SPS LAB 2025.07.30 논문 세미나
- 본 내용은 Frequency-Masked Embedding Inference: A Non-Contrastive Approach for Time Series Representation Learning 논문을 읽고 정리한 내용입니다.
- 논문 원본은 해당 링크에서 다운받으실 수 있습니다.
Contribution
- Pair가 필요 없는 시계열 데이터에 대한 새로운 self-supervised representation learning framework인 FEI를 제안
- FEI는 frequency masking prompt를 사용하여 임베딩 공간에서 서로 다른 frequency bands의 embedding inference를 수행하여 연속적인 의미 모델링을 가능하게 함
- linear evaluation 및 end-to-end fine-tuning experiments를 통해 표현의 품질을 검증함
- 8개의 벤치마크 데이터셋을 활용한 고수준 표현이 필요한 분류 및 회귀 작업에서 높은 성능을 달성
- Time series self-supervised representation learning을 위한 비대조 학습의 타당성과 효과를 입증하여 이 분야의 추가 연구를 위한 새로운 통찰력을 제공
Introduction
- 시계열 데이터는 다양한 산업의 생산 프로세스 및 경제 활동에서 중요한 역할을 함
- 효과적인 표현 학습 방법은 Transferable이 높고, generalizable한 패턴 인식 모듈을 구축하는 게 필수적임
- 하지만 CV, NLP와 다르게 시계열 분석 분야에서는 일반화 성능이 충분하지 않아 Self-supervised representation learning이 잘 이루어지지 않고 있음
- 그 중 Contrastive Learning이 최근 몇 년간 많은 연구의 기초 프레임워크가 되었음
- 대조 학습은 Anchor sample에 대해 Positive 및 Negative Pair를 구성하여 모델을 최적화
- 대조 학습 프레임워크의 주요 문제는 시계열 데이터에 적합한 Positive 및 Negative Pair를 정의하는 데 어려움이 있다는 것
- 시계열의 본질적인 연속성(Inherent continuity)으로 인해 trend 및 frequecy와 같은 주요 특징이 지속적으로 변화함
- 시계열 데이터의 semantic boundary를 불분명하게 만듦
- 이미지에서 강아지와 고양이 사진을 반대되는 것으로 정의하는 것은 쉽지만, 7일 주기의 시계열과 6일 주기의 시계열이 유사한지 반대되는지 정의하기는 어려움
- 대조 학습은 이산 모델링 접근 방식(discrete modeling approach)를 사용하여 모든 샘플에 대해 절대적으로 반대되는 의미론을 정의하며, 이는 시계열의 고유한 연속성과 모순됨
- 이러한 문제를 해결하기 위해 여러 시도를 진행했으나, 대조 학습의 이산 모델링 프레임워크 내에서 작동하며 문제의 근본 원인을 해결하지 못함
- 따라서 본 연구는 시계열의 의미론적 차이를 완전히 새로운 방식으로 정의하는 것을 목표로 함
- 본 논문에서는 새로운 비대조적 시계열 표현 학습 프레임워크인 FEI(Frequency-masked Embedding Inference) 제안
- CV 분야에서 Joint-Embedding Predictive Architecture(JEPA)에서 영감을 받아, FEI는 Embedding Inference의 개념을 통해 시계열 데이터에서 서로 다른 의미 간의 연속적인 관계를 설정하고, 주파수 변화에 민감한 연속적인 임베딩 공간을 구축
- FEI는 frequency masking prompts를 사용하여 임베딩 공간에서 specific frequency sample을 직접 추론
- 의미 간의 차이를 모델링하는 대조 학습과는 달리, FEI는 서로 다른 의미 간의 관계를 모델링하는 데 중점을 두며 프롬프팅 전략을 통해 연속적인 모델링을 달성함
Related Work
Time series representation learning
- 최근 대조 학습은 시계열 고수준 표현 학습의 기본적인 패러다임이 됨
- SimMTM: 임베딩 공간에서 시계열 재구성 표현을 학습하는 것 외에도 대조 손실을 사용하여 양성 및 음성 샘플 간의 표현 거리를 제한
- TimeDRL: CLS 토큰을 사용하여 고수준 표현을 얻고, 기울기 절단(gradient truncation)을 통해 subspace mapping의 여러 단계에서 양성 및 음성 샘플 쌍을 생성하여 CLS 토큰의 고수준 표현 최적화를 진행
- COMET: multi-level contrast constraints을 구성하여 안정적인 고수준 표현 학습 프로세스를 달성
- 대조 학습 프레임워크의 이산적인 모델링 특성으로 인해 양성 및 음성 샘플 쌍의 구성은 최적화 결과에 영향을 줄 수 있음
- TS2Vec: 양성 및 음성 쌍에서 부적절한 사전 지식을 제거하기 위해 향상된 컨텍스트 구성 전략을 제안
- TimesURL: 주파수 영역 관점에서 양성 및 음성 샘플을 구성, 여러 샘플의 스펙트럼을 혼합하여 새로운 증강 샘플을 생성
- TF-C: 주파수 영역 관점에서 양성 및 음성 샘플을 구성, 스펙트럼 마스킹 및 향상을 통해 증강 샘플을 구성
- 하지만 여전히 대조 학습 프레임워크 내에서 작동하며, 이산적인 모델링 접근 방식에 내재된 문제를 근본적으로 해결할 수 없음
Joint-Embedding Predictive Architecture
- 잠재 공간에 추가적인 공변량(covariates)을 도입하여 모델이 여러 의미 간의 관계를 학습하도록 안내하는 self-supervised learning 개념
- 가장 성공적인 적용 사례는 I-JEPA
- 자가 지도 프로세스에서 인간의 사전 지식이 불필요함을 보여줌
- 자기 지도 표현 학습에서 샘플 증강으로 인해 발생하는 부적절한 편향 문제를 근본적으로 해결할 수 있는 솔루션 제공
- JEPA는 Computer Vision 및 Time series Forecasting에서 널리 주목받고 있으나, Time series representation learning에 많이 적용되지 않음
Proposed Method (Frequency-masked Embedding Inference)
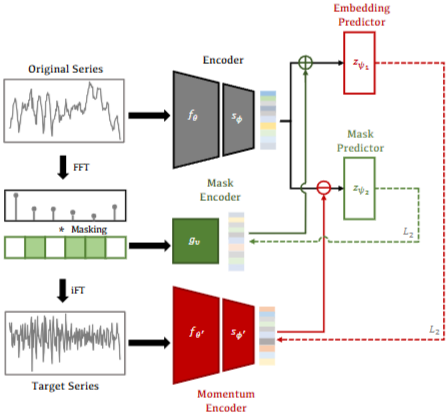
- Mask Prompt에 기반한 Target Embedding Inference와 Target Embedding Prompt에 기반한 Mask Inference 이렇게 2개의 추론 분기로 구성
- 전체적인 사전 훈련 목표는 범용 시계열 인코더(Universal time series encoder) 를 얻는 것
1. Original Encoder
- original time series 이 주어지면, 는 에 대해 embedding vector 를 생성
- projector 는 훈련 복잡성을 줄이기 위한 완화 요소 역할을 하고, 서브 공간 를 얻는 데 사용
- 이고, 는 single linear layer로 구성
2. Momentum Encoder
- FEI는 대조 학습 아키텍쳐와 같은 명시적인 훈련 제약이 없기 때문에 단일 인코더를 기반으로 임베딩 추론을 직접 수행하면 표현 붕괴로 이어질 수 있어서 이 문제를 완화하기 위해 Momentum Encoder를 활용
- 와 의 부드럽게 업데이트된 복사본인 , 를 Target time series Encoder로 사용
- 지수 이동 평균(Exponential moving average)을 사용하여 업데이트되며 기울 계산에 직접 참여하지 않음
- 업데이트 프로세스
3. Frequency Masking
- original series 에 대응하는 target series 를 얻으면서 연속성을 유지하기 위해, random frequency masking이 사용됨
- original series 는 Fast Fourier Transform(FTT)를 거쳐 진폭 스펙트럼(amplitude spectrum)을 얻음
- 그런 다음 개의 마스크 위치를 갖는 임의의 마스크 이 생성
- 마스크된 주파수 성분 위치는 1로 표시되고, 마스크되지 않은 위치는 0으로 표시
- 마스크된 주파수 성분의 수 는 임의의 변수
마스킹 비율은 균등 분포
- 각 마스킹 연산이 original series의 전체 주파수 성분의 에서 까지 포함하여 훈련 중에 풍부한 variation semantics을 제공
- 이 마스크는 original series의 amplitude spectrum에 적용되어 일부 주파수 성분을 가리고, Inverse Fourier Transform(IFT)을 사용하여 미스크된 주파수를 갖는 Target series 을 얻음
- 이러한 설계는 일관된 마스킹 비율을 사용하여 발생하는 의미론적 획일성 문제를 피하면서, 고정된 마스킹 패턴으로부터 모델 훈련 과정에 부적절한 편향이 도입되는 것을 방지함
4. Mask Encoder
- frequency mask 을 임베딩 공간 프롬프트로 사용될 수 있는 임베딩 벡터로 변환하기 위해, mask embedding 을 생성하는 전용 Mask Encoder를 설계
- 주파수 성분이 마스크되지 않은 경우, 즉 인 경우, 마스크 임베딩 도 0이어야 함
- 또한, 가 변함에 따라 의 평균과 분산은 비교적 안정적으로 유지되어야 함
- 제안된 Mask Encoder는 다음과 같음
- 는 임베딩 행렬을 구성하며, 각 는 주파수 성분에 대한 임베딩 벡터를 의미
- 는 정규 분포 에서 임의로 초기화되고 훈련 중에 업데이트됨
5. Embedding Inference
- 임베딩 추론 부분은 2개의 분기로 구성: Target Embedding Inference, Mask Inference
- 두 분기 모두 1-layer MLP-based predictor를 사용하지만, Prompt Embedding과 merging method에서 차이가 있음
- Target Embedding을 추론할 때, Mask Embedding 을 사용하고, 반대로 Mask Embedding을 추론할 때 Target Embedding 를 활용
- 는 gradient detaching을 의미하는데, 해당 방법은 모델이 두 추론 과정에서 서로 다른 최적화 측면에 집중하도록 강제하는 데 사용
- Target Embedding을 추론하는 과정에서 Mask Embedding 의 gradient 계산이 분리(detach)되므로 Mask Encoder 는 최적화되지 않고, 인코더 만 최적화하여 original embedding 생성 능력을 향상
- Mask Embedding을 추론하는 과정에서 Target Embedding 의 gradient 계산이 분리되고, 더 나은 마스크 임베딩을 얻기 위해 Mask Encoder 만 최적화
- 이러한 설계는 두 분기의 최적화 목표를 명확히 하고 훈련 과정에서 gradient 충돌을 방지함
- Embedding Inference의 설계는 FEI의 효과를 위한 핵심 모듈임
- 모델이 적절한 프롬프트를 사용하여 임베딩 공간 내에서 seires의 frequency band의 모든 변화를 추론하는 것을 목표로 함
- 모델은 Frequency masking을 프롬프트로 사용하여, 원본 시계열에서 특정 주파수 대역이 없는 대상 시계열의 임베딩 표현을 추론하는 것을 목표로 함. 이는 모델이 임베딩 공간 내에서 시계열의 주파수 대역 변화를 이해하고 예측하도록 훈련시키는 것임.
- 모델이 원래 임베딩과 주파수 마스크된 타겟 임베딩 간의 주파수 차이를 추론하는 것을 목표로 함
- 모델은 Target embedding을 프롬프트로 사용하여, 해당 시계열에 적용된 Frequency mask embedding을 추론하는 것을 목표로 함. 이는 모델이 원본 시계열과 주파수 마스킹된 대상 시계열 간의 주파수 차이를 식별하고 모델링하는 능력을 갖추도록 함.
- 모델이 적절한 프롬프트를 사용하여 임베딩 공간 내에서 seires의 frequency band의 모든 변화를 추론하는 것을 목표로 함
6. Loss function
- 임베딩 추론 결과를 바탕으로, 훈련 손실은 실제와 추론된 각각의 Target Embedding, Mask Embedding 간 L2 Distance를 통해 계산
Experiments
Datasets
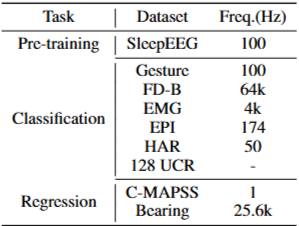
- Pre-training: 사전 훈련에 널리 사용되며 충분한 샘플을 제공하는 SleepEEG 데이터셋을 사용
- Classification: Gesture, FD-B, EMG, EPI, HAR, UCR
- Regression: C-MAPSS, Bearing
Baselines
- 대조 학습 프레임워크: TimesURL, SimMTM, InfoTS, TimeDRL, TF-C, TS2Vec
- Encoder Network는 공정한 비교를 위해 Out-of-Memory가 발생해 교체할 수 없는 TimesURL 제외하고 나머지 방법에 대해 1D-ResNet을 활용하고, 임베딩 차원은 1024로 설정
Pre-training Setup
- 표현 학습의 주요 중요성은 사전 훈련된 모델을 가능한 한 많은 다운스트림 작업에 적용할 수 있도록 하는 것
- 따라서 실험 과정은 해당 원칙을 완전히 준수하여 사전 훈련을 완료한 후 인코더는 각 데이터셋에 대한 추가 사전 훈련 또는 하이퍼파라미터 조정 없이 다양한 다운스트림 데이터 세트로 직접 Transfer됨
- 이 때, 단일 선형 레이어가 작업별 출력 레이어로 사용하고, 해당 접근 방식은 각 방법의 표현 품질의 차이를 완전히 검증함
- 제안된 FEI의 사전 훈련 프로세스에 대한 기본 설정은 SimMTM 및 TF-C를 따름
Main Results
Task 1: Classification
-
Setup
- Linear Evaluation
- 6개의 데이터셋에 대해 수행
- 인코더를 고정하고 선형 분류기만 최적화
- 목표는 사전 학습된 표현(representation)이 얼마나 고품질이며, 추가적인 복잡한 학습 없이도 새로운 작업에 얼마나 잘 활용될 수 있는지를 직접적으로 평가하는 것
- Maximum training iteration은 300, Learning rate는 1e-4
- End-to-end Fine-tuning
- 5개의 데이터셋에 대해 수행
- 사전 학습된 인코더와 분류기 모두 최적화
- 이는 사전 학습된 모델이 특정 다운스트림 작업, 특히 데이터가 부족한 환경에서 얼마나 잘 적응하고 성능을 향상시킬 수 있는지를 평가하는 데 중점을 둠
- Maximum training iteration은 100, Learning rate는 1e-5
- Linear Evaluation
-
Results
-
Linear Evaluation
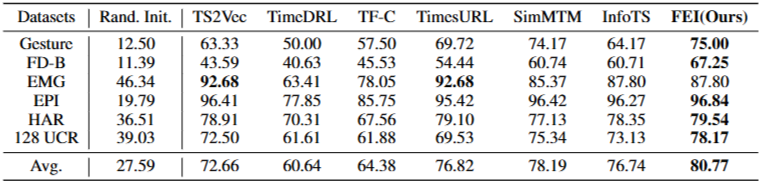
- FEI는 기존 방법보다 평균 2.15%의 정확도 향상을 달성
-
End-to-end Fine-tuning
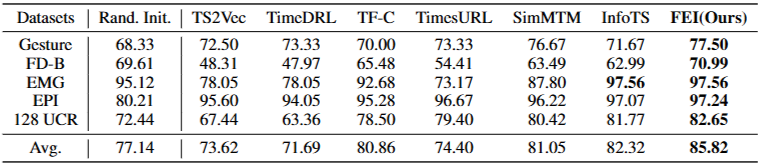
- End-to-end fine-tuning에서 대부분의 모델은 Linear Evaluation 결과에 비해 다양한 수준의 향상을 보임
- 제안된 FEI는 다양한 주파수 대역에 대해 inference 기반 모델링 접근 방식을 채택하여 pretraining dataset에서 각 주파수 대역의 의미를 완전히 활용함
- 이로 인해 Contrastive 기반 방법보다 더 넓은 학습 corpus가 생성되어 encoder의 데이터 주파수 변화에 대한 견고성이 크게 향상됨
-
Task 2: Forecasting
- Setup
- C-MAPSS, Bearing 2개의 데이터셋에서 RUL(Remaining Useful Life) 비율을 Regression함
- C-MAPSS는 매우 낮은 Sampling Frequency(1Hz)를 갖는 반면, Bearing은 매우 높은 Sampling Frequency(25.6HZ)를 가져서 이러한 차이점을 통해 다양한 데이터 특성에 걸쳐 모델의 일반화 능력을 더 잘 평가할 수 있음
- MSE와 MAE가 성능 지표로 사용
- Results
-
Linear Evaluation
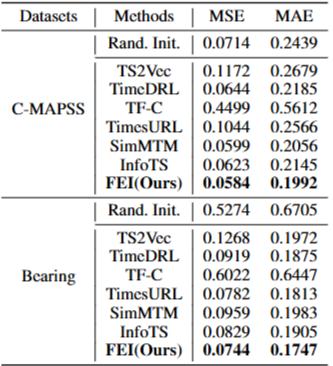
- 제안된 FEI가 회귀 작업에서도 최고의 평균 성능을 달성
- FEI 방법은 명시적인 부정적 샘플 제약 조건을 완전히 버리고 대신 샘플 간의 주파수 대역 특징의 유연한 상관 관계를 설정
-
End-to-end Fine-tuning
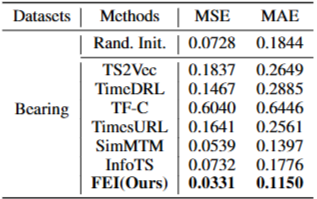
- Bearing 데이터셋의 training sample 수가 적기 때문에 Bearing으로 End-to-end Fine-tuning 실험 수행
-
Model Analysis
Ablation
-
Ablation을 위해 FEI의 핵심 모듈을 대상으로 6개의 Ablation Model을 구성
- emb. infer. : Target Embedding Inference branch를 제거하고 Mask Inference만 유지
- mask prompt. : Target series Embedding Inference를 위한 Mask prompting을 제거
- momentum. : Momentum Encoder를 제거하고 원래 Encoder를 직접 사용하여 인코딩 진행
- subspace. : subspace projector 를 제거하고 원래 임베딩 공간에서 직접 학습
- mask infer. : Mask Inference를 제거하고 Target series Embedding Inference만 유지
- detach. : Gradient Detach 을 제거
-
Results
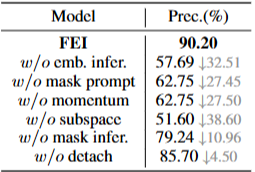
- Momentum Encoder를 제거해도 표현 붕괴가 크게 발생하지 않음
- Mask Inference branch의 설계로 Momentum Encoder가 없어도 심각한 표현 붕괴로 이어지지 않는데, 이는 인코더가 모든 샘플을 동일한 임베딩 벡터로 인코딩하는 사소한 해결책으로는 마스크 추론 브랜치의 손실을 최소화할 수 없기 떄문
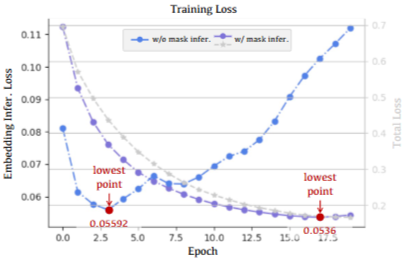
- 마스크 추론은 손실 함수의 표면을 더 평탄하게 만들어 Loss가 더 부드럽게 감소하도록 함
- 그림을 보면 mask infer. 조건에서 더 안정적인 하강을 보이는 것을 확인
- 이는 곧 Mask Inference가 FEI의 일반화 능력에 중요한 영향을 미친다는 것을 의미함
- Momentum Encoder를 제거해도 표현 붕괴가 크게 발생하지 않음
Visualization of embedding inference
-
모델이 시계열의 주파수 대역 변화를 임베딩 공간 내에서 추론하는 능력과 원본 임베딩과 주파수 마스크된 타겟 임베딩 간의 주파수 차이를 추론하는 능력을 시각적으로 입증함
-
Gesture dataset에서 original series sample을 선택하고 random mask를 사용하여 5개의 대표적인 target series를 구성. 주목할 점은 FEI는 Gesture dataset으로 학습한 적이 없어 이를 통해 모델의 일반화 능력을 평가
-
t-SNE를 사용하여 차원 축소 후 원래 임베딩과 타겟 임베딩을 시각화하여 표현
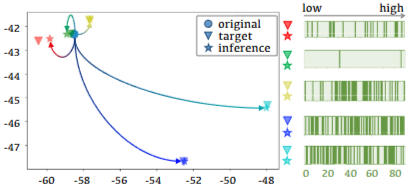
- 왼쪽
- inverted triangles: Encoder 와 subspace projector 를 사용하여 직접 얻은 실제 타겟 임베딩
- stars: Embedding Predictor 에 의해 추론된 임베딩
- circles: 원본 시계열의 임베딩
- 오른쪽
- Target series를 구성하는 데 사용된 5개의 마ㅅ크를 보여주며, 어두운 색상이 마스크된 주파수 성분
- 결과
- 마스크가 가장 적은 타겟 시계열의 임베딩 결과(초록색 역삼각형)과 추론된 임베딩(초록색 별)이 원본 임베딩(원)과 가장 가깝게 위치
- 주로 중고주파수 대역에 마스크가 있는 빨간색과 노란색 타겟 시계열은 원본 임베딩에서 멀리 떨어저 있음
- 마스킹 비율이 가장 높은 청록색 및 파란색 임베딩은 원본 임베딩에서 훨씬 더 멀리 떨어져 있음
- 이러한 결과는 FEI가 이전에 본 적 없는 시계열에 대해서도 임베딩 추론을 정확하게 완료하며, 마스킹된 주파수 대역의 변화에 민감하게 반응하여 임베딩 공간에서 연속적인 의미 관계를 효과적으로 모델링함을 보여줌
- 이는 FEI의 모델링 접근 방식이 인코더가 주파수 변화에 민감한 연속적인 임베딩 공간을 구축하도록 유도하며, 이는 모델의 강력한 일반화 능력의 원천이 됨
- 왼쪽
Masking Strategies
-
다양한 마스킹 전략을 실험
- Discrete Frequency Masking (DFM): 완전히 무작위 frequency band masking
- Continuous Frequency Masking (CFM): 무작위 시작점과 끝점을 사용한 연속 frequency masking
- Time-domain Masking (TDM): series's time domain에서 직접 random masking
-
Frequency-domain masking vs. Time-domain masking
- Frequency-domain masking
- soft information loss가 있는 target series를 생성하고, 여기서 target series와 original series의 의미적 차이는 주파수 마스킹의 위치와 양에 따라 지속적으로 변함
- Time-domain masking
- hard information loss가 있는 target series를 생성하고, 시간 영역에서 의미적 불연속성을 유발
- 유사한 주파수를 가진 데이터셋에서 좋은 성능을 보이지만, 주파수가 다른 데이터셋, 특히 주파수 차이가 큰 FD-B 데이터셋에서는 일반화 성능이 크게 저하
- Frequency-domain masking
-
Results
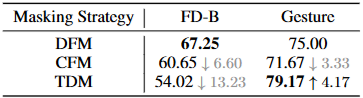
- TDM은 동일한 주파수를 가진 데이터 세트(Gesture)에서 뛰어난 전송 성능을 보여주지만, 사전 훈련 데이터 세트와 크게 다른 주파수를 가진 데이터 세트(EMG, FD-B, Bearing)에서는 전송 성능이 크게 저하됨
- 이는 비연속적 의미 모델링 방법인 시간 영역 마스킹이 동일한 주파수를 가진 데이터로부터 쉽게 전송될 수 있지만 강력한 일반화 능력을 가진 모델을 훈련하는 데 어려움을 겪는다는 점을 시사함
- 이러한 현상은 시계열 모델링에서 샘플 증강 전략(시간 영역, 주파수 영역 처리)를 선택하는 데 새로운 통찰력을 제공하며, 연속적 의미 모델링 방법의 중요성을 더욱 강조
Sensitivity
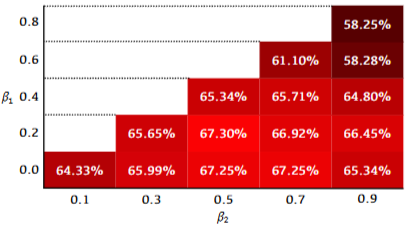
- 다양한 마스킹 비율이 FEI의 성능에 미치는 영향을 추가로 분석
- 을 사용하고, 을 사용
