Pipelining
저번 포스트에서 성능을 획기적으로 향상시키는 방법이 있다고 하였는데, 그것이 바로 pipelining입니다.
pipelining의 기본적인 컨셉은 '동시에 여러가지 일을 처리하자.' 입니다. 집안일을 한다고 가정해보겠습니다. 세탁기가 빨래를 해주고, 로봇청소기가 청소를 해주며, 식기세척기가 설거지를 하고, 직접 화장실 청소를 해야한다고 가정해보겠습니다. 각 일들은 1시간이 소요됩니다.
이 때 두가지 선택지를 드리겠습니다.
-
세탁기 돌리고 끝날 때 까지 기다렸다가 로봇 청소기 돌리고 끝날 때 까지 기다리고 식기 세척기 돌리고 설거지 기다리고 그 다음에 직접 화장실 청소까지 하기 (4시간 소요)
-
세탁기 돌려 놓고 그동안 로봇 청소기 돌리고 그동안 식기 세척기 돌려 놓고 화장실 청소하기 (1시간 소요)
남들보다 하루가 4배나 길어서 96시간이 하루인 사람이 아닌 이상 2번을 선택할 것입니다.
이게 파이프라이닝으 기본 개념입니다. 동시에 할 수 있는 일은 동시에 처리하기.
Basic Steps of Execution
RISC-V에선 기본적으로 이 해야 할 일이라는 것을 5개로 나눕니다. 위의 예시에서 건조기 돌리기 정도를 추가하면 대충 맞겠네요.
아무튼 각각의 일들을 pipeline stage 혹은 pipeline segment 라고 부릅니다. 또한 각각의 stage들은 차례대로 수행됩니다. 쉽게 말하면 아무리 빠르게 기기들을 작동을 시킨다고 해도 세탁기, 건조기, 로봇청소기, 식기세척기를 작동 시키는 순서는 있다는 겁니다. 정확히 동시에 할 수는 없으니까요.
RISC-V에서 5개의 단계는 순서대로 아래와 같이 나타납니다.
- IF: Fetch Instruction (메모리로부터 명령어를 가져옴)
- ID: Decode Instruction (명령어를 해석하고 레지스터를 읽음)
- EX: Execute (연산을 수행하고 주소를 계산함)
- MEM: Access Memory (메모리에 접근)
- WB: Write Back (결과를 레지스터에 작성)
기본적인 구조는 이렇지만, CPU에 따라 더 자세하게 나눌 수도 있습니다.
Performance
파이프라이닝의 성능을 가장 잘 나타내는 그림이 있습니다.
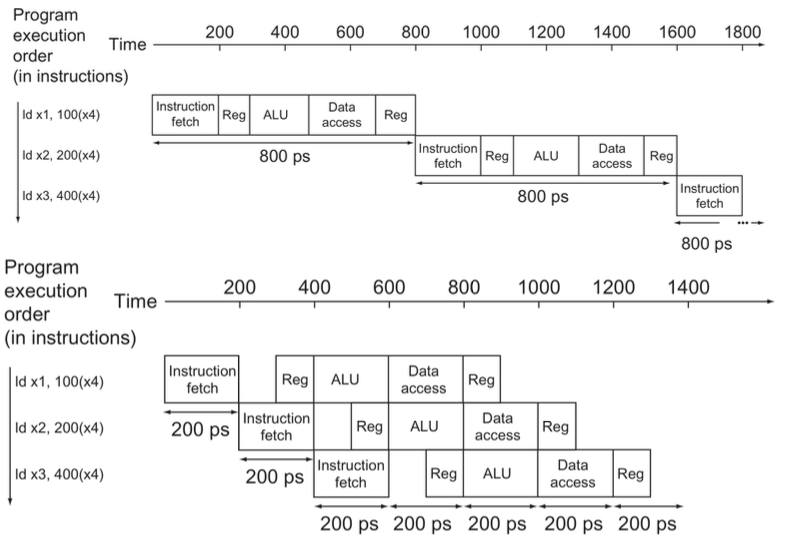
파이프라이닝을 하지 않았을 때는 3개의 ld 명령어를 처리하는 데에 2400ps가 걸렸고, 파이프라이닝을 한 경우에는 1400ps가 걸렸습니다. 대충봐도 파이프라이닝을 하는 게 훨씬 낫다는 것을 알 수 있습니다.
하지만 우리는 여기서 잘 봐야할 것이 있습니다. Troughput과 Latency의 차이입니다.
Throughput은 에서 으로 비약적인 향상을 이뤄냈습니다.
Latency는 어떤가요? 원래 하나의 Instruction을 수행하는데 800ps가 걸렸지만, 파이프라이닝을 하면 1000ps가 걸리는 것을 볼 수 있습니다. 오히려 나빠졌죠.
이는 파이프라이닝의 특성 때문인데, 하나의 stage에서 걸리는 시간은 가장 느린 stage에 맞춰주어야합니다. 위의 예시에서만 보아도 두번째 Reg를 앞으로 당기면 ALU 2개가 겹치게 되고, 이러면 파이프라이닝이 되지 않습니다. 이를 방지하기 위해 시간을 통일하는 것입니다.
ISA Desgin
RISC-V에서는 파이프라이닝을 위해 3가지 기준을 잡고 설계했습니다.
-
모든 명령어는 32bit
-
명령어 형식은 적고 일반화
-
주소 계산과 메모리 접근을 별도의 단계에서 수행
