SPS LAB 2025.01.20 논문 세미나
- 본 내용은 UniTime: A Language-Empowered Unified Model for Cross-Domain Time Series Forecasting 논문을 읽고 정리한 내용입니다.
- 논문 원본은 해당 링크에서 다운받으실 수 있습니다.
0. Contribution
- 다양한 time series application domains을 unified model을 사용하여 generalization할 가능성을 탐구하는 첫 시도
- UniTime은 다양한 특성의 시계열 데이터를 처리하고 다양한 도메인을 균형 있게 처리할 수 있는 다재다능한 모델로 제안
- 실험을 통해 UniTime의 효과를 입증함. time series forecasting benchmarks에서 최첨단 성능을 달성하고, unseen domain으로의 transferability를 보임
1. Introduction
- Transformer-based models는 self-attention mechanism을 통해 long-range temporal dependencies를 잘 포착하기 때문에 time series forecasting에 많이 사용됨
- 그러나 기존의 시계열 예측은 Domain-Specific Model을 각각 만들어서 사용했으며, 각 모델은 다른 도메인에는 적용하기 어렵다는 단점 존재
- Cross-domain time series model을 훈련하면 다양한 도메인의 풍부한 데이터를 활용할 수 있으며, 이를 통해 모델은 도메인 간 내재되어 있고 공유되는 commonalities를 학습할 수 있음
- 그러나 unified 모델을 효과적으로 학습하는 것은 기술적으로 까다로우며, 해결해야 할 3가지 과제가 존재
- 다양한 데이터 특성
- 도메인 혼동 문제
- 도메인 수렴 속도 불균형
- 이러한 문제를 해결하기 위해 cross-domain time series data를 효과적으로 학습하기 위한 UniTime을 제안
- 다양한 특성을 가진 시계열 데이터를 처리하는 flexibility을 제공
- human-crafted instruction을 사용하여 explicit domain identification information을 제공함으로써 domain confusion 문제 완화
- 과적합에 취약한 도메인에서 독점적인 데이터 패턴을 암기하는 것과 같은 사소한 솔루션을 model이 획득하지 못하도록 masking을 활용하여 domain convergence speed imbalance 문제 완화
2. Related Work
2.1 Deep Models for Time Series Forecasting
- Deep learning model이 time series forecasting에서 좋은 성과를 보임
- 특히, Transformer-based model이 sequence modeling에서 뛰어난 성능을 발휘하여 널리 인정받고 있지만, Transformer의 self-attention mechanism은 높은 계산 및 메모리 복잡성을 가지고 있음
- LongTrans, Reformer, Informer, Pyraformer는 이러한 cost를 줄이는 것을 목표로 제안
- 다른 연구에서는 복잡한 temporal patttern을 포착하기 위해 제안
- seasonal-trend decomposition (Autoformer, ETSformer, FEDformer)
- non-stationary information compensation (NSformer)
- 최근 더 다재다능한 방법을 개발하기 위해서 노력하는 중
- TimesNet은 여러 시계열 작업을 처리하기 위한 generic framework 제안
- GPT4TS는 사전 학습된 언어 모델을 활용하여 시계열 신호를 처리할 것을 제안
- 특히, Transformer-based model이 sequence modeling에서 뛰어난 성능을 발휘하여 널리 인정받고 있지만, Transformer의 self-attention mechanism은 높은 계산 및 메모리 복잡성을 가지고 있음
- 하지만 앞선 방법들은 domain에 따라 각각 모델을 구축해야 하므로 general time series modeling을 위한 foundation architecture가 될 가능성 제한
2.2 Language Model Powered Cross-Modality Learning
- 최근 recommendation systems, graph learning, time series modeling 등 다양한 분야에 pretrained language model을 활용하는 것에 대한 관심이 급증하고 있음
- InstructRec은 언어 모델이 추천을 생성할 수 있도록 instruction을 활용하여 recommendatation tasks를 text form으로 재구성
- GIMLET은 natural language를 활용하여 task를 설명함. 이를 통해 textual knowledge를 통합할 수 있을 뿐만 아니라 모델이 specific instruction을 사용하여 molecule-related task를 수행할 수 있도록 지원
- GPT4TS는 future를 forecast하기 위해 language model을 활용하는데, 이를 통해 language model로 time series를 처리하는 것에 대한 feasibility를 입증
- 하지만 이는 single modality, 즉 시계열 데이터 자체에 의존하므로 language model이 제공하는 강력한 language precessing capabilities를 활용하는 데는 부족하며, 이는 도메인 간 시계열 학습을 촉진하는 데 중요한 역할을 함
3. Preliminaries
3.1 Problem Definition
domain 에 대한 time step 의 multivariate time series의 관측치
input
output
: domain 에 대한 channel 수
: lookback window
: domain 에서의 future predction range
3.2 Channel-Mixing v.s. Channel-Independence
- 많은 시계열 Transformer 모델은 일반적으로 channel-Mixing을 채택
- embedding layer가 모든 time series channels을 처리하기 위해 활용되며, multi-channel information fusion을 위해 hidden space에 투영
- 하지만 이 설정은 2가지 주요 문제로 인해 여러 시계열 도메인에서 모델을 학습할 때 어려움을 야기
- 다른 시계열 domain 간에 channel 수가 일반적으로 다름
- 의미론적으로 다른 domain의 시계열 채널을 처리하기 위해 공유 embedding layer를 사용하는 것이 비실용적
- 이러한 문제를 해결하기 위해 이 연구에서는 각 channel을 개별적으로 처리하고 domain 간 시계열을 처리하는 데 더 큰 유연성을 제공하는 Channel-Independence를 채택
4. The UniTime Model
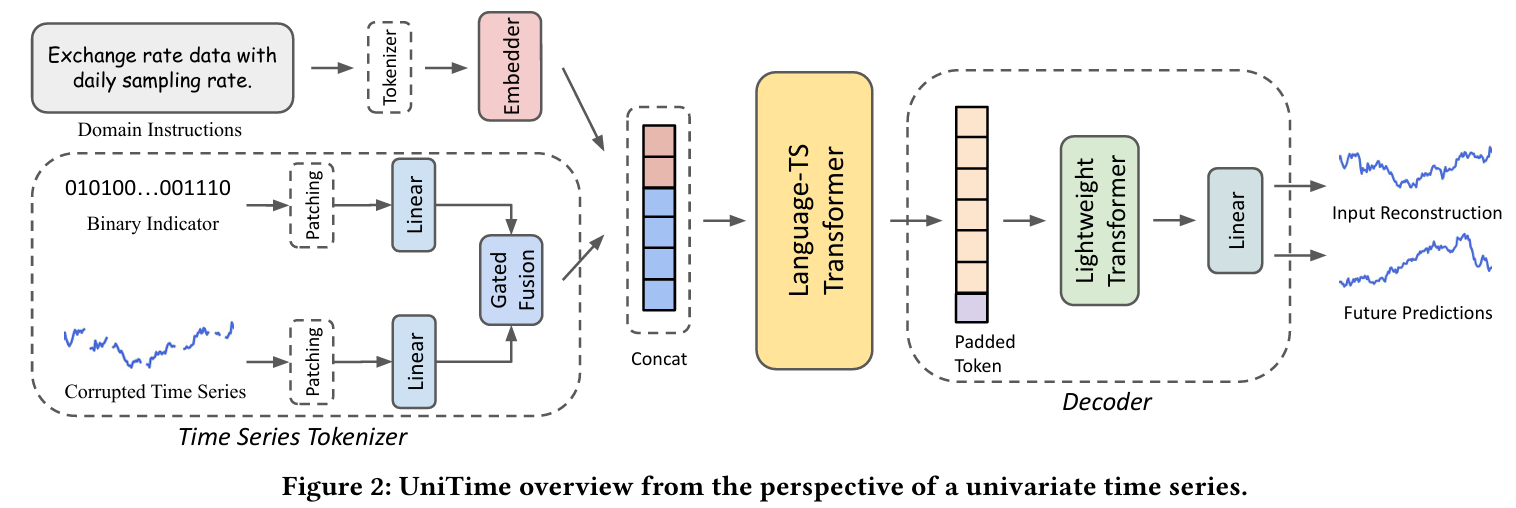
4.1 Time Series Tokenizer
raw series signals에서 time series tokens을 생성하기 위해 time series tokenizer 제시
-
Time Series Patching
-
individual time point는 문장의 단어처럼 충분한 의미를 가지지 않는다는 점을 인식하여 Patching 적용
-
인접한 시계열을 토큰으로 묶어 local sementic information을 포착하고, computational overhead를 줄이는 데 도움을 줌
-
패칭하기 전에 세 단계를 거쳐 raw time series를 전처리
- 0과 1을 포함하는 binary vector로 마스킹
- distribution shift를 완화하기 위해 series stationarization 진행
- 원래 sequence의 마지막 값을 복제하여 적절한 patching을 보장하는 series padding을 진행
-
이후, each univariate time series를 token으로 분할
- : time series token length
- : stride value
- : resulting number of tokens
-
공유되고 학습 가능한 linear projection을 적용하여 각 domain의 token을 hidden space로 임베딩
는 나중에 사용될 Transformer와 일치하도록 설정함
는 linear projection을 사용하므로 고정되고, domain 간 공유됨
는 조정 가능하며, 각 domain의 historical observation lengths에 따라 달라짐
-
-
Masking & Gated Fusion
-
서로 다른 시계열 domain은 고유한 특성에 따라 다양한 수렴 속도를 나타내기 때문에 이를 완화하기 위해 masking을 활용하여 model이 partial input에 의존하도록 함
-
결과적으로 overfitting이 되기 쉬운 domain에서 model trivial solutions을 학습하는 것을 제한하여 robust하고 generalizable한 representation을 얻을 수 있도록 함
-
앞에서 언급한 각 시계열 채널에 대해 먼저 binary mask vector를 생성
- 값 0은 마스킹할 특정 시간 단계를 나타내며, 0의 비율은 매개변수 에 의해 결정
- 마스크 벡터는 raw time series signals을 masking하기 위해 사용되며, 어떤 위치가 masking되는지 모델이 인식하도록 하는 binary indicator 역할을 함
-
binary mask vector는 padding, patching을 거치고, liner projection을 적용하여 hiddden space에 매핑
-
이후 gated fusion operation을 수행하여 해당 정보를 time series tokens과 통합하여 prediction을 생성하는 데 사용
는 learnable parameter임
-
4.2 Language-TS Transformer
-
Motivation
- domain들이 temporal patterns나 distribution에서 큰 차이를 보일 때 발생하여 예측 성능 저하를 초래하는 domain confusion를 해결하기 위해 domain instruction을 사용
- domain instruction은 사람이 작성하여 각 도메인의 데이터를 설명하는 문장으로, 각 time series data의 출처를 식별하고 forecasting strategy를 조정할 수 있도록 domain identification information을 모델에게 제공
- Language-TS Transformer를 활용하여 domain instruction과 time series의 joint representation을 학습하고, 이를 통해 cross-domain generalization을 가능하게 함
-
Model Design
- language와 time series modalities를 통합하기 위해 pretrained language model을 활용. 시계열 데이터의 자기 회귀적 특성(autoregressive nature)을 고려하여 casual masking을 사용하여 input의 temporal order를 유지하는 GPT2을 backbone model로 설정
- casual masking을 사용할 때 input order가 중요. time series를 먼저 배치하면 Transformer는 time series을 처리하는 동안 domain instruction에 접근할 수 없음. 따라서 instructions을 time series 앞에 배치하여 모델이 contextual identifier를 활용하여 도메인 간 예측 성능을 향상시킬 수 있도록 함
-
수식
-
입력 연결 및 위치 임베딩
: domain 의 instruction
: 임베딩 값
: pretrained language model의 learnable positional embeddings
: Language-TS-Transformer의 input으로, domain마다 첫번째 차원이 다를 수 있고 Transformer는 다양한 길이의 입력을 처리하기 때문에 가능 -
Transformer layer
LN: Layer Normalization
MSA: multi-head self-attention
MLP: Multi-layer Perceptron -
casual Attention
C: Casual Matrix
-
4.3 Decoder
Language-TS Transformer의 출력을 받아 최종 시계열 예측을 생성하는 역할을 함
- lightweight Transformer
- Language-TS Trasformer의 출력은 토큰 길이가 도메인마다 다를 수 있고, 뿐만 아니라 predictive length 또한 도메인마다 다를 수 있음
- 이러한 길이 변화는 Decoder에서 Linear Layer를 직접 적용하는 것을 어렵게 함
- 이를 해결하기 위해 최대 토큰 길이 파라미터를 도입하고 learnable padding token을 초기화하여 일관된 sequence length를 가지게 함
- padding token을 추가한 값을 lightweight Transformer의 입력값으로 처리하여 다른 토큰들이 패딩 토큰의 존재를 인식하도록 도움
- lightweight Transformer는 << 이므로 처리하는 레이어 수가 훨씬 적음
- 선형 layer를 통한 예측 진행
- lightweight Transformer의 output을 flatten하고, linear layer를 사용하여 예측값을 생성
- lightweight Transformer의 output을 flatten하고, linear layer를 사용하여 예측값을 생성
4.4 Model Training
-
Training Objective
- 예측값과 실제값 사이의 차이를 측정하기 위해 평균 제곱 오차(MSE)를 사용
- 모델의 예측값이 관측된 과거 추세와 일치하도록 격려하기 위해 미래 값 예측과 과거 기록 재구성을 동시에 수행
-
Training Process
- cross-domain 학습에 대한 간단한 접근 방식은 각 epoch 동안 각 도메인의 학습 세트를 모델에 순차적으로 공급하는 것
- 하지만 이 방식은 unstable learning과 catastophic forgetting을 초래할 수 있음
- 이를 완화하기 위해 batch-level에서의 세분화된 approch 적용
- 모든 도메인의 훈련 데이터를 포함하는 풀에서 무작위로 인스턴스를 선택하여 배치를 구성하지만, 각 배치는 single domain data로 구성됨
- 이는 각 도메인의 채널 수와 시퀀스 길이가 다르기 때문
- 훈련 샘플 수가 적은 domain에 대해서 oversasmpling을 활용하여 샘플 수가 많은 domain에 의해 소외되는 것을 방지하고 model이 샘플 수가 적은 domain에 충분히 노출될 수 있도록 함
5. Experiments
5.1 Experimenal Setup
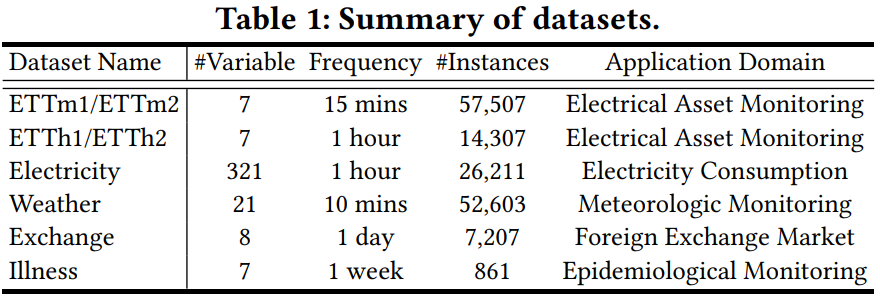
Dataset
- ETT: 2016년 7월부터 2018년 7월까지 전력 변압기(Electricity Transformers)를 모니터링하는 데 사용되는 요소 포함한 데이터셋으로, 4개의 하위 집합(ETTm1, ETTm2, ETTh1, ETTh2)으로 구성.
- Electricty: 2012년부터 2014년까지 321명의 고객의 시간별 전력 소비량을 포함.
- Exchange: 1990년부터 20216년까지 8개국의 일일 환율을 기록.
- Weather: 2020년에 10분마다 기록된 데이터셋으로, 온도, 습도, 강수량과 같은 21개의 기상 지표를 포함.
- Illness: 2002년부터 2021년까지 7가지 독감 유사 질병 환자 수에 대한 주간 기록 데이터 포함.
baseline model
UniTime 모델의 성능을 비교하기 위해 8개의 최첨단 다변량 시계열 예측 방법이 사용.
Informer, Autoformer, FEDformer, NSformer, DLinear, TimesNet, PatchTST
5.2 Main Result
sdsdsdsdsds
5.3 Ablation Studies
UniTime 모델에서 제안된 여러 디자인 요소들의 효과를 검증하기 위해 Ablation Study를 진행.

-
Domain Instruction의 중요성
- w/o instructions 모델의 경우, 모든 데이터셋에서 성능이 크게 저하되었으며, 특히 ETTm1과 Illness 데이터셋에서 큰 폭의 성능 하락 보였음. 이는 모델이 각 시계열 데이터의 출처를 식별하고 적절한 예측 전략을 적용하는 데 Domain Instruction이 필수적임을 보여줌.
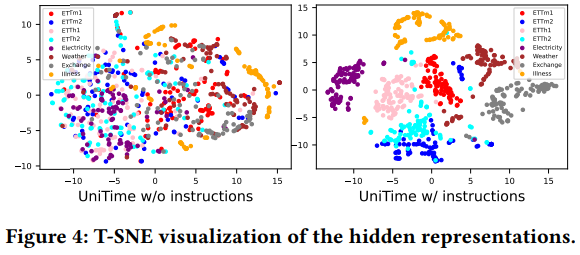
- domain confusion(여러 도메인의 데이터를 잘 구별하지 못하는 문제)를 겪는지 조사하기 위해서 T-SNE 시각화를 통해 w/o instructions 모델과 w/ instructions model의 hidden representation을 확인해 본 결과, Domain Instruction을 사용한 모델에서 각 도메인 데이터가 명확하게 클러스터링되는 것을 확인.
-
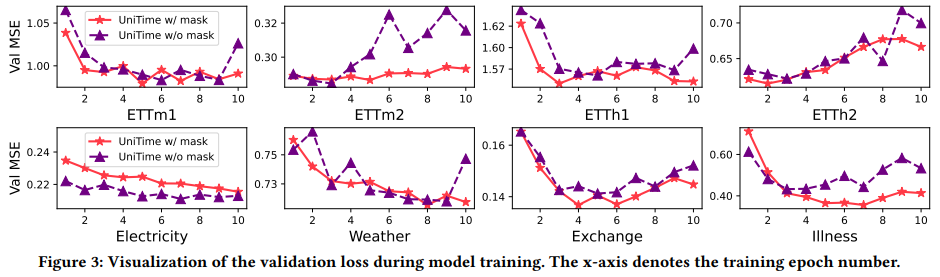
Masking을 통한 안정적인 학습
- Masking을 제거한 모델(w/o masking)은 일부 데이터셋에서 만족스러운 성능을 보였지만, Illness 데이터셋에서는 성능이 크게 저하됨.
- Masking이 없는 경우 각 데이터셋의 검증 손실 곡선이 불균형하게 나타나 모델 선택 과정에 어려움을 야기.
-
Light Transformer와 Reconstruction Loss의 효과
- Light Transformer를 제거(w/o LightTrans)하거나, 과거 히스토리 재구성에 대한 보조 손실 함수를 비활성화(w/o reconstruction)하면 전반적인 성능이 저하.
5.4 Zero-Shot Transferability Analysis
source Domain(training)에서 target Domain(unseen)으로의 방법과 기본 모델의 Transferability에 대해 확인.
-
setup
- Source Domain: ETTh1, ETTm1, ETTm2 데이터셋을 사용하여 모델을 훈련.
- Target Domain: 훈련에 사용되지 않는 3가지 도메인에 대해 zero-shot testing 실행.
- In-domain Transfer: ETTh2 (Source Domain과 동일한 도메인)
- Out-domain Transfer: Electricity (Source Domain과 관련성이 있는 도메인)
- Out-domain Transfer: Weather (Source Domain과 완전히 다른 도메인)
-
Trasfer protocol
- Zero-Shot Transfer를 수행하기 위해서는 Unseen Domain에 적합한 Domain Instruction을 선택해야 함. --> instruction selection protocol 제안.
- historical observations(과거 관측치)를 두 부분으로 나누어 첫 번째 부분은 prediction을 generate하기 위해 model input으로 사용하고, 두 번째 부분은 forecasting loss 계산에 사용.
- 해당 loss를 기반으로 어떤 Instruction이 Unseen Domain에 가장 적합한지 판단.
-
Results
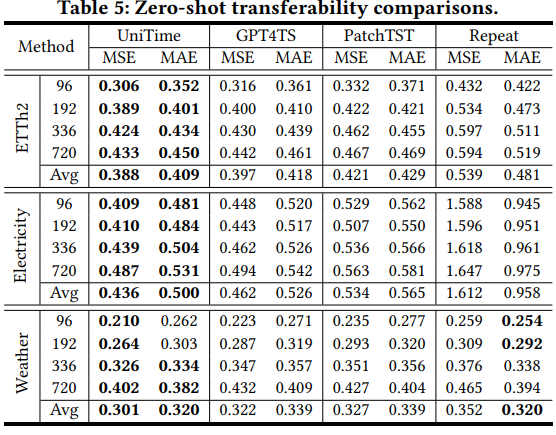
- UniTime 모델은 대부분의 경우에서 baseline 모델들을 능가하며 뛰어난 Zero-Shot Transferability 성능을 보임.
- 3가지 Zero-Shot 데이터셋 모두 ETTh1 데이터의 Instruction을 선택.
- ETTh2는 ETTh1과 strong connection을 가지므로 선택.
- Electricity와 Weather 데이터셋 또한 ETTh1의 Instruction을 선택한 것은 similar underlying patterns을 공유하고 있기 때문으로 해석.
- UniTime 모델이 다양한 도메인에 대해 adaptability를 가진다고 해석 가능.
5.5 Exploration Studies on Language Models
언어 모델과 관련된 요소에 대해 추가적인 조사 진행.

- input order
- time series data를 insturction 앞에 배치하여 입력 순서를 변경하는 효과 확인
- time series token은 casual mask의 존재로 인해 instruction token에 참여할 수 없음
- Unitime이 변경했을 때보다 성능적으로 더 우수함을 확인
- 성능의 차이는 Language-TS Transformer 다음에 decoder를 사용하기 때문인데, 이 디코더는 지침 토큰의 정보를 사용하여 예측을 생성하여 변경된 입력 순서의 영향을 완화
- time series data를 insturction 앞에 배치하여 입력 순서를 변경하는 효과 확인
- Initialization
- GPT-2의 사전 훈련된 가중치를 사용하지 않고 무작위로 초기화된 가중치 선택
- 기본 모델보다 성능이 대체로 낮은 걸 확인할 수 있음. 이는 방대한 언어 코퍼스에서 학습된 사전 훈련된 가중치가 텍스트 정보를 효과적으로 처리하는 데 우수함을 나타냄
- Tunability
- Pretrained language model의 tuning을 진행
- Freeze PLM: 전체 언어 모델을 고정
- FPT PLM: 언어 모델의 대부분 매개변수를 고정 (positional embedding과 layer normalization components만 조정하고, self-attention, feed-forward network 등의 요소는 고정된 상태로 유지)
- Pretrained language model의 tuning을 진행
- fully tuning의 경우가 FPT, Freeze의 경우보다 best performance를 얻음
- 전체 언어 모델을 고정하더라도 성능이 비교적 높음
- language model이 time series token을 처리하고 합리적인 hidden representationn을 생성할 수 있는 기능을 가지고 있음을 시사
- FPT 방법에서 parameter의 작은 subset만 조정해야 한다는 점을 보면 performance와 effficiency 사이의 good balance를 가지고 있음
- 이는 계산 리소스가 제한적일 때 고려할 수 있는 요소가 될 것으로 보임
6. Conclusion
- 다양한 time series application domains을 수용할 수 있는 unified forecasting model을 개발하기 위해 새로운 패러다임인 UniTime을 제안
- 광범위한 평가를 통해 UniTime이 최첨단 forecasting performance와 zero-shot transferability을 향상시키는 데 효과적임을 확인
- 이 연구가 general time series forecasting의 foundation model을 구축하기 위한 중요한 단계라고 생각함
