Multi Cycle Implementation
저번 포스트에서는 single cycle implementation에 대해 알아보았습니다. 이는 한 사이클에 반드시 한 명령어를 처리하기 때문에 단순하고 간단하다는 장점은 있지만, 단점이 2개 있습니다.
-
하나의 clock cycle에 다 처리를 해야하므로 필연적으로 slowest time에 모든 cycle time이 맞춰지게 됩니다.
-
불필요하게 자원을 중복해서 사용합니다.
이를 해결하기 위한 방법이 Multi Cycle Implementation이며 이는 3가지 특징을 가집니다.
-
하나의 명령어를 작은 단계들로 나눔
-
나눠진 작은 단계들은 하나의 clock cycle을 소모
-
명령어마다 cycle 수를 다르게 지정 ex) R-type: 4cycles, Load: 5cycles
아래 그림을 보면 쉽게 이해할 수 있습니다.
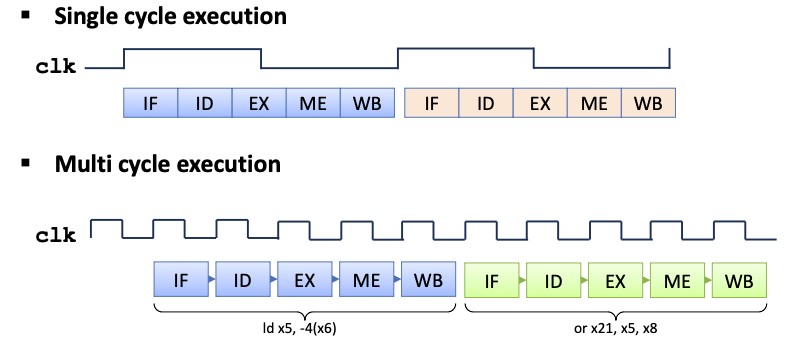
Concept
multi cycle의 전제는 아래와 같습니다.
-
한 사이클에 단일 자원만을 사용해서 자원 사용량을 줄임
-
연산 결과를 다음 단계로 전달하기 위해 임시 레지스터를 사용
-
한 번에 하나의 주요 작업을 함
CPI
multi cycle도 단점은 존재합니다. CPU의 performance를 결정하는 것 중 하나는 CPI(Instruction 당 소모하는 clock cycle의 수)가 있습니다. cycle time을 줄였지만, CPI가 늘어났기 때문에 마냥 성능이 향상 됐다고는 할 수 없습니다.

하지만 이걸 기반으로 성능을 획기적으로 향상 시킬 수 있는 방법이 있는데, 이는 다음 포스트에서 작성하도록 하겠습니다.

Just do it.