영속성 컨텍스트
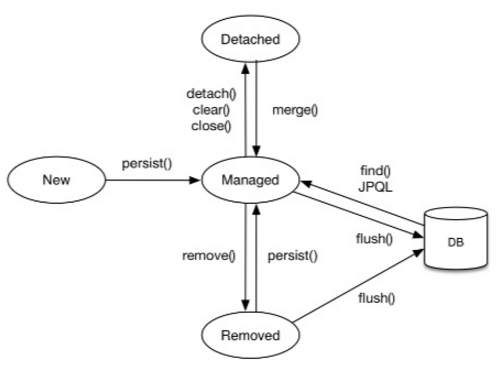
영속화
- 데이터를 영속화(to Managed State)하는 방법은 3가지가 있다.
persist()merge()find()
find()는 말 그대로 DB에서 데이터를 조회하는 경우이다.persist()는 우리가 일반적으로 생각하는 "저장"이다.merge()는 준영속 상태에서 다시 영속 상태로 변경하는 것이다. 이는 잘 이루어지지 않는 작업으로 직관적으로 이해하기 힘들다.
준영속
detach(),clear(),close()를 통해 준영속 상태로 변경할 수 있다.detach()는 명시적으로 준영속 상태로 만드는 작업이다. (실제로는 거의 사용할 일이 없다)clear()와close()는 영속성 컨텍스트가 초기화 되었거나, 종료되는 경우이다.- 영속성 컨텍스트의 종료는 트랜잭션의 종료를 생각하면 어렵지 않게 이해할 수 있다.
- 영속성 컨텍스트가 종료되지 않고 초기화 되는 경우는 다음과 같은 예시를 생각해볼 수 있다. 예를 들어,
@Modifying을 사용하는 경우 컨텍스트 꼬임을 방지하기 위해 컨텍스트를 clear 해줘야 하는데 이럴 때 초기화가 이루어지면서 영속성 컨텍스트에 있던 객체들이 준영속 상태가 된다.

merge()
- merge 를 단순하게 이해하자면, 이미 저장되어 있는 객체를 영속성 컨텍스트에 다시 올리는 작업이다.
- 이미 저장된 데이터는 일반적으로 find() 를 통해 영속화 되므로 merge() 가 호출되는 일은 거의 없다.
- 하지만, 컨텍스트가 종료된 이후(트랜잭션 관리를 잘못한 경우가 대부분) 다시 해당 객체의 변경사항을 저장하고자 하는 경우, merge()가 수행되어야 한다.
Data JPA 의 Merge
- 의외로 실무에서 merge 는 생각보다 굉장히 빈번하게 일어난다.
- "Data JPA + 자연키" 의 조합이 merge 를 유발하기 때문이다.
자연키, 인조키
- 실제 데이터의 속성 값을 키로 사용하는 것을 자연키라고 한다.
- ex. 회원ID, 계좌번호 등
- 실제 데이터와 무관하게 키로 사용하기 위한 새로운 값을 만들어 사용하는 것을 인조키라고 한다.
- ex. sequential 하게 증가하는 ID, UUID 등
Data JPA 의 isNew()
- 대부분 Data JPA 를 사용하며 데이터를 저장하는 경우 자연스럽게 Data JPA 의
save()를 호출한다. - 자연키를 사용하는 경우, 이 때
merge()가 호출된다. - 이는 Data JPA 가 객체가 신규 객체인지(비영속), 이미 존재하던 객체인지(준영속) 판단하는 로직 때문이다.
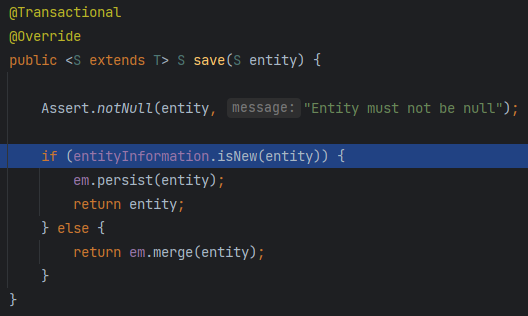
- 위 코드는 Data JPA의
save()구현체이다. - 객체가 새로운 객체인지(비영속 상태인지) 판단하여, 새로우 객체(비영속 상태)라면
persist()를 호출하고, 새로운 객체가 아니라면(준영속 상태라면)merge()를 호출하게 되어있다.
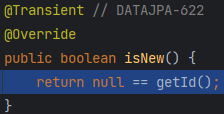
- 그리고
isNew()는 기본적으로 Id 가 null 인지 여부를 통해 판단된다. - 인조키의 경우 객체가 저장되는 순간 Id 가 생성되므로, Id 의 유무를 통해 객체의 신규 여부를 판단하는 것이 적절하다.
- 하지만, 자연키를 사용하는 경우 신규 객체도 Id 를 가지고 있다. (필수 속성이다.)
- 결국 자연키를 사용하는 경우
save()를 호출할 때마다isNew() = false이며 항상merge()가 호출된다.
merge 의 동작
merge()가 실행되면, JPA 는 준영속 상태의 객체를 영속 상태로 만들고자 시도한다.- 이를 위해, 1차 캐시에서 해당 엔티티를 조회하려고 시도하고, 없다면 데이터베이스에서 해당 엔티티를 조회하여 영속성 컨텍스트로 로딩한다.
- 위에서 언급한
save()의 경우에는 당연히 1차 캐시에 해당 객체가 없을 것이며, 데이터베이스에서 조회를 시도하게 된다.- 이 때, select 쿼리가 발생하게 된다.
- 데이터베이스에도 데이터가 없을 것이므로, JPA 는 해당 엔티티를 insert 하며 영속성 컨텍스르에 올린다.
- 정리하면 자연키를 사용하는 경우, persist 가 아닌 merge 를 통해 insert 가 수행되며, 그 과정에서 불필요한 1차 캐시 조회와 select 쿼리가 발생하게 된다.
Persistable
- 신규 객체를 저장하고 싶은 경우, persist 가 호출되는 것이 더 효율적이며 적확하다.
- 따라서 자연키를 사용하는 경우에도 persist 가 호출되는 것이 가능하도록 만드는 방법이 있다.
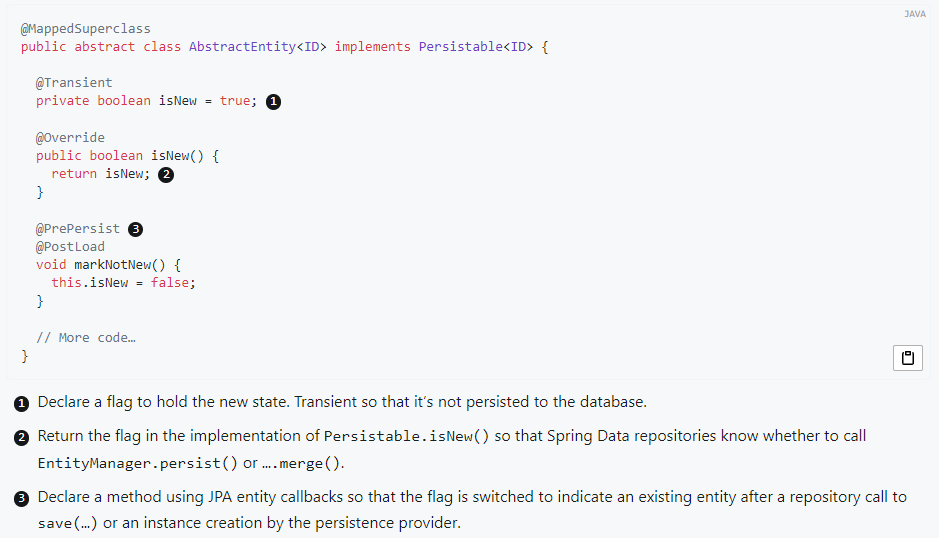
- Data JPA 공식 문서에 나와있는 Persistable 관련 내용이다.
- Persistable 인터페이스를 구현하면,
isNew()메서드를 오버라이드 할 수 있다. isNew()를 구현할 수 있는 방법은 다양하지만, 권장되는 방법은 위와 같다.isNew라는@Transient필드를 만들고, 초기값을 true 로 설정한다.@Transient어노테이션으로 인해, 해당 필드는 실제 DB 에 저장되지는 않는다.@PrePersist및@PostLoad를 통해 조회될 때, 그리고 persist 될 때isNew값을 false 로 만든다.
- 이렇게 하면 신규 객체를 새로 만들어 저장하는 경우, 초기값이
true이므로isNew()가 true 가 응답되어 persist 가 호출된다. - 기존 객체를 조회하는 경우
@PostLoad로 인해isNew()가 false 가 되어,save()가 호출되는 경우 persist 가 아니라 merge 가 호출된다. - 마찬가지로 이미 persist 된 객체가 다시 save 되는 경우
@PrePersist로 인해 merge 가 호출된다. - 이를
@MappedSuperclass로 만들면 이 객체를 extends 해서 쉽게 자연키 엔티티들에게 Persistable 을 공통 적용할 수 있다.
@PostPersist 가 아니라 @PrePersist 인 이유
- 개인적으로 위 내용을 보았을 때, 이와 같은 의문이 들었다.
- 왜 PostPersist 가 아니라 PrePersist 일까?!
- persist 이후 isNew 가 false 가 되어야 한다는 사실에는 이견이 없다.
- 다만, persist 이전에는 isNew 가 true 여야 한다..!
- PrePersist 면 persist 이전에 isNew 값이 변경되는 게 아닌가..?
결론적으로 Data JPA 의 공식 문서가 옳다.
@PostPersist 가 아니라 @PrePersist 를 사용한 이유는, 두 어노테이션의 실행 시점 차이 때문이다.
isNew()가 실행되는 시점은 persist 이전 persist/merge 를 구분하는 시점이다.@PrePersist가 실행되는 시점은 persist 가 호출되기 직전이다.- 따라서
@PrePersist를 통해 isNew 필드의 값을 바꿔줘도 아무런 문제가 없다.
반면,
@PostPersist가 실행되는 시점은 persist 된 객체가 flush 될 때이다.- 따라서
@PostPersist를 사용하는 경우 "persist 이후, flush 이전" 타이밍에 의도와는 다르게 동작할 수 있는 위험이 있다!
번외
실무에서 종종 객체 update 를 위해 의도적으로 merge 를 호출하는 경우도 보게된다.
- 개인적으로 좋은 방법은 아니라고 생각한다.
- update 를 위해 merge 가 호출되는 경우, 해당 객체를 select 한 후 값을 변경해 영속성 컨텍스트에 객체를 올린다.
- 그리고 flush 시점에 dirty checking 을 통해 update 가 수행된다. (결과는 의도와 같다.)
- 하지만, 이 경우 다음과 같은 문제가 있다.
- merge 를 통해 객체의 모든 값이 변경된다. 즉, merge 를 호출하기 전 변경하고 싶은 값을 포함해 모든 값을 채워넣어야 한다.
- 결국 기존 값을 채워 넣으려면 대부분의 경우 select 가 필요한데, select 시 영속성 컨텍스트에 객체가 올라가고, 이 객체에서 변경하고 싶은 값만 바꾸면 dirty checking 이 일어난다.
- 굳이 새로 객체를 만들어 merge 를 해야할 이유가 없다.
- JPA 의 철학에서 update 는 dirty checking 을 통해 일어나야 한다. 웬만하면 dirty checking 을 사용하자.
- bulk update 의 경우는
@Modifying어노테이션을 활용하자.

더 빠르게 더 많이 성장하고 싶은 개발자입니다