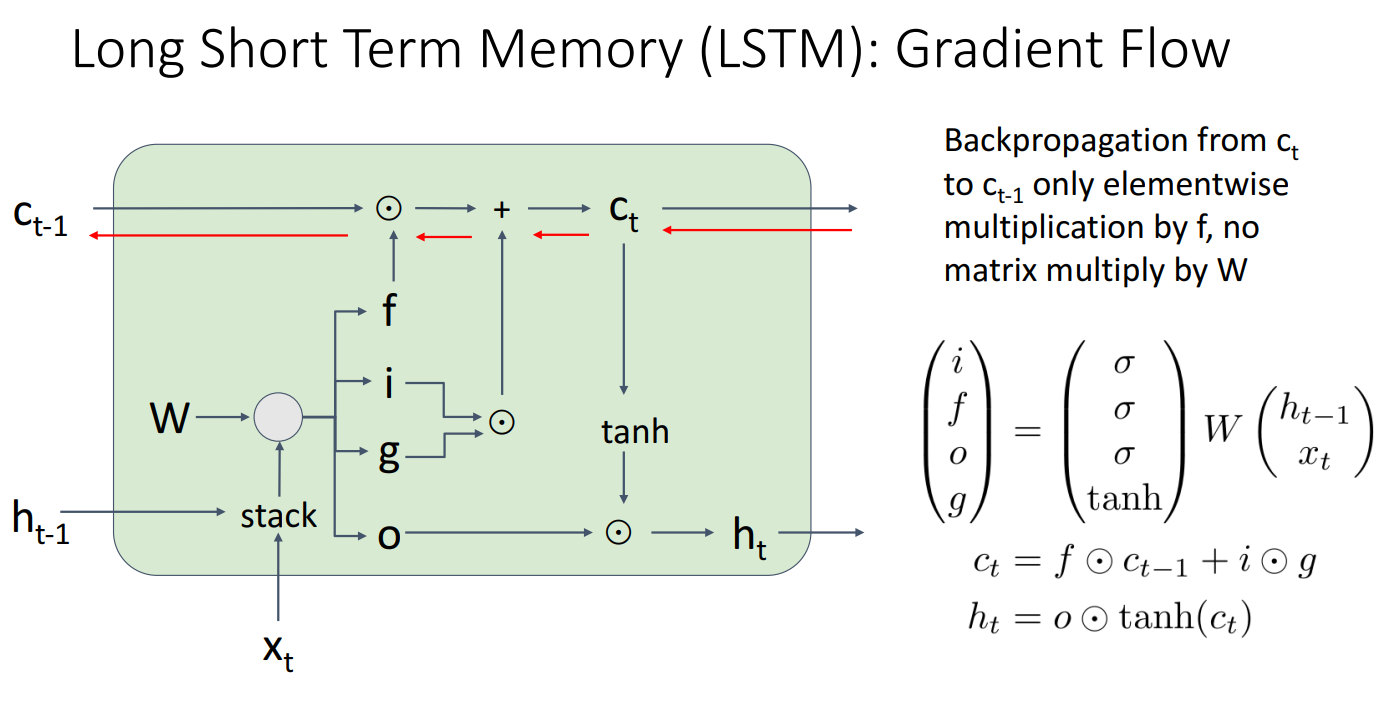
- 일반적인 RNN은 행렬 W 의 반복적인 곱셈으로 인해 그래디언트가 폭발(Exploding Gradient)하거나 소실(Vanishing Gradient)하는 문제가 발생
- 하지만, LSTM은 셀 상태 를 유지하기 때문에 그래디언트가 직접 이전 상태 로 전달
- 즉, 그래디언트가 단순히 (Forget Gate)와 element-wise 곱셈만 수행하며 흐르기 때문에, 행렬 와의 곱셈 없이 전달
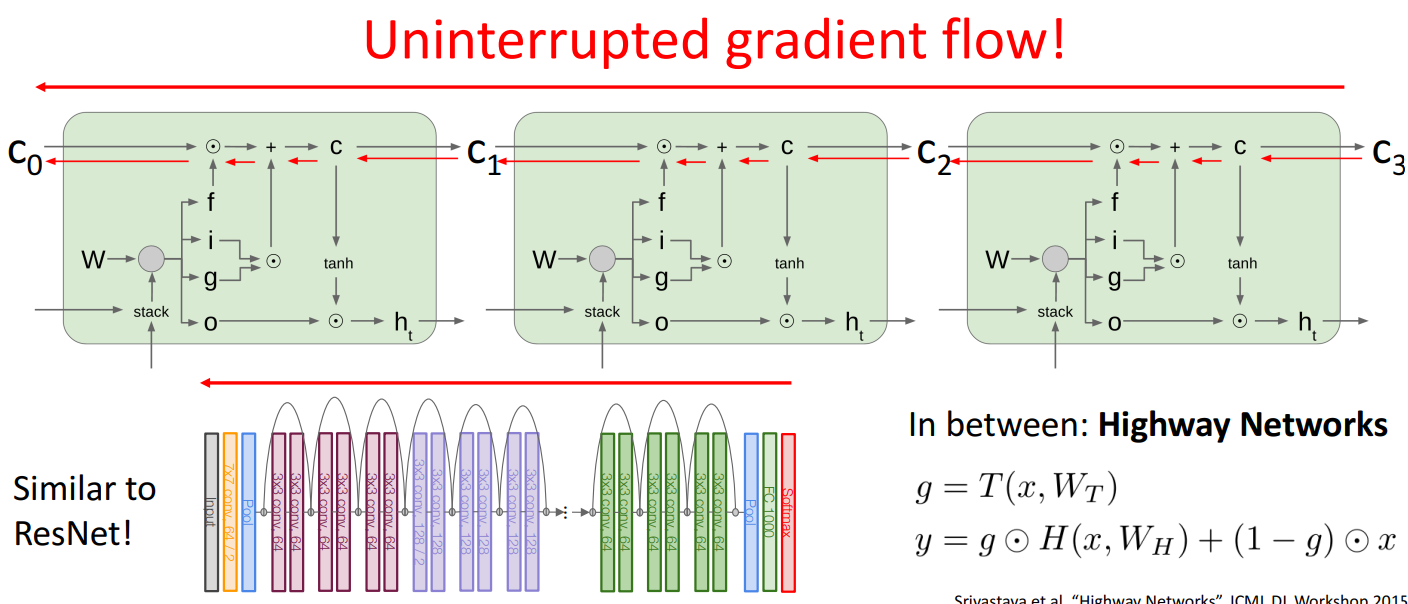
- backpropagation 시에도 는 로 직접 그래디언트가 전달되므로 소실되지 않아 이미지에서 빨간색 화살표로 표시된 경로처럼 Uninterrupted gradient flow (끊김 없는 그래디언트 흐름)을 가짐
- LSTM과 ResNet 둘 다 그래디언트 흐름을 유지하는 구조를 갖고 있음
- ResNet(Residual Networks)도 입력값 x 가 그대로 출력에 전달되는 구조를 가지고 있음
- Highway Networks는 Residual Connection (잔차 연결)을 통해 RNN처럼 여러 레이어를 쌓아도 그래디언트가 사라지지 않도록 설계됨
- 여기서 g 는 게이트 값(일종의 필터)로, 일부 정보는 그대로 전달하고 일부 정보는 변형하여 유지하는 역할을 함
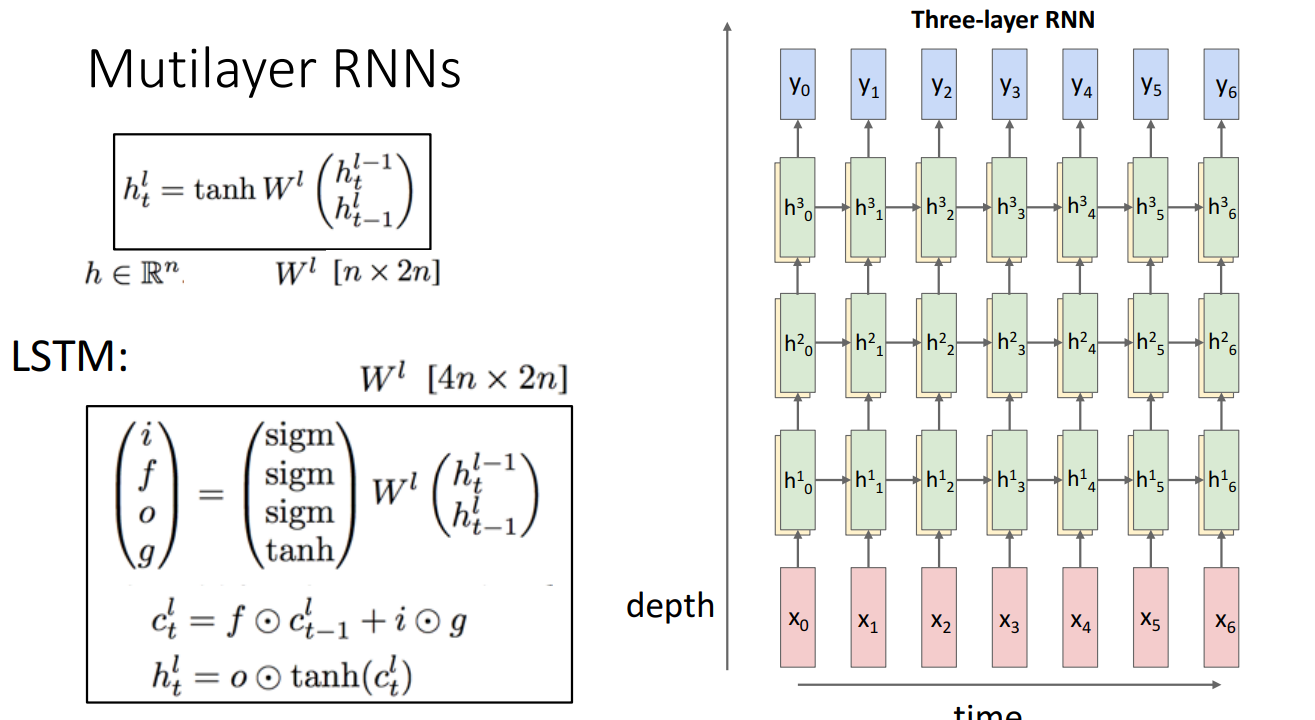
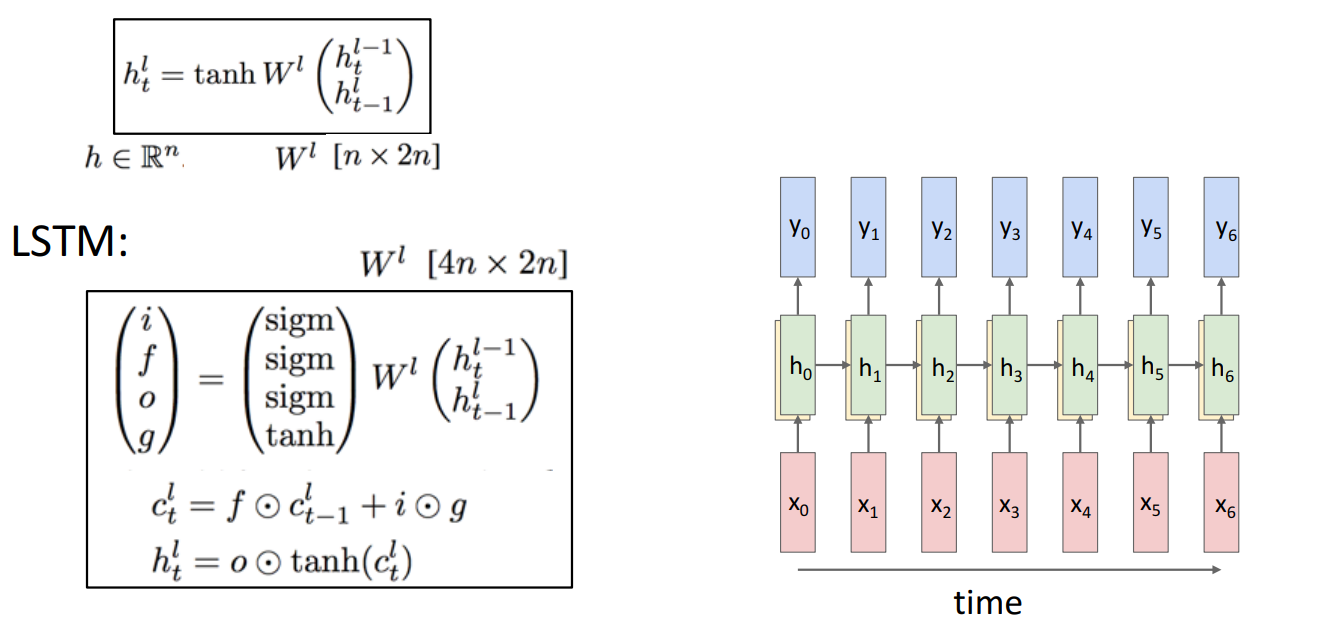
10. Layer에 따른 LSTM 구조
- Single-Layer RNN
- Two-layer RNN
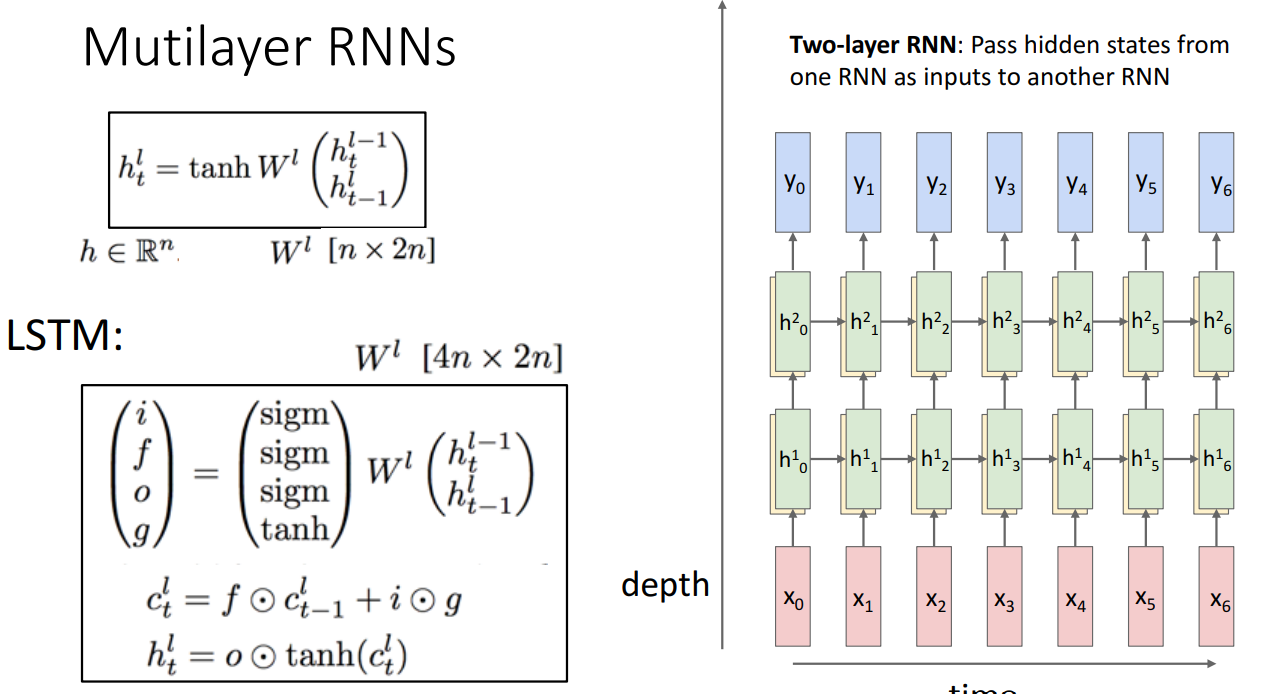
- Three-layer RNN