SPS LAB 2025.02.06 신입생 세미나 3주차
- 본 내용은 Michigan University의 Deep Learning for Computer Vision 8강 CNN Architectures 강의를 듣고 정리한 내용입니다.
- 강의의 원본은 해당 링크에서 확인하실 수 있습니다.
1. ImageNet Classification Challenge
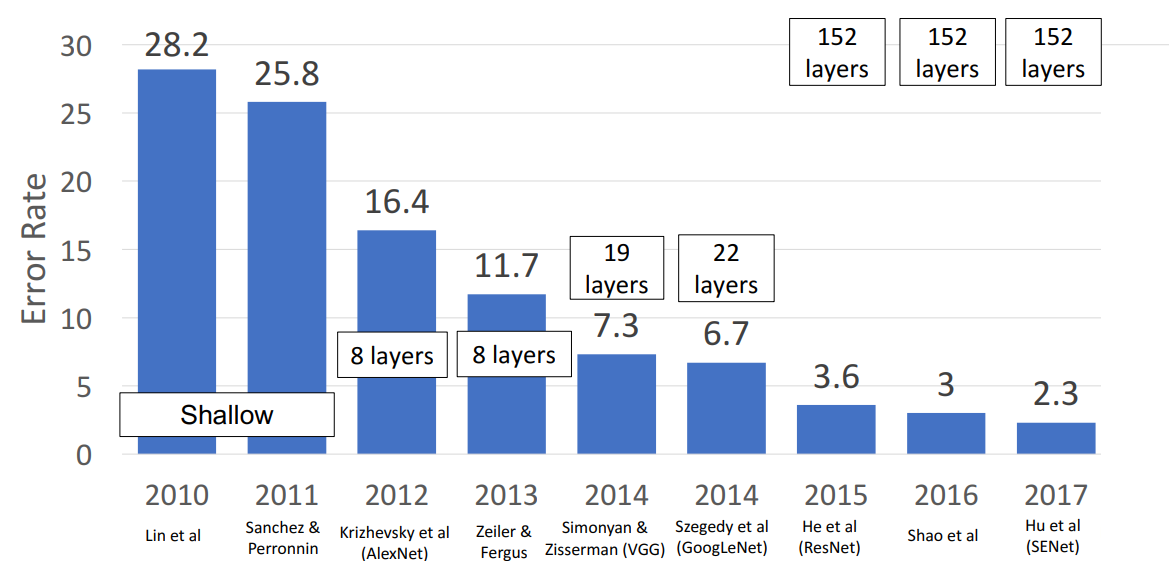
- 이미지 분류를 위한 120만 개의 대규모 데이터셋
- CNN 설계에 많은 연구와 진전을 이끌었음
- 우승 사례
- 2010, 2011년: 모델이 신경망 기반 아님
- 2012년: AlexNet이 우승하며 CNN의 우수한 성능을 입증
- 2013년: ZFNet
- 2014년: VGG
- 2014년: GoogLeNet
- 2015년: ResNet
- 2016년: 좋은 모델들 앙상블함 (Inception, Inception-Resnet, Resnet, Wide Resnet models)
2. AlexNet
-
구조
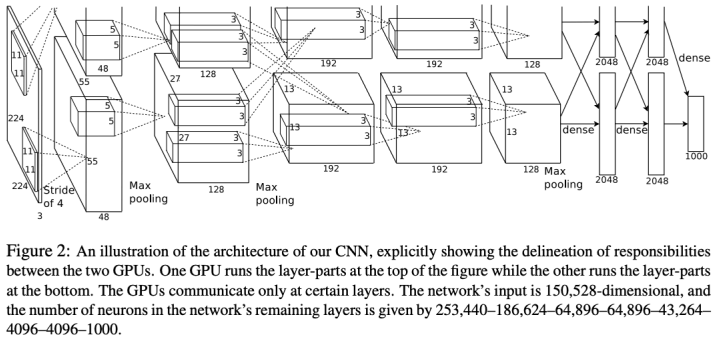
- 227 x 227 input
- 5 Convolutional layers
- Max Pooling
- 3 fully-connected layers
- ReLU 활성화 함수 (AlexNet은 렐루 함수 사용하는 최초의 CNN)
-
더 이상 사용되지 않는 이유
- Local response normalization 사용하는데, 이는 더 이상 사용되지 않는 정규화 방식
- 2개의 GTX 580 GPU를 활용하여 훈련했는데, 각각 3GB 밖에 안 됨 (Colab에서 사용하는 GPU도 약 12~16 GB의 메모리 가지고 있음)
-
Citation per year
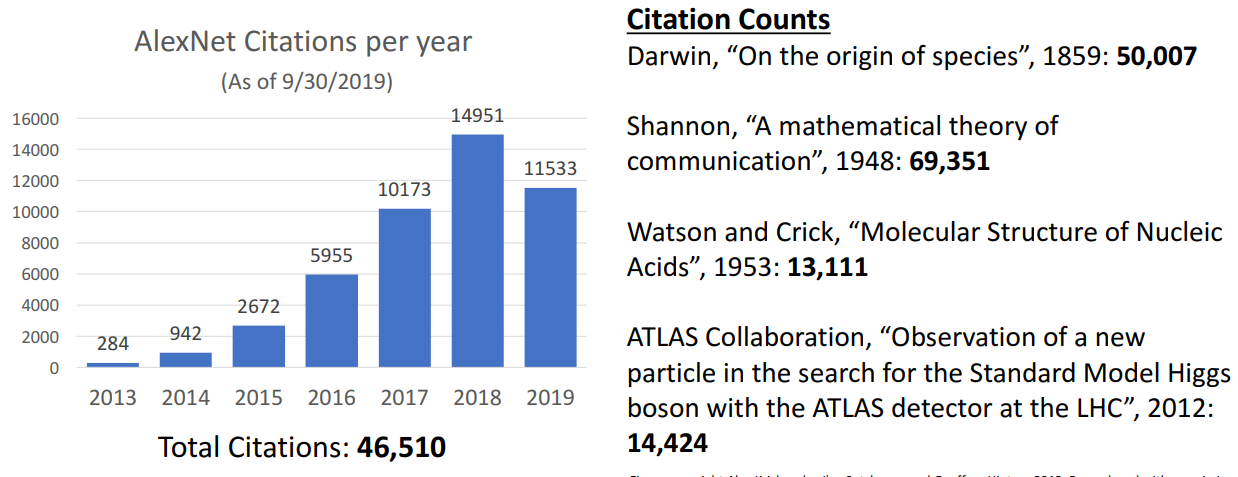
-
계산 진행 방식
- conv1 layer

- input size
- C = 3, channel (RGB)
- H, W = 227, 입력 이미지의 차원
- Layer
- filter = 64
- kernel K = 11 x 11
- stride S = 4
- padding = 2
- output size
- C = 64 (output channels = number of filters)
- H, W = (227 – 11 + 2 x 2) / (4 + 1) = 156 ( W - K + 1 / S + 1)
- memory
- memory (KB) = number of output elements * byte per element / 1024 = 784
- number of output elements = 64 x 56 x 56 = 200,704 (C x H' x W')
- byte per element = 4 (보통 32-bit floating point으로 저장하므로)
- memory (KB) = number of output elements * byte per element / 1024 = 784
- params (k)
- number of weights = 64 x 3 x 11 x 11 + 64 = 23,296
- weight shape = 64 x 3 x 11 x11 ( x x K x K)
- Bias shape = 64 ()
- number of weights = 64 x 3 x 11 x 11 + 64 = 23,296
- flop (M)
- Number of floating point poeration (multiply + add) = number of output element x ops per output element = 200,704 * 363 = 72,855,552
- number of output elements = 64 x 56 x 56 = 200,704 (C x H' x W')
- ops per output elem = 3 x 11 x 11 = 363 ( x K x K)
- Number of floating point poeration (multiply + add) = number of output element x ops per output element = 200,704 * 363 = 72,855,552
- input size
- pool1 layer

- input size
- C = 64, channel (RGB)
- H, W = 56, 입력 이미지의 차원
- Layer
- kernel K = 3 x 3
- stride S = 2
- padding = 0
- output size
- C = 64 (output channels = number of filters)
- H, W = floor((53 – 3) / (2 + 1)) = floor(27.5) = 27 (floor( W - K / S + 1))
- memory
- memory (KB) = number of output elements * byte per element / 1024 = 784
- number of output elements = 64 x 27 x 27 = 46,656 ( x H' x W')
- byte per element = 4 (보통 32-bit floating point으로 저장하므로)
- memory (KB) = number of output elements * byte per element / 1024 = 784
- params (k)
- number of weights = 0 (Pooling layer에는 learnable parameter가 없음)
- flop (M)
- Number of floating point poeration (multiply + add) = number of output element x ops per output element = 46,656 * 9 = 419,904 = 0.4 MFLOP
- number of output elements = 64 x 27 x 27 = 46,656 ( x H' x W')
- ops per output elem = 3 x 3 = 9 (K x K)
- Number of floating point poeration (multiply + add) = number of output element x ops per output element = 46,656 * 9 = 419,904 = 0.4 MFLOP
- input size
- flatten layer
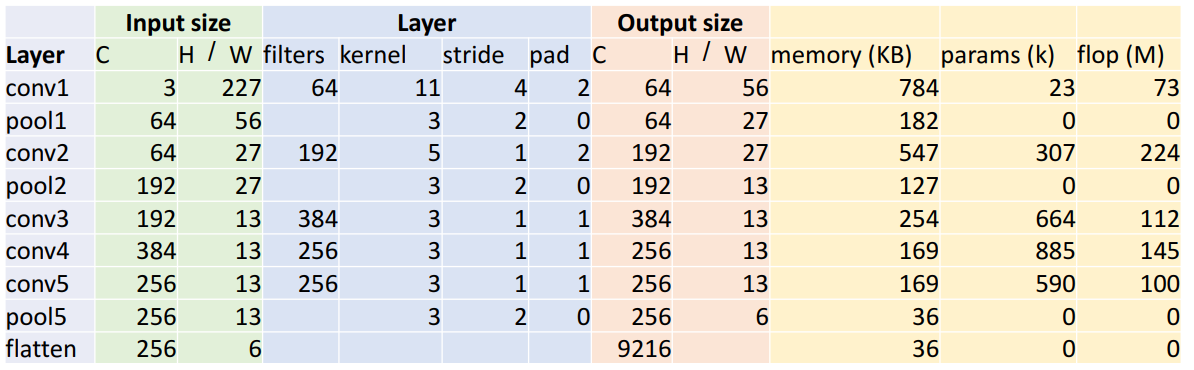
- input size
- C = 256
- H, W = 6
- output size
- 256 x 6 x 6 = 9216 ( x 6 x 6)
- input size
- FC(Fully-connected) layer
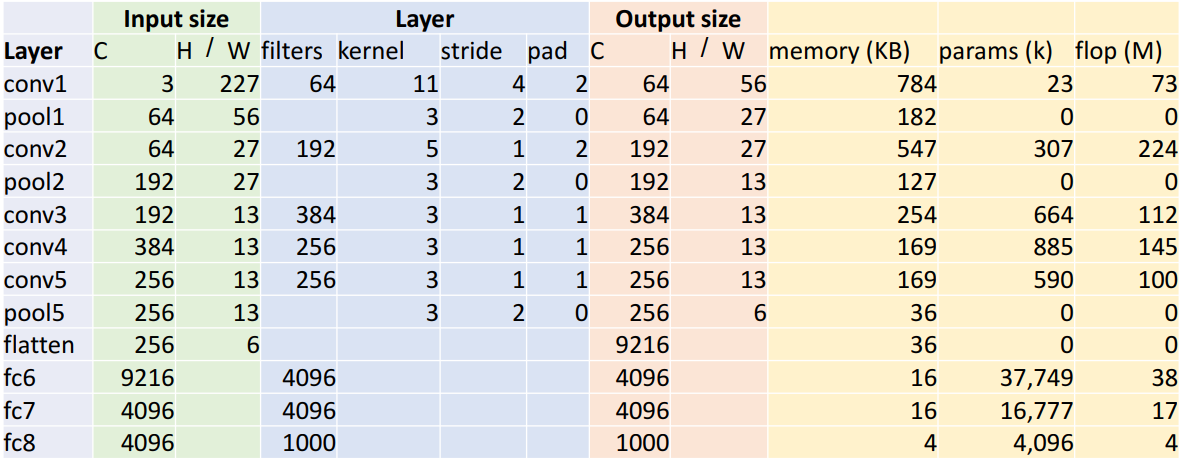
- input size
- C = 9216
- output size
- C = 4096
- params (k)
- 9216 x 4096 x 4096 = 37,725,832 ( x x )
- flops (M)
- 9216 x 4096 = 37,748,736 ( x
- input size
- conv1 layer
-
시사할 점
- 층의 구조나 파라미터 값들은 시행착오적으로 구한 값
- 메모리 사용량 대부분이 초기의 conv layer임
- conv layer에서 높은 해상도와 많은 수의 필터를 갖기 때문
- parameter는 fc layer가 대부분 존재
- 연산량(floating-point ops)를 차지하는 대부분이 conv layer임
- pooling layer, FC layer와 다르기 conv layer는 커널에 따라 계산이 진행되기 때문
3. ZFNet
- 정의
- AlexNet보다 더 큰 신경망 구조로, 더 많은 시행착오로 성능을 높인 케이스
- 구조
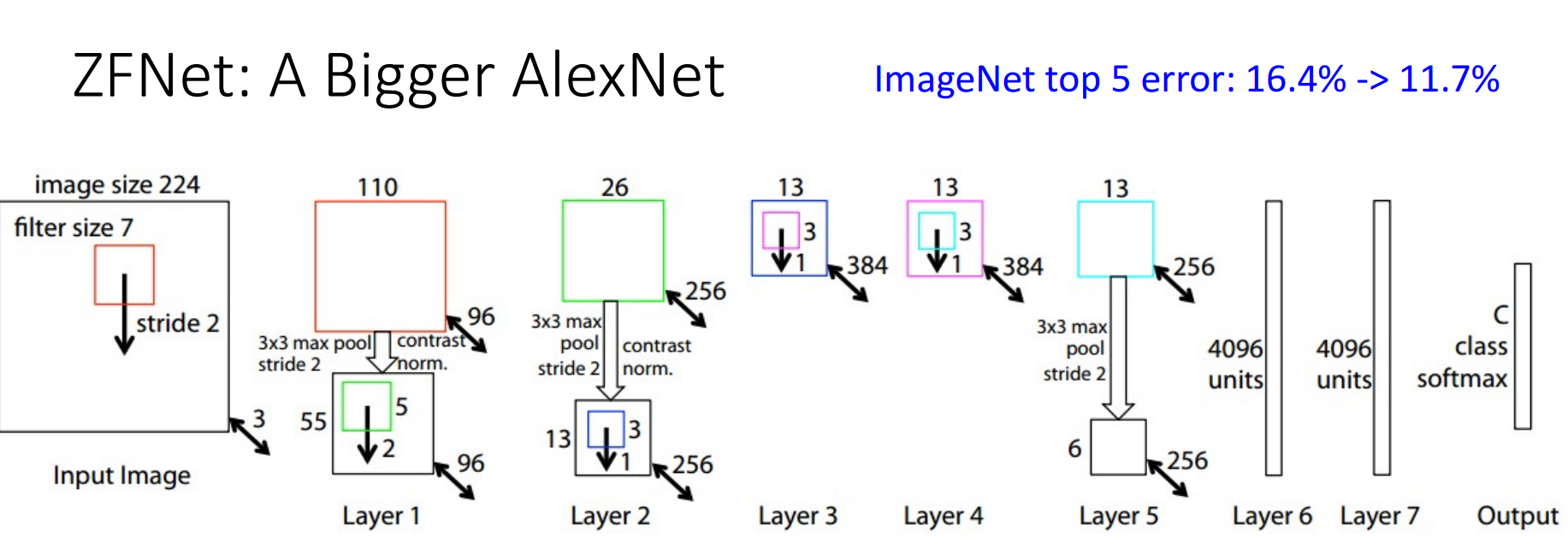
- Conv1에서 11 x 11 stride 4 --> 7 x 7 stide 2
- stride가 작아지면 downsampling하는 정도도 적어지고, 이는 높은 공간 해상도 = 높은 receptive field = 높은 연산량을 필요로 함
- Conv3, 4, 5에서 384, 384, 256 kernel --> 512, 1024, 512
- filter가 커지면 네트워크가 더 커지며 더 많은 메모리 필요로 함
- Conv1에서 11 x 11 stride 4 --> 7 x 7 stide 2
4. VGG
- 등장 배경
- AlexNet과 ZFNet의 구성은 시행착오를 통해 설정되었고, 이로 인해 네트워크를 확장하거나 축소하기가 어려움
- 확장을 위해 수작업으로 설계된 맞춤형 convolutional Architecture에서 벗어나 네트워크의 전체 구성을 안내하는 데 사용된 몇 가지 설계 원칙이 있는 아키텍쳐를 사용하고자 함
- 설계 규칙

- 모든 conv
- 3 x 3 stirde 1
- pad 1
- 모든 max pool
- 2 x 2 stride 2
- pool 이후
- 채널 수 double
- stage
- 여러 개의 conv layer와 pool layer로 이루어진 단계
- 5개의 convolutional stage 존재
- 모든 conv
- 설계 규칙에 대한 증명
- conv layer

- conv layer가 많고, kernel size가 작은 경우가 파라미터 개수나 연산량이 더 적음
- ex1) 1 conv layer, 5 x 5 kernel size
- params = , FLOPs =
- ex2) 2 conv layer, 3 x 3 kernel size
- params = , FLOPs =
- ex1) 1 conv layer, 5 x 5 kernel size
- kernel size를 조정하기보다는 고정하고 쌓는 conv layer 수에 초점을 맞춤
- conv layer가 많고, kernel size가 작은 경우가 파라미터 개수나 연산량이 더 적음
- pool layer
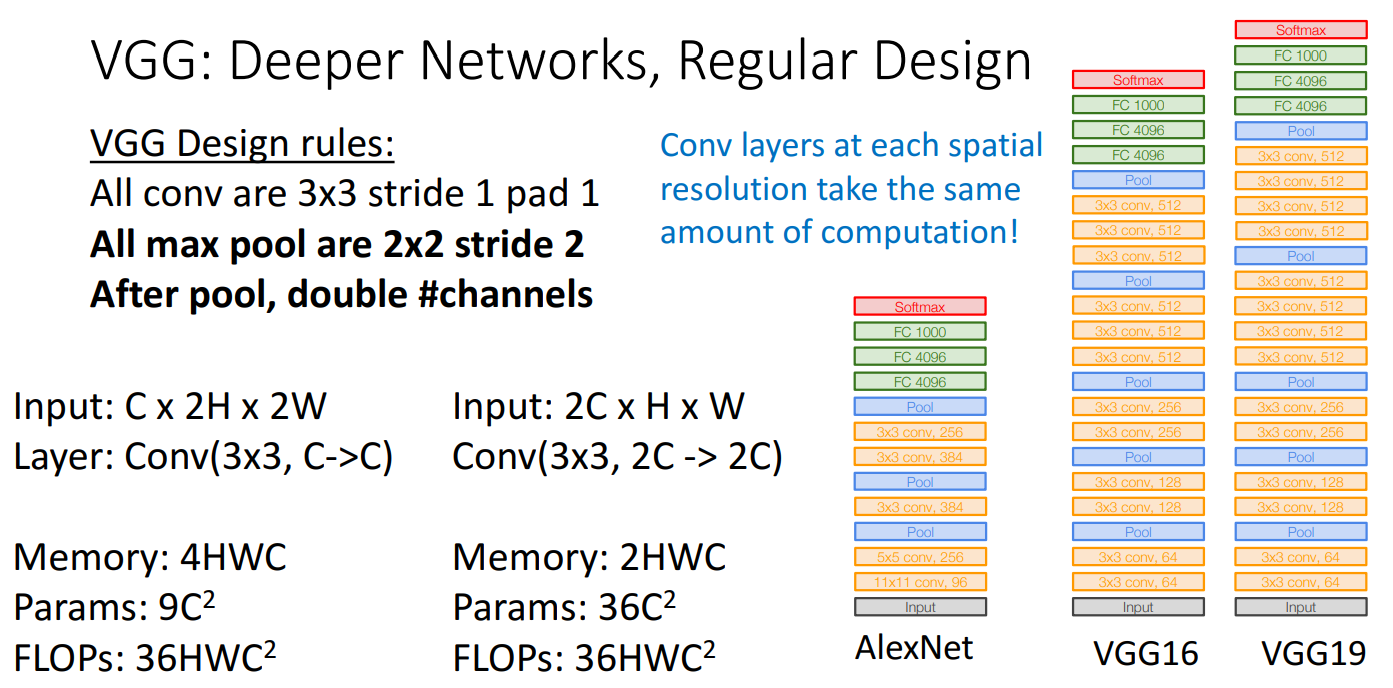
- pooling 진행하면 채널 수 2배로
- conv layer
- Alexnet vs/ VGG-16
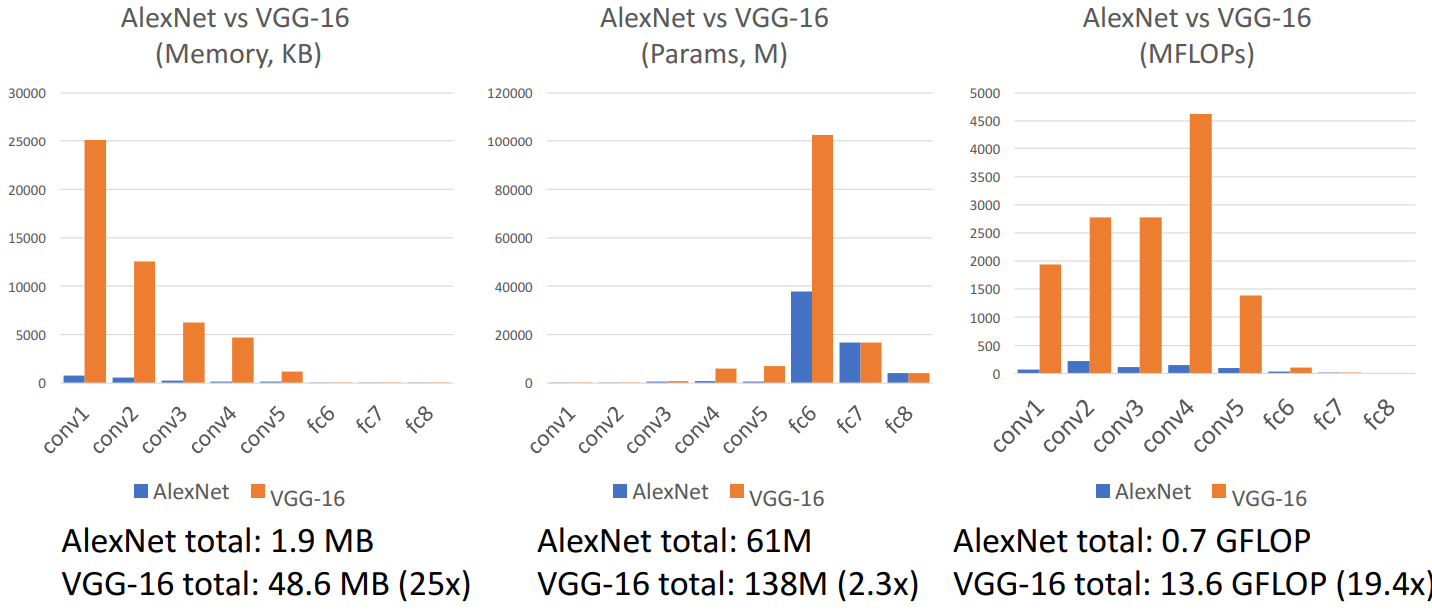
- VGG가 Alexnet에 비해 훨씬 더 거대한 네트워크
5. GoogLeNet
- 아이디어
- 효율성에 초점을 맞춤 (parameter count, memory usage, computation 모두 감소시키는 것)
- 구조
- Stem network
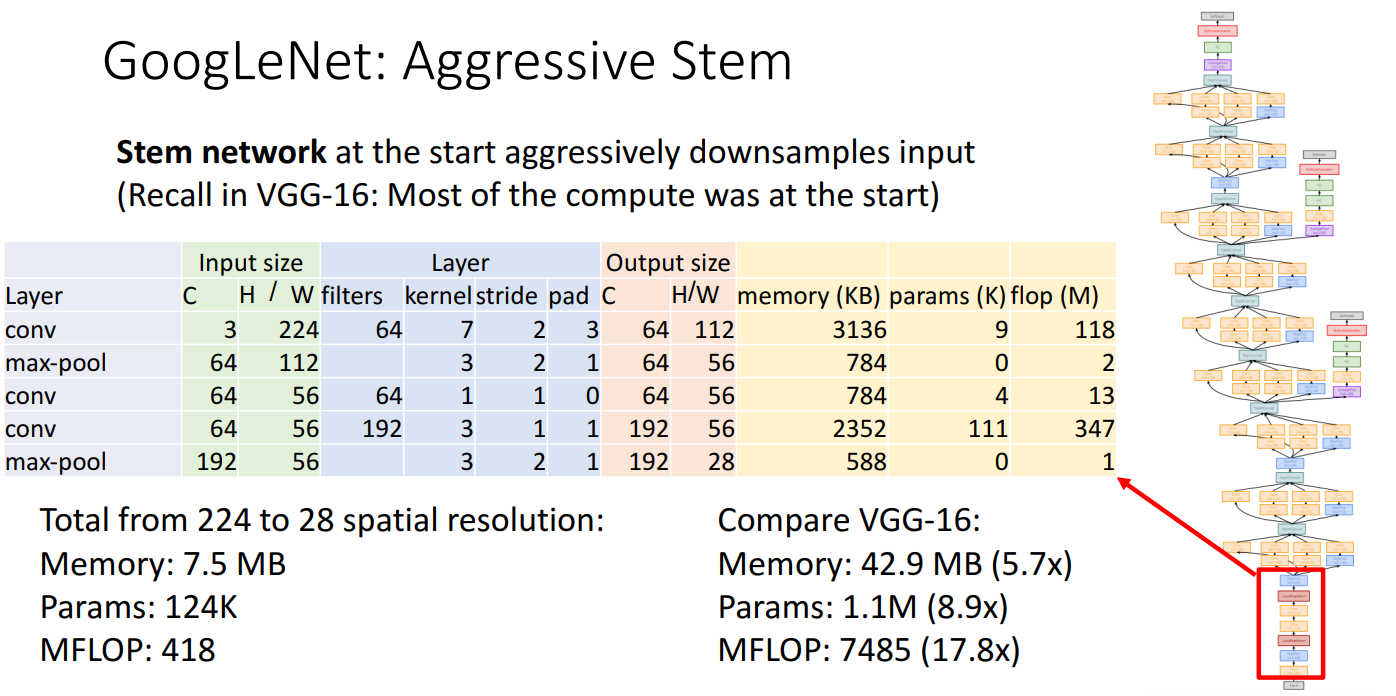
- input image를 매우 공격적으로 초반에 downsampling을 수행
- VGG에서 초반 conv layer에 대부분 연산량이 존재했던 것을 해결하기 위함
- Inception module
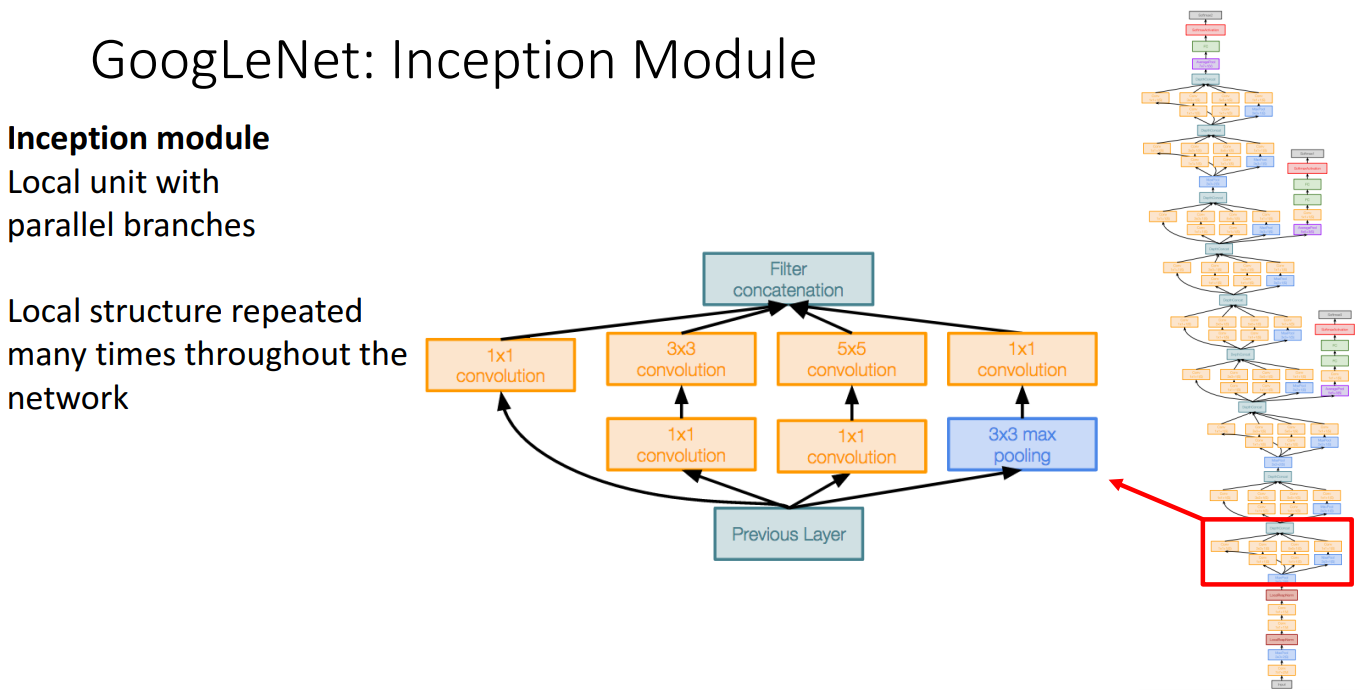
- GoogLeNet의 전체 네트워크에서 반복되는 로컬 구조
- Parallel 구조를 가진 블록으로, 서로 다른 크기의 필터(1x1, 3x3, 5x5) 및 풀링 연산(3x3 max pooling)을 동시에 진행
- 최종적으로 여러 결과를 Filter Concatenation
- 비싼 합성곱을 수행하기 전에 1x1 conv 사용하여 채널 수를 줄임 (bottleneck 현상)
- Global Average pooling
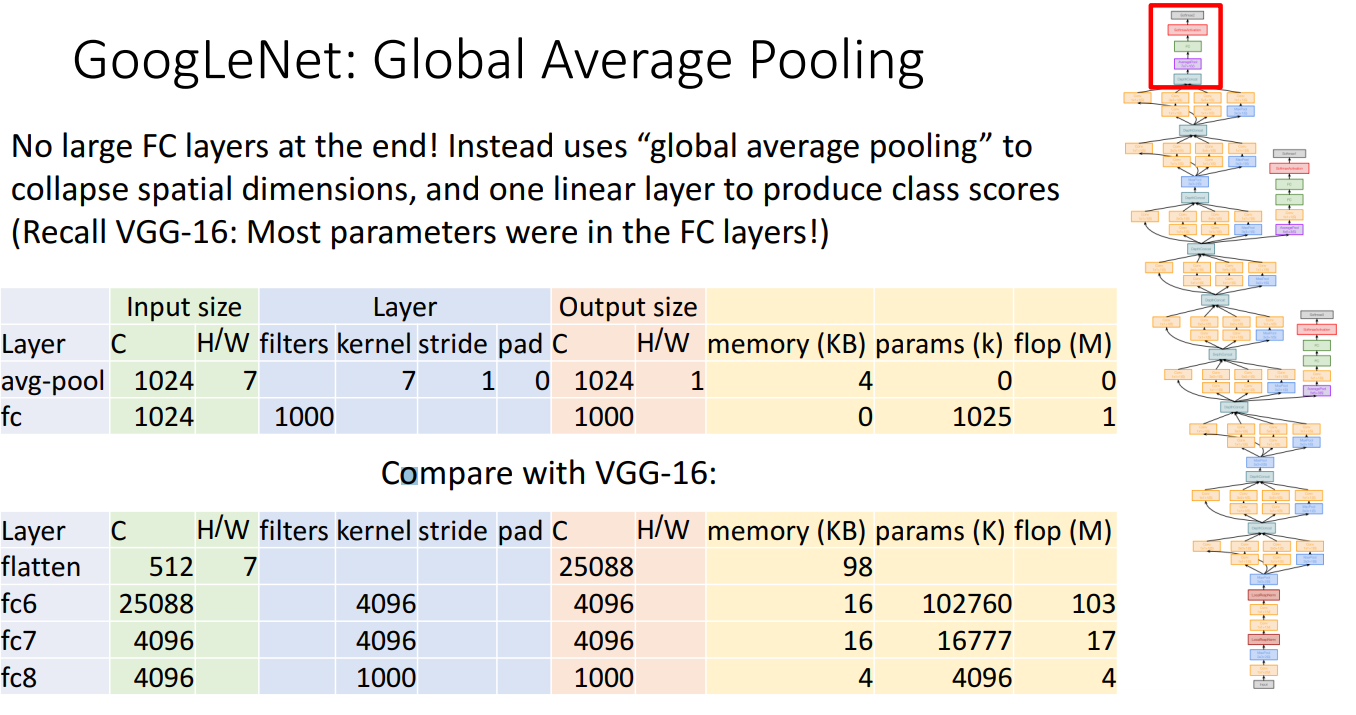
- 맨 끝에 여러 FC layer를 사용하는 것이 아니라 global average pooling을 활용
- 기존에 쓰던 합성곱 텐서를 거대한 벡터로 평탄화하여 공간 정보를 파괴하는 기법 대신에 output 공간 크기(H, W)와 같은 커널 크기를 가진 average pooling 적용하여 공간 정보 파괴
- 이를 통해 매개변수에 대한 엄청난 수의 학습을 제거할 수 있음
- Auxiliary Classifier
- Batch Normalization이 나오기 전에 생긴 아이디어
- 이전에는 10개 이상의 layer가 있는 네트워크를 훈련하는 것이 매우 어려움
- 더 깊은 네트워크를 학습하기 위해서는 ugly hack에 의존해야 했음
- 그 중 하나가 Auxiliary Classifier (보조 분류기)
- 네트워크 끝에서 한 번, 네트워크 중간에서 두 번 총 3가지의 클래스 점수 세트를 출력
- 각 분류기에서 손실을 계산하고 gradient를 전파
- Batch Normalization이 나오기 전에 생긴 아이디어
- Stem network
6. Residual Networks
- 등장 배경
- Batch Normalization 등장 이후 bigger layer에서 성능이 좋아졌으나, 깊은 모델에서는 성능이 좋지 못함
- 깊은 모델이 얕은 모델보다 항상 더 나은 성능을 가져야 하는데, 깊이가 깊어질수록 오히려 학습이 잘 안 되는 최적화 문제가 발생
- deeper model은 shallower model을 모방(emulate)할 수 있음
- ex) 56개 레이어를 가진 네트워크가 20개 레이어를 가진 네트워크를 복사하고 나머지 레이어는 identity function만 학습하는 것
- 더 깊은 모델은 최적화가 더 어렵고, 특히 더 얕은 모델을 모방하는 항등 함수를 학습하지 못함
- 해결책
- 네트워크를 변경하여 레이어가 깊어져도 항등 함수를 쉽게 학습할 수 있게 함
- shortcut
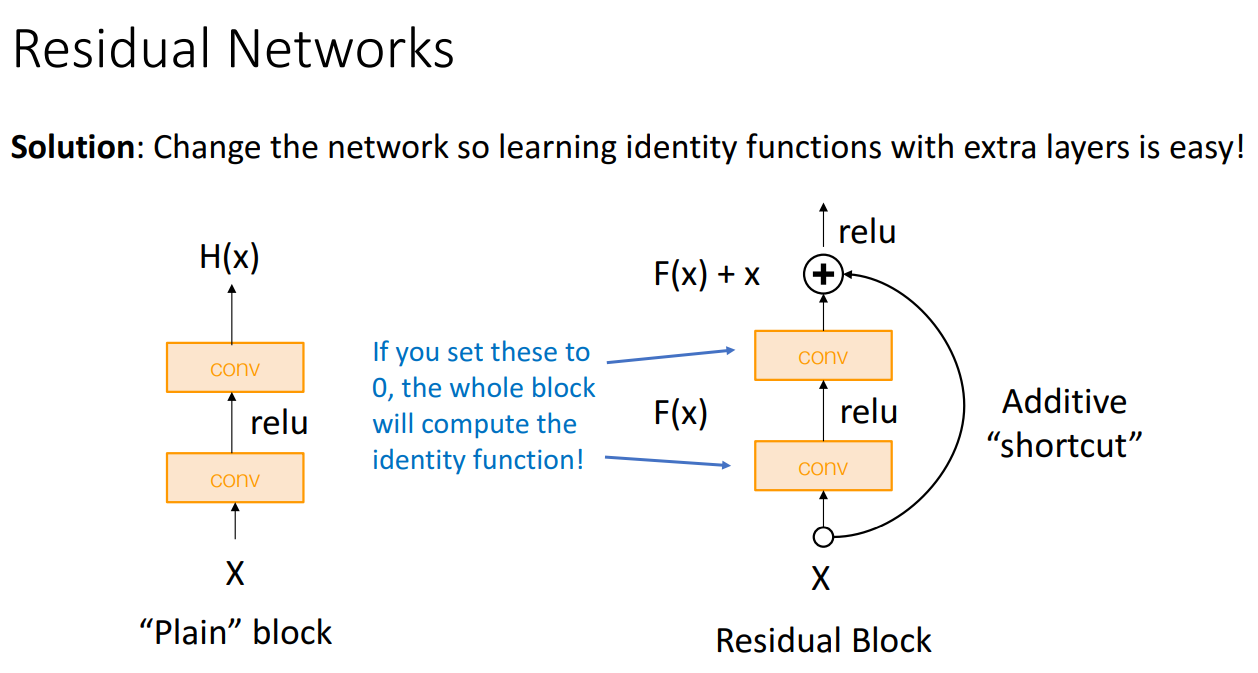
- 합성곱 레이어의 가중치를 0으로 설정하면 identity function을 쉽게 배울 수 있게 함
- 네트워크의 gradient 흐름을 개선하는 데 도움이 됨
- 구조
- 많은 residual block의 stack
- VGG의 간단한 설계 원칙과 GoogLeNet의 수학적 계산 구조를 가져온 모델
- 각 residual block은 2개의 3x3 conv를 가지고 있음
- network는 여러 stage로 나뉨
- 각 stage의 첫번쨰 block은 stride-2 conv를 활용하여 차원 반으로 줄임
- 이후 채널을 2배로 함
- 첫번째 레이어에서 GoogLeNet과 동일하게 aggressive stem을 통해 downsampling 진행
- GoogLeNet과 동일하게 global average pooling 활용하여 네트워크의 총 매개변수 수 줄임
- 예시

- Basic block vs. Bottleneck block

- Bottleneck block은 텐서에 포함된 채널 수를 줄이는 1 x 1 conv layer와 다시 채널 수를 확장하는 1 x 1 layer가 존재
- 더 깊은 네트워크를 구축할 수 있고, 계산 비용은 효율적임
- 여러 모델 구조
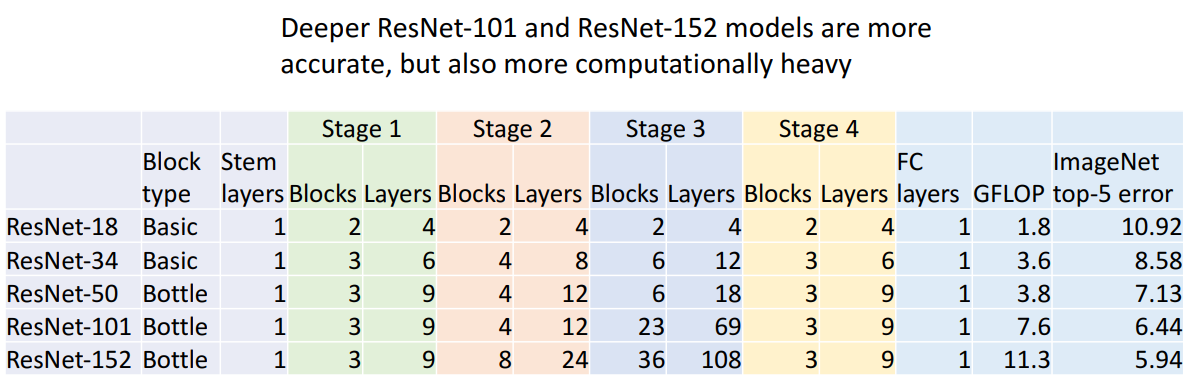
- 성능

- 많은 대회에서 우수한 성능을 보이면서 오늘날까지도 널리 사용되는 기준이 됨
- 모델 비교
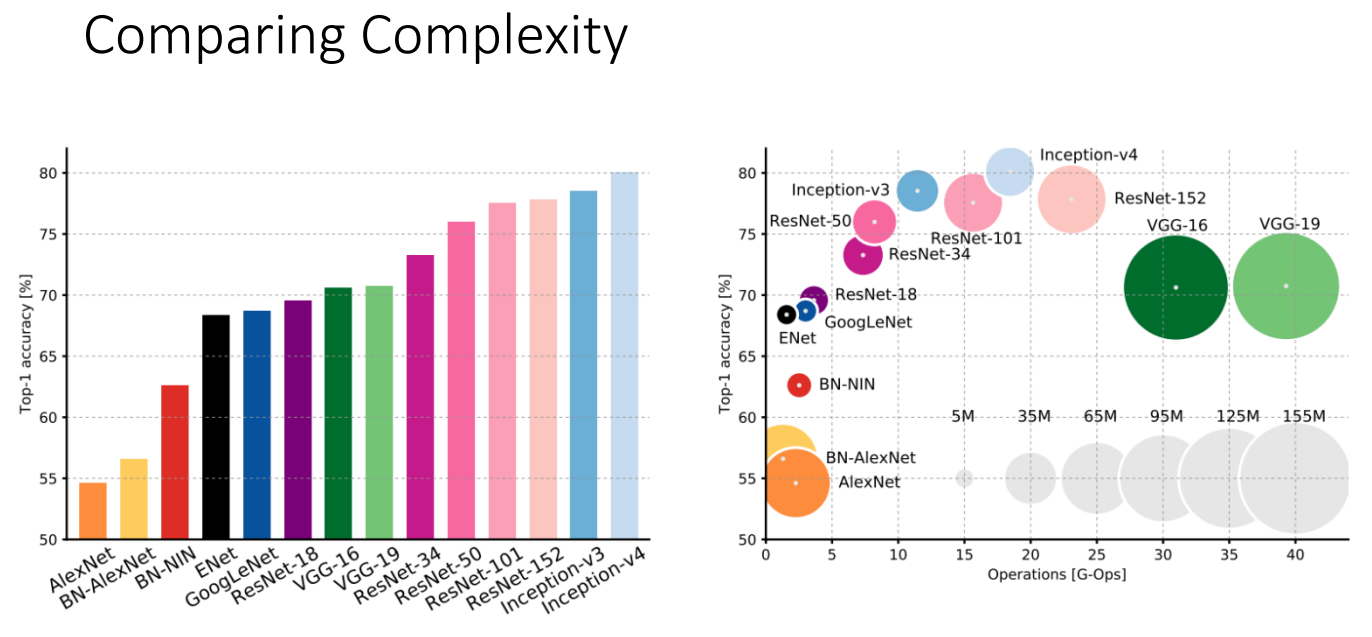
- VGG: 매우 높은 메모리와 엄청난 양의 연산 필요, 비효울적인 네트워크
- GoogLeNet: 효율적인 연산량을 갖지만. 이후에 나오는 모델에 비해 성능이 높지 않음
- AlexNet: 매우 적은 연산량, FC layer로 인해 많은 파라미터 수 가짐
- ResNet: 간단한 디자인, 적당한 효율성, 높은 정확도
- 후속 모델
- 블럭 구조 개선하기: "Pre-Activation" ResNet Block
- Conv 전에 BN과 ReLU 넣어 identity function을 학습할 수 있게 함
- ResNeXt
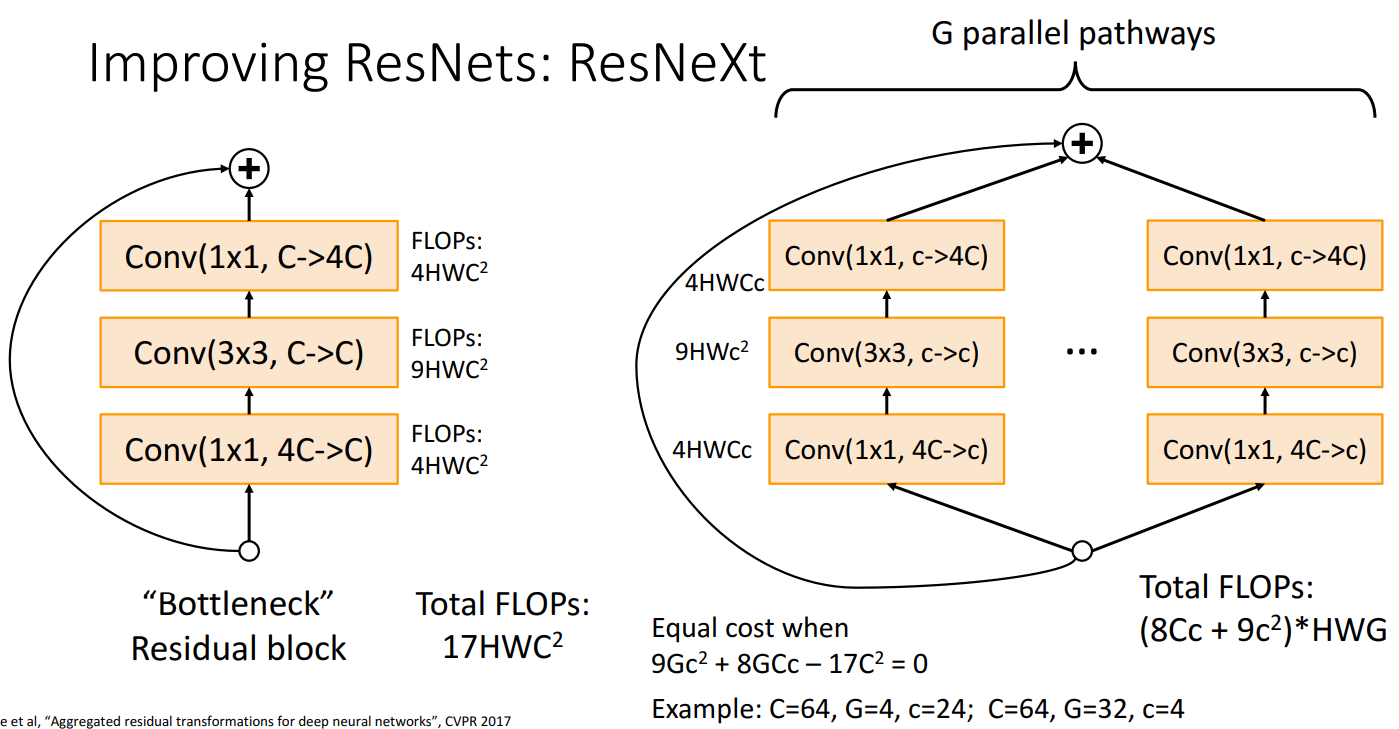
- bottleneck block을 병렬적으로 구성
- Grouped Convolutions을 사용하여 효율적으로 계산
- ResNet보다 깊이 증가에 의존하지 않고, 병렬 경로를 추가하여 더 많은 특성을 학습하는 방식
- 예시
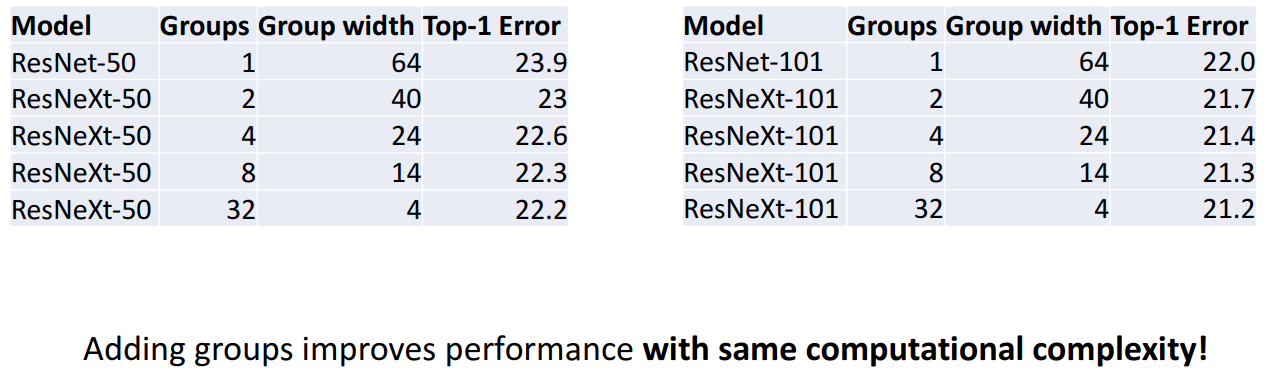
- ResNet: C=64,G=4,c=24
- ResNeXt: C=64,G=32,c=4 일때 계산 복잡성이 동일하게 유지되면서, 성능이 더 좋음
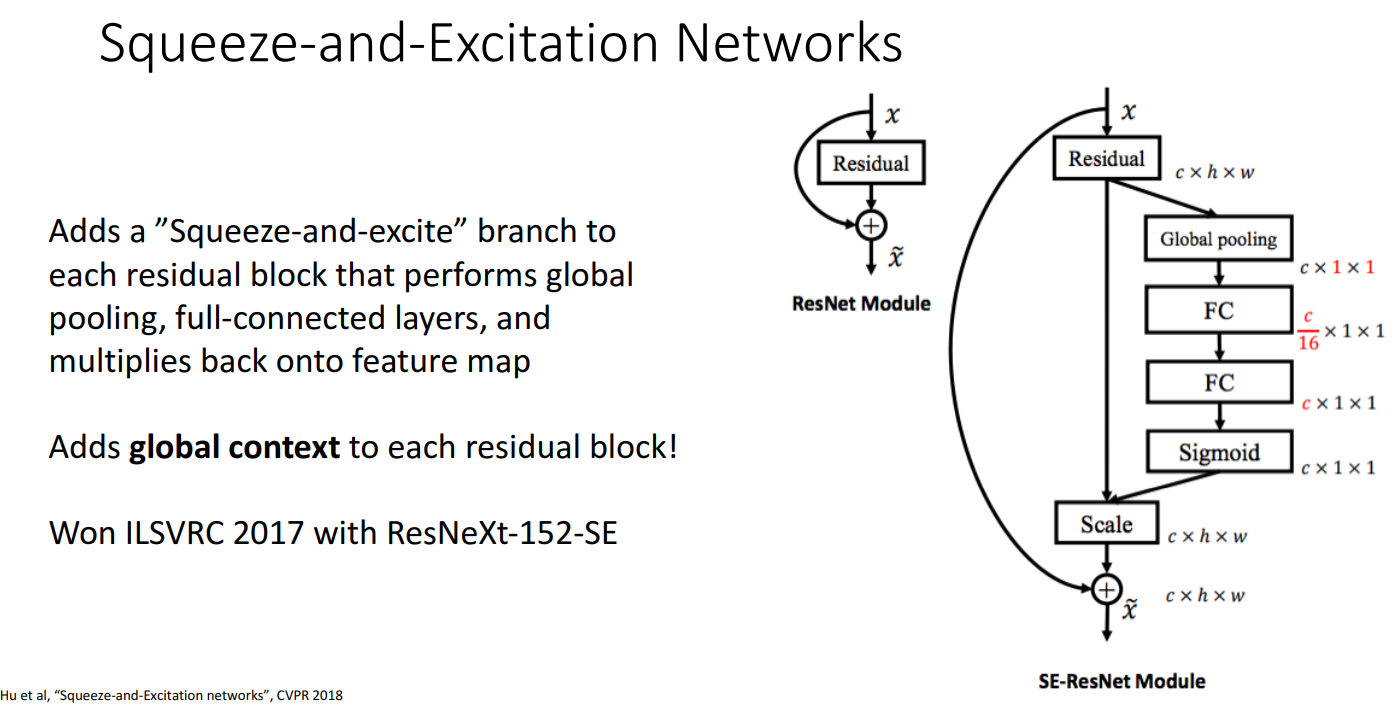
- SENet (Squeeze-and-Excitation Networks)
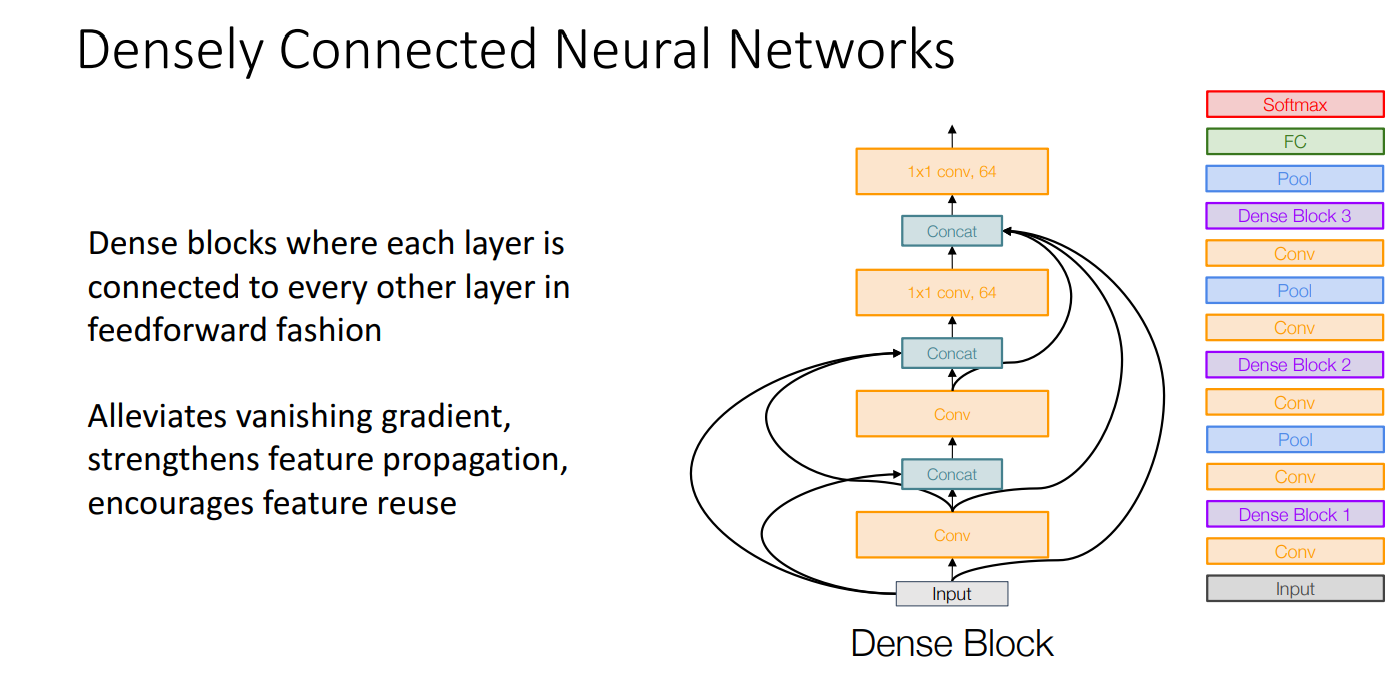
- Densely Connected Neural Networks
- MobileNets

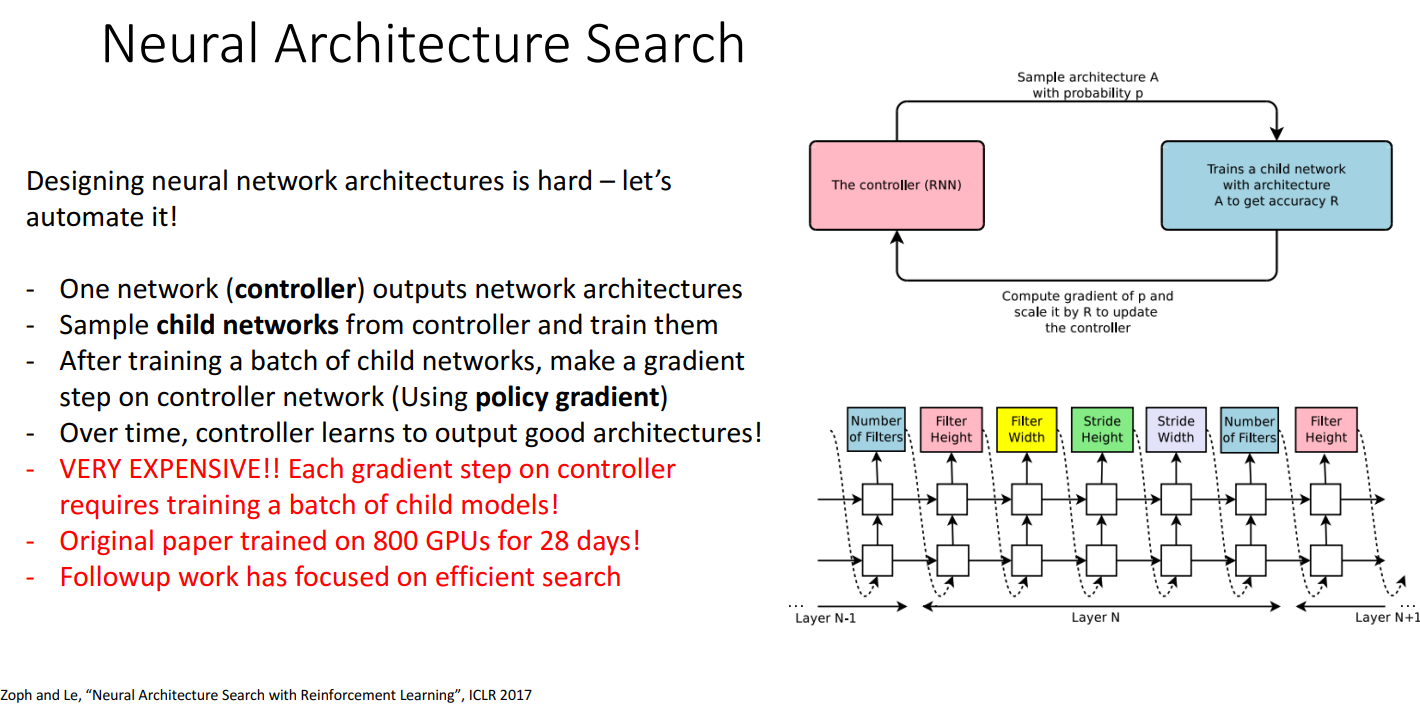
- Neural Architecture Search
- 블럭 구조 개선하기: "Pre-Activation" ResNet Block
