SPS LAB 2025.07.30 논문 세미나
- 본 내용은 SimMTM: A Simple Pre-Training Framework for Masked Time-Series Modeling 논문을 읽고 정리한 내용입니다.
- 논문 원본은 해당 링크에서 다운받으실 수 있습니다.
Contribution
- 마스킹의 manifold 관점에서 영감을 받아, manifold 외부의 여러 마스크된 Series를 기반으로 원본 시계열을 재구성하는 시계열 모델링을 위한 새로운 작업 제안
- 기술적으로, series-wise representation learning에서 학습된 유사성을 기반으로 재구성을 위해 point-wise representation을 집계하는 효과적인 사전 훈련 프레임워크인 SimMTM을 제시
- SimMTM은 low-level forecasting 및 high-level classification를 포함하여 일반적인 시계열 분석 작업에서 일관되게 높은 성능을 달성함
Introduction
-
Time series Analysis는 financial analysis, energy planning 등 광범위한 응용 분야에서 매우 중요한 역할을 함
-
하지만 시계열 데이터는 사람이 식별할 수 없는 시간적 변화가 많이 있어 라벨을 달기 어렵기 때문에, 이러한 라벨링되지 않은 데이터를 다루기 위해 self-supervised pre-training이 널리 연구되고 있음
-
주로 잘 알려진 사전 훈련 패러다임인 masked modeling은 masked language modeling(MLM) 및 masked image modeling(MIM)와 같은 많은 분야에서 큰 성공을 거두었음
-
본 논문에서는 masked time-series modeling(MTM)으로 확장
- masked modeling의 기본은 마스크되지 않은 부분을 기반으로 마스크된 콘텐츠를 재구성하는 방법을 학습하여 모델을 최적화하는 것
- 그러나 패치나 단어가 많은, 심지어 중복된 의미 정보를 포함하는 이미지 및 자연어와 달리 시계열의 중요한 의미 정보는 주로 trend, periodicity, peak valley와 같은 시간적 변화가 포함되어 있음
- 이러한 비정상적인 결함, 고유한 기상 프로세스와 같은 일부 시간 지점을 직접 마스킹하면 심각하게 손상됨
- 따라서, 시간 지점의 일부를 마스킹하는 것은 원본 시계열의 시간적 변화를 심각하게 훼손하여 시계열의 표현 학습을 유도하는 재구성 작업을 너무 어렵게 만듦
-
stacked denoising autoencoder의 분석에 따르면, 우리는 임의로 마스크된 시리즈를 manifold 외부에서 원본 시계열의 "neighbor"으로 간주할 수 있으며, 재구성 과정은 마스크된 시리즈를 원본 시리즈의 매니폴드로 다시 투영하는 것
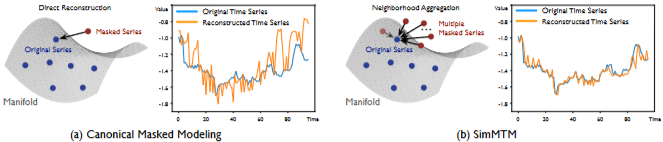
- 직접적인 재구성은 랜덤 마스킹에 의해 필수적인 시간적 변화가 훼손되기 때문에 실패할 수 있음
- manifold 관점에서 영감을 받아, "multiple neighbor", 즉 여러 마스크된 시리즈로부터 원본 데이터를 재구성하는 자연스러운 아이디어를 제안
- 원본 시계열의 시간적 변화가 각 임의로 마스크된 시리즈에서 부분적으로 삭제되었지만, 여러 임의로 마스크된 시리즈는 서로를 보완하여 단일 마스크된 시리즈에서 원본 시리즈에 직접 재구성하는 것보다 재구성 과정을 훨씬 더 쉽게 만듦
-
본 논문에서는, 시계열을 위한 간단하면서도 효과적인 사전 훈련 프레임워크인 SimMTM을 제안
- 마스크되지 않은 부분에서 마스크된 시간 지점을 직접 재구성하는 대신, SimMTM은 여러 임의로 마스크된 시계열에서 원본 시계열을 복구
- 기술적으로, SimMTM은 재구성을 위한 neighborhood aggregation 설계를 제시하며, 이는 series-wise representation space에서 학습된 유사성을 기반으로 시계열의 지점별 표현(point-wise representation)을 집계하는 것
Related Work
Self-supervised Pre-training
- 대규모 데이터에서 일반화 가능하고 공유된 지식을 학습하고 다운스트림 작업에 더 많은 이점을 제공하는 중요한 연구 주제로, Computer vision과 Nature Language Processing에서 널리 탐구
- 대표적으로 Contrastive Learning과 masked Modeling으로 분류할 수 있음
1. Contrastive Learning
- 수동으로 설계된 Positive, Negative Pair를 기반으로 양성 쌍의 표현은 가깝게, 음성 쌍은 서로 멀게 학습하여 표현 공간을 최적화하는 것이 목표
- 예시
- SimCLR: 동일한 샘플의 서로 다른 증강을 양성 쌍으로, 서로 다른 샘플 간의 증강을 음성 쌍으로 간주
- TimCLR: 표현 학습을 시간적 변화와 매끄럽게 연관시키기 위해 DTW를 채택하여 phase-shift(위상 변화) 및 amplitude-change(진폭 변화) 증강을 생성
- TS2Vec: 여러 시계열을 여러 패치로 분할하고 인스턴스별 및 패치별 측면 모두에서 대조 손실을 추가로 정의
- TS-TCC: 증강이 서로의 미래를 예측하도록 하는 새로운 시간적 대조 학습 작업을 제시
- Mixing-up: 두 데이터 샘플을 혼합하여 새로운 샘플을 생성하는 데이터 증강 체계를 활용
- LaST: Variational Inference를 기반으로 latent space에서 seasonal-trend representation을 분리하는 것을 목표로 함
- CoST: discriminative한 seasonal 및 trend representation을 학습하기 위해 시간 및 주파수 영역 모두에서 대조 손실을 사용
- TF-C: 새로운 time-frequency consistency 아키텍쳐를 제안하고 동일한 예제의 시간 기반 및 주파수 기반 표현이 서로 가깝도록 최적화
- 하지만, 대조 학습은 주로 high-level information에 초점을 맞추고, series-wise 또는 patch-wise representation은 본질적으로 Time-series forecasting과 일치하지 않아 본 논문에서는 mask modeling paradigm에 초점을 맞춤
2. Masked Modeling
- Masked modeling 패러다임은 마스크되지 않은 부분에서 마스크된 콘텐츠를 재구성하는 학습을 통해 모델을 최적화
- 이 패러다임은 Computer Vision 및 Natural language processing에서 널리 연구되었으며, 이는 문장의 마스크된 단어와 이미지의 마스크된 패치를 각각 예측하는 것
- 예시
- TST: 일반적인 마스크 모델링 패러다임을 따르고 나머지 시간 지점을 기반으로 제거된 시간 지점을 예측하는 학습을 함
- PatchTST: Local semantic information을 포착하고 메모리 사용량을 줄이기 위해 마스크된 subseries-level patches를 예측할 것을 제안
- Ti-MAE: 마스크 모델링을 보조 작업으로 사용하여 advanced Transformer-based method의 예측 및 분류 성능을 향상
- 그러나, 시계열을 직접 마스킹하면 필수적인 시간적 변화가 손상되어 재구성이 너무 어려워져서 표현 학습을 안내하기 어려움
- 직접적인 재구성 대신, SimMTM은 여러 개의 임의로 마스크된 sereis에서 원래 시계열을 재구성하는 새로운 마스크 모델링 작업을 제시함
SimMTM
Overall Architecture
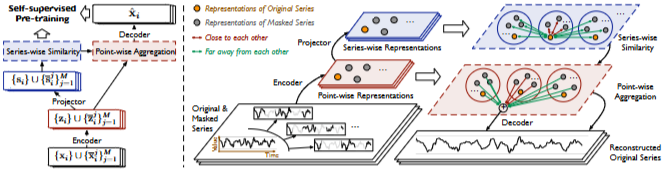
- SimMTM의 재구성 프로세스에는 masking, representation learning, series-wise similarity learning, point-wise reconstruction 이렇게 4가지 모듈로 구성
1. Masking
- 개의 시계열 샘플 로 미니배치가 주어지면, 는 개의 time points와 개의 관측된 변수를 포함
- 각 샘플 에 대해 시간 차원(temporal dimension)을 따라 일부 시점을 임의로 마스킹하여 마스킹된 seires 집합을 쉽게 생성할 수 있음
- = masked portion / M = masked time series의 개수를 의미하는 하이퍼 파라미터
- 마스크된 시점의 값은 0으로 대체
- 개의 입력 시계열 존재
2. Representation learning
- Encoder와 Projection layer를 각각 거쳐, point-wise representation 와 series-wise representation 를 얻음
- Encoder는 입력 데이터를 deep representation으로 project하고, 파인튜닝 과정에서 다운스트림 작업으로 전송될 수 있음. 해당 논문에서는 Encoder를 well-acknowledged Transformer, ResNet을 활용
- Projection layer는 MLP Layer를 시간 차원에 따라 적용하여 series-wise representation을 얻음
3. series-wise similarity learning
- 직접적으로 다수의 마스크도니 시계열을 평균하는 것은 over-smoothing problem을 야기하여 표현 학습을 저해할 수 있음
- 원본 시계열을 정확하게 재구성하기 위해, series-wise representation 간의 유사성을 활용하여 가중치 통합을 진행. 즉, time series manifold의 로컬 구조를 이용
- series-wise similarities를 구하기 위해 다음 수식 활용
- = series-wsie representation space에서 개의 입력 샘플에 대한 쌍별 유사도 행렬이며, 코사인 거리로 측정됨
4. point-wise aggregation
- 학습된 series-wise similarity를 기반으로, 번째 원본 time series의 aggregation 과정은 다음과 같음
- = point-wise representation 와 매칭되는 point-wise representaiton ()
- /: 원본 시계열 의 시리즈 단위 표현 를 제외한 나머지 모든 시계열의 시리즈 단위 표현 집합
- 다른 시계열 표현을 집계하여 모델이 덜 관련된 노이즈 시계열의 간섭을 억제하고 마스킹된 시계열과 원래 시계열 모두에 대해 유사한 표현을 정확하게 학습하도록 유도
- τ = series-wise 유사성에 대한 소프트맥스 정규화의 temperature hyperparameter
- Decoder 후에는 재구성된 원래 시계열 를 얻을 수 있음
5. Self-supervised Pre-training
- 재구성 손실 (Reconstuction Loss)
- 마스크 모델링 패러다임을 따라 재구성 손실을 활용
- 마스킹된 시계열로부터 원본 시계열을 정확하게 재구성하도록 모델을 학습시키는 것
- 제약 손실 (Constraint Loss)
- 재구성 과정이 series-wise similarities에 직접적으로 의존하기 떄문에, series-wise representation space에서 명시적인 제약 조건 없이는 모델이 정확한 유사성을 학습한다고 보장하기 어려움
- 따라서 의미 없는 집계를 피하기 위해 시계열 매니폴드의 neighborhood assumption을 활용하여 series-wise representation space 의 구조를 보정
- 즉, 원본 시계열과 그로부터 마스킹된 시계열은 서로 Positive Pair로 간주되어 표현 공간에서 가깝게 위치해야 하며, 서로 다른 시계열로부터 마스킹된 시계열은 Negative Pair로 간주되어 멀리 위치해야 함. 이를 통해 모델은 시계열 매니폴드의 지역적 구조를 학습함
- 명확성을 위해 Positive 및 Negative Pair를 다음과 같이 정의하여 이웃 가정을 공식화
- Positive Pair:
- Negative Pair:
- 수식
- 최종 손실
- = 아키텍쳐의 모든 파라미터
- = 하이퍼파라미터로, 동분산 불확실성(homoscedastic uncertainty)에 기반하여 적응적으로 조정
- 동분산 불확실성: 데이터 자체에 내재된, 입력 값에 관계없이 고정된 노이즈를 의미. 즉, 아무리 완벽한 모델을 가지고 있더라도 데이터 수집 과정이나 측정 방식 떄문에 필연적으로 발생하는 오차
- 다중 작업 학습(multi-task learning)에서 각 작업의 손실에 대한 가중치를 해당 작업의 동분산 불확실성에 따라 자동으로 학습하는 방법을 제안.
- 어떤 손실의 불확실성()이 높으면 -> 노이즈가 많아 이 손실에 크게 영향을 받기 싫음 -> 손실에 곱해지는 가중치는 이 되어 작아짐
- 이렇게 불확실성의 역수를 가중치로 사용함으로써, 모델은 데이터 자체의 노이즈 수준에 따라 각 손실에 얼마나 '집중'할지 자동으로 조절하여 학습 효율을 높일 수 있음
Experiment
- 두 가지 일반적인 시계열 분석 작업인 forecasting과 classification에 대해 실험을 진행
- in-domain과 cross-domain 설정에서 각 작업에 대한 fine-tuning performance을 제시
- In-domain 설정의 경우, 동일한 데이터셋을 사용하여 모델을 사전 훈련하고 미세 조정함
- Cross-domain 설정의 경우, 특정 데이터셋으로 모델을 사전 훈련하고 인코더를 다른 데이터셋으로 미세 조정함
Settings
Datasets
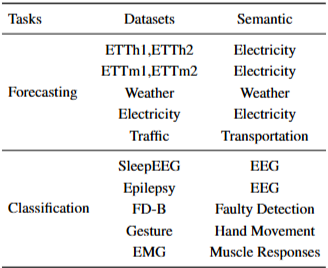
- 12개의 실제 데이터셋 포함
- Forecasting의 경우 Autoformer의 표준 실험 설정을 따랐고 분류의 경우 TF-C에서 제안한 실험 설정을 따름
Baselines
- Contrastive learning methods: TF-C, CoST, TS2Vec, LaST
- masked modeling method: Ti-MAE, TST, TF-C
Unified encoder
- Forecasting: channel independence를 갖춘 vanilla Transformer를 통합 인코더로 채택
- 채널 독립적인 설계를 통해 모델은 다양한 변수 수를 가진 데이터셋 간에 Cross-domain transfer을 수행할 수 있음
- Classification: 1D-ResNet을 통합 인코더로 채택
Main Results
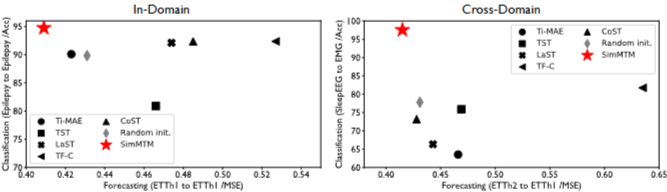
- SimMTM은 다른 Baselines보다 훨씬 뛰어남
- Masking-based method인 Ti-MAE가 Forecasting에서 좋은 성능을 달성하지만 Classification에서는 성능이 낮음
- Contrastive-based method는 low-level forecasting tasks에서 실패
- 이전 방법이 high-level 및 low-level 작업을 동시에 다룰 수 없음을 나타내며, 작업 일반성에서 SimMTM의 장점을 강조
Forecasting
-
In-domain
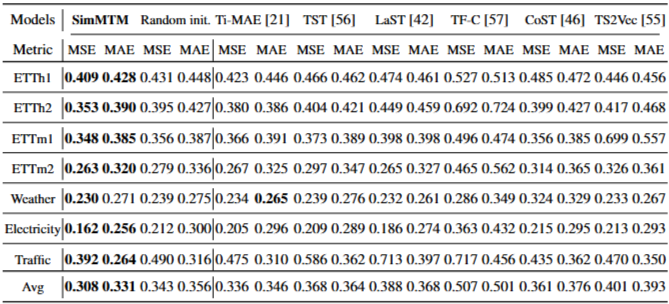
- 모든 벤치마크 데이터셋에서 랜덤 초기화 모델보다 현저히 향상된 성능을 보였으며, 다른 모든 사전 훈련 방법보다도 뛰어난 성능을 달성
- 특히, Ti-MAE보다 MSE 8.3%, MAE 12.0% 감소 / CoST보다 MSE 14.7%, MAE 12.0% 감소를 기록
- 이는 시계열 예측 작업에서 마스크 모델링 기반의 점 단위(point-wise) 재구성(reconstruction)이 시계열 단위(series-wise) 대조 학습 기반 방법들보다 더 유리하다는 점을 시사
-
Cross-domain
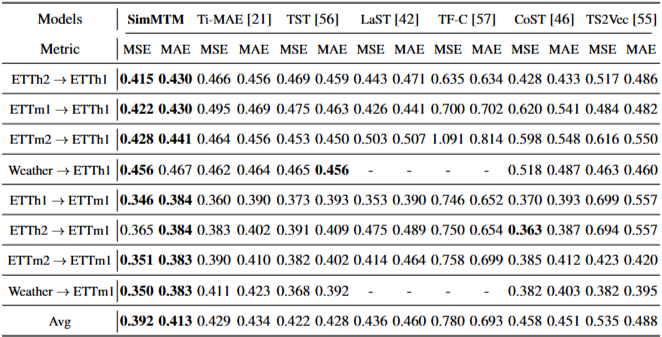
- SimMTM은 교차 도메인 환경에서도 다른 베이스라인을 일관되게 능가하는 성능을 보임
- 이는 SimMTM이 사전 훈련 데이터셋으로부터 가치 있는 지식을 정확하게 포착하여 다양한 다운스트림 데이터셋에 효과적으로 전이할 수 있음을 입증함
Classification
-
In-domain
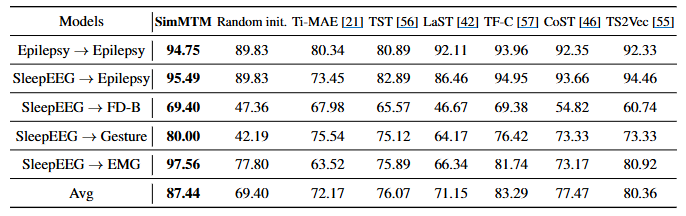
- 일반적으로 Contrastive learrning 기반의 방법론들이 분류 태스크에서 좋은 성능을 보이느 반면, masking modeling 기반의 방법론은 성능이 좋지 않거나 심지어 random initialization보다 낮은(negative transfer) 결과를 보여주기도 함
- 이는 직접 마스킹(masking)이 시계열의 핵심적인 시간적 변화를 손상시켜 표현 학습을 어렵게 하기 때문
- SimMTM은 masked modeling 패러다임을 따르지만, 특별히 설계된 재구성 태스크 덕분에 분류 태스크에서도 우수한 성능을 달성함.
- 이는 여러 개의 마스킹된 시계열로부터 이웃(neighborhood)을 집계(aggregation)하여 시계열 매니폴드의 지역적 구조(local structure)를 활용하기 때문
- 일반적으로 Contrastive learrning 기반의 방법론들이 분류 태스크에서 좋은 성능을 보이느 반면, masking modeling 기반의 방법론은 성능이 좋지 않거나 심지어 random initialization보다 낮은(negative transfer) 결과를 보여주기도 함
-
Cross-domain
- Pre-training dataset과 fine-tuning dataset 간의 큰 차이로 인해, baseline들은 대부분의 경우 성능이 좋지 않지만, SimMTM은 여전히 다른 baseline들과 랜덤 초기화를 능가
- 특히, SleepEEG -> EMG의 경우, SimMTM(97.56%)은 TF-C(81.74%)를 현저히 능가
- 이러한 결과는 SimMTM이 pre-training dataset에서 가치 있는 지식을 정확하게 포착하고 광범위한 downstream dataset에 균일하게 이점을 제공할 수 있음을 보여줌
Model Analysis
Ablations

- 2개의 Training Loss에 대한 Ablations 제공
- 과 모두 최종 성능에 필수적임
- 특히, 보다 가 최종 결과에 더 많은 기여를 한다는 것을 알 수 있음
- 이는 constraint loss가 여러 masked series로부터의 reconstruction에 도움이 되는 적절한 시계열 manifold를 밝혀내도록 설계되었기 때문이며, 이것이 없으면 neighborhood aggregation은 단순 평균으로 퇴화됨
Representation analysis
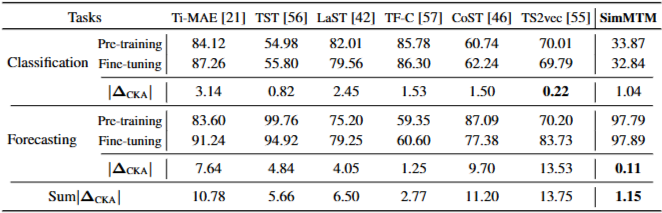
- Classification Task에서 SimMTM의 CKA value가 Forecasting Task의 value보다 작음
- CKA(Centered Kernel Alignment): 신경망의 서로 다른 레이어에서 얻은 표현 간의 유사도를 측정하는 방식으로, 하위 레이어(bottom layer) 표현은 보통 low-level 또는 상세 정보를 포함하므로, CKA 유사도 값이 작다는 것은 상위 레이어가 하위 레이어와 다른 정보, 즉 더 높은 수준의 추상적인 정보를 학습하는 경향이 있음을 의미
- 예측 태스크는 시계열의 미세한 시간적 변화를 정확하게 포착하는 데 중점을 두고, 분류 태스크는 시계열 전체의 고유한 패턴이나 특징을 추출하여 특정 범주로 분류하는 데 중점을 둠
- 그러므로, 분류 태스크가 더 고수준 태스크이고, 예측 태스크가 저수준 태스크
- 는 사전 학습된 모델과 최종 미세 조정된 모델 간의 CKA 값 차이의 절댓값으로, 이 값이 작을수록 사전 학습과 미세 조정 간의 표현 격차가 작아지며, 사전 학습된 표현이 더 강한 보편성(Universality)와 이식성(Portability)를 가진다는 것을 의미
- 즉, 사전 학습된 지식이 특정 태스크에만 국한되지 않고 다양한 하위 태스크(downstream tasks)에 효과적으로 전이될 수 있음을 보여줌
Model Generality
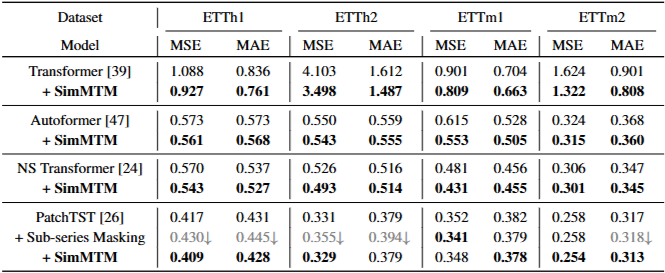
- SimMTM이 다양한 최신 시계열 예측 모델에도 일관되게 적용되어 예측 성능을 향상시킬 수 있음을 입증
- 이러한 일반성은 SimMTM이 시계열 분석을 위한 광범위한 사전 학습 프레임워크로 기능할 수 있음을 시사하며, 더 나아가 인코더로 고급 기본 모델을 사용함으로써 모델 성능을 추가로 향상시킬 가능성을 제공
Fine-tuning to limited data scenario
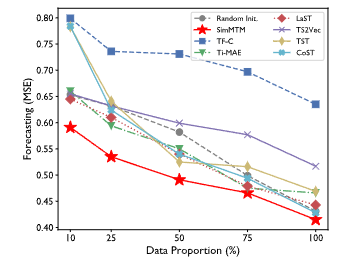
- 사전 학습 모델의 중요한 응용 분야 중 하나가 제한된 데이터 시나리오에서 다운스트림 작업에 대한 사전 지식을 제공하는 것이며, 이는 딥 모델의 빠른 적응에 매우 중요함
- 따라서 데이터가 제한된 시나리오에서 SimMTM 및 기타 사전 학습 방법의 효과를 검증하기 위해 ETTh2에서 모델을 사전 학습하고 훈련 데이터의 나머지 비율에 대한 다양한 선택으로 ETTh1에 대해 파인튜닝 진행함
- SimMTM이 다른 시계열 사전 학습 방법에 비해 다양한 데이터 비율에서 상당한 성능 향상을 달성
- 특히 10% 데이터 파인튜닝 설정에서 SimMTM은 마스킹 기반 방법인 Ti-MAE보다 훨씬 뛰어난 성능을 보임 (MSE: 0.591 vs 0.660)
- 대조 학습 기반 방법인 TF-C와 비교했을 떄 SimMTM은 26.0%의 MSE 감소를 달성
- 이러한 결과는 SimMTM이 데이터 세트에서 가치 있는 지식을 효과적으로 캡처하고 제한된 데이터 시나리오에서도 최종 성능을 향상시킬 수 있음을 추가로 검증
Masking Strategy
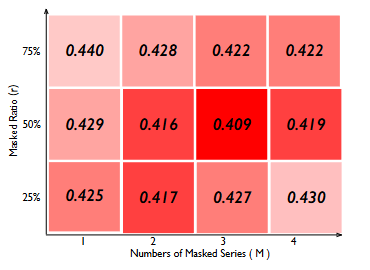
- 마스크 비율()이 증가할수록 원래 시계열을 재구성하는 난이도가 증가하지만, 이웃 마스크 계열의 수()가 증가하면 난이도가 감소
- 실험 결과, SimMTM은 (을 에 비례하도록 설정)할 때 더 좋은 성능을 보임
- 논문에서는 실험적으로 마스킹 비율 50%, 마스킹된 시리즈 개수 3개를 기본 설정으로 사용
특히, (단일 마스킹된 시리즈만 사용)으로 사전학습하는 것이 이 더 클 때 성능이 저하됨을 확인
- 논문에서는 실험적으로 마스킹 비율 50%, 마스킹된 시리즈 개수 3개를 기본 설정으로 사용
Conclusion
- 마스크된 시계열 모델링을 위한 간단한 사전 학습 프레임워크인 SimMTM을 제안
- 마스크되지 않은 시점에서 원래 시계열을 재구성하는 이전의 관례에서 벗어나, 여러 이웃 마스크 계열에서 원래 계열을 재구성하는 새로운 마스크 모델링 작업을 제안
- 구체적으로 SimMTM은 시계열 매니폴드에 대한 Neighborhood assumption에 의해 신중하게 제약되는 series-wise similarities을 기반으로 point-wise representation을 집계
- 실험적으로 SimMTM은 사전 학습된 모델과 파인튜닝된 모델 간의 격차를 최대한 좁혀서 In-doamin 및 Cross-domain 설정을 모두 포함하여 뚜렷한 예측 및 분류 작업에서 일관된 최첨단 기술을 달성함을 확인
