Intro
오늘 화이자 백신을 맞고 3~4시간 동안 자다가 일어났다. 백신을 핑계로 포스팅을 미룰까 하다가 CV 첫날부터 미루는 것은 아닌 것 같아서 포스팅을 시작한다.
1. Data augmentation
Dataset is always biased
이 세상에서 모든 데이터를 얻을 수는 없다. 우리는 항상 편향된 데이터만을 얻게 된다. 인터넷에 공유된 사진들은 모두 밝은 조명아래에서 최상의 각도로 촬영되었다. 하지만 실제 데이터들, 우리가 분류하고자 하는 데이터들은 그렇지 않다.
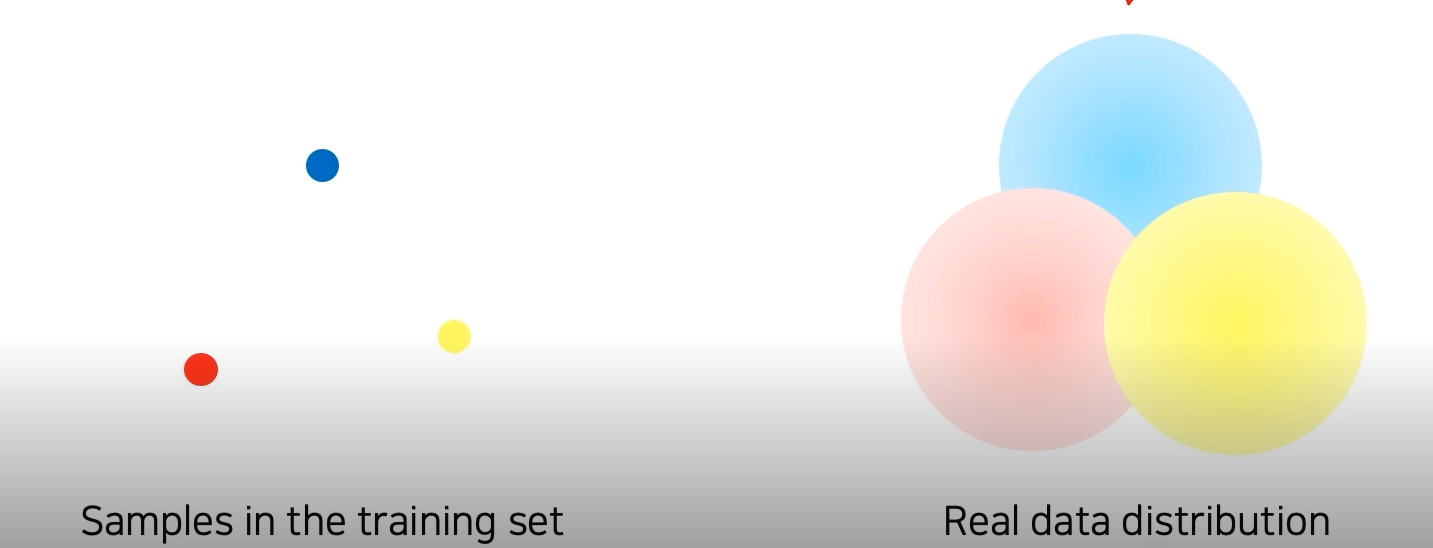
왼쪽이 우리가 샘플링한 데이터고 오른쪽이 실제 데이터 distribution 이다.
어떻게 하면 real data와 sampled data 사이의 gap을 줄일 수 있을까?
-> 정답은 바로 data augmentation이다.
Brightness adjustment
데이터 augmentation에는 여러가지 종류가 있다. 우리가 학습시키고자 하는 dataset은 높은 확률로 물체가 선명하게 잘 보이는 밝기에 촬영된 data일 확률이 크다. 하지만 실제 data들은 그렇지 않다. 그렇기 때문에 밝기를 조절하는 변화도 중요하다.
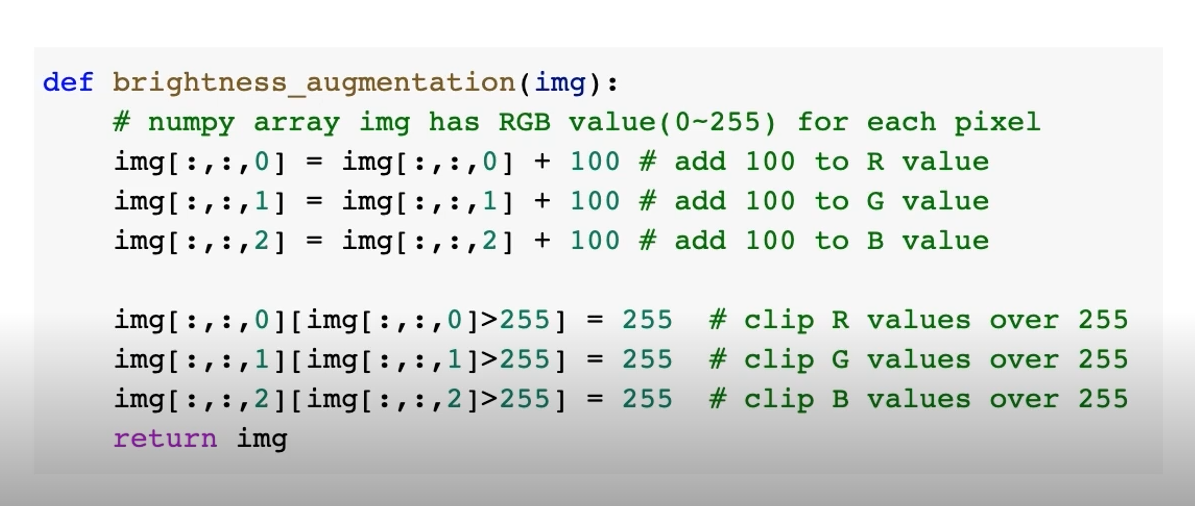
이미지에 일정 숫자를 더해준다.
그후 255 보다 큰 값을 255로 조정해준다. 이렇게 색상 normalization을 해준다.
Roate, flip
Crop

Affine transformation

선은 선으로 변화되고 평행과 비율을 유지시켜 준다.
기하학적으로 영상을 비틀거나 회전하거나 픽셀의 위치를 옮기는 것을 warpping 이라고한다.
cutmix

-> augmentation을 통해 전혀 다른 데이터셋을 만들어 낼 수 있다.
augmentation에는 2가지의 parameter가 있다.
1. 어떤 augmentation을 적용할까?
2. 얼마나 세게 augmentation을 적용할까?
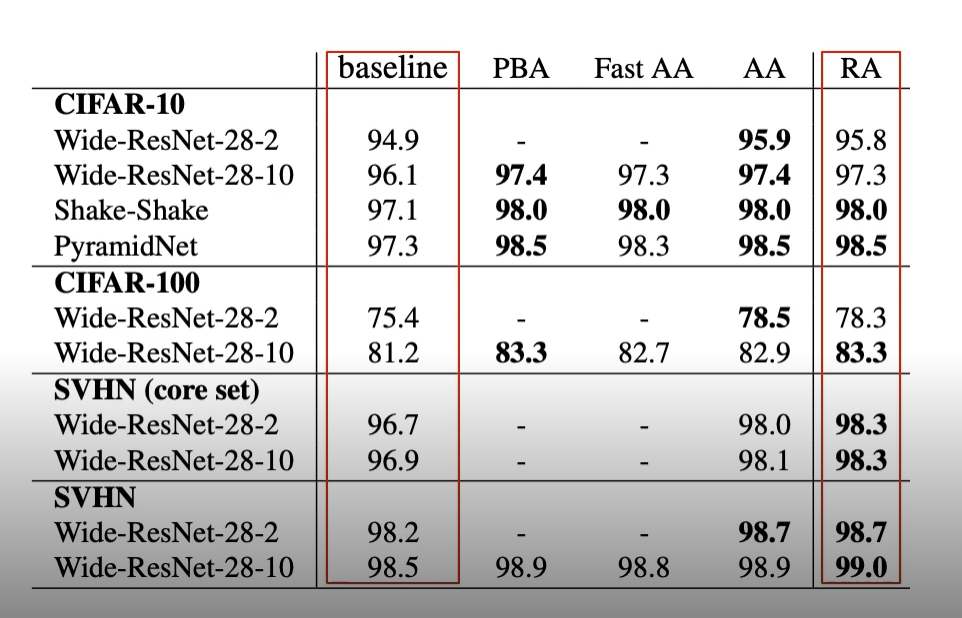
data augmentation을 적용하면 대부분의 경우에서 성능이 향상되는 것을 발견 할 수 있다.
2. Leveraging pre-trained information
Transfer Learning (Fine-tuning)
인공지능 딥러닝 모델에게 데이터를 학습시킬 때 어마어마하게 많은 데이터가 필요하다는 것은 저명한 사실이다.
Transfer Learning은 한 데이터셋에서 배운 지식을 다른 데이터셋에서 활용하는 것이다. 그럼 이러한 transfer learning 이 가능한 이유는 뭘까?
Transfer Learning은 데이터셋 끼리 서로 공통된 요소가 많지 않을까? 라는 가정에서 시작되었다.
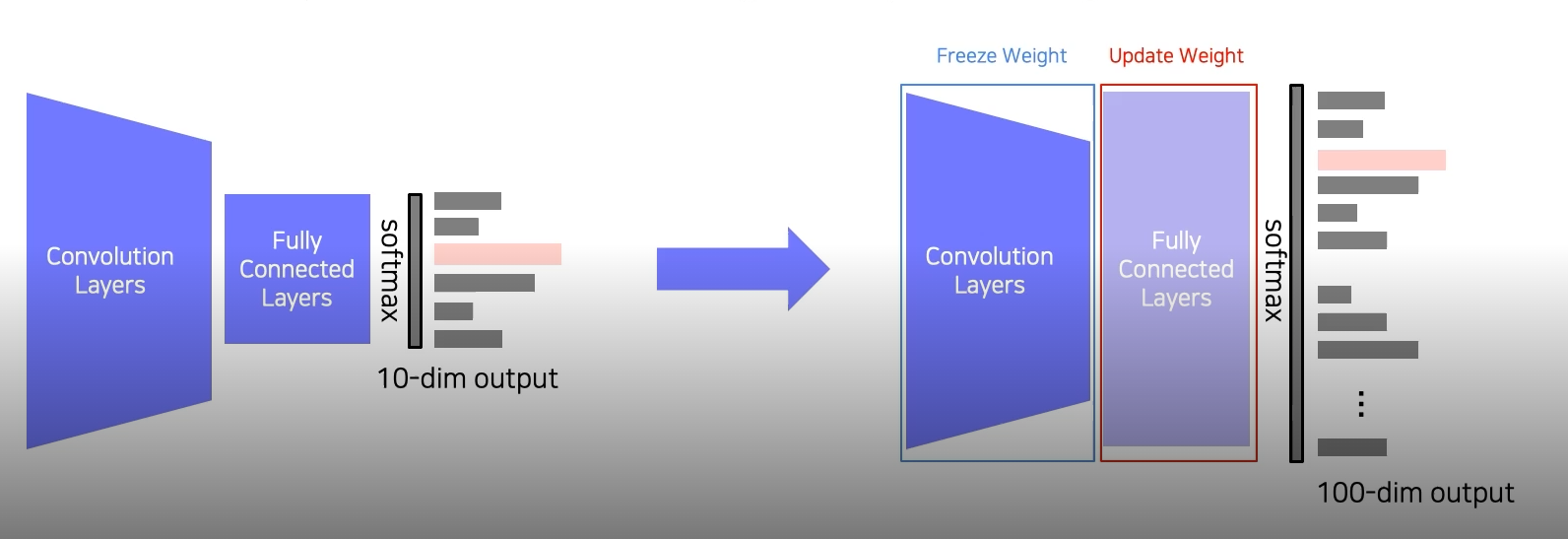
Transfer Learning은 주로 위의 사진처럼 Fully Connected(FC) Layers의 변경으로 이루어진다. Convolution Layers는 freeze(backpropagation 시 parameter들의 변동 x)시키고 fc layers를 원하는 학습의 class 수에 맞춰서 dimension을 변경해준다. 이것이 기본적인 Fine-tuning의 형태이다.
Fine-tuning the whole model
Fine tuning the whole model 도 마찬가지로 pre-trained 모델을 준비한다. Transfer Learning과의 차이점은 Convolution Layers를 학습시킨다는 것이다. 대신 Convolutional Layer의 부분은 적은 learning rate로 학습되고 새롭게 변경된 Fc lyaers는 높은 learning rate로 학습된다. 또한 기존의 Transfer Learning 보다는 더 많은 데이터 셋이 요구된다.
Knowledge distillation
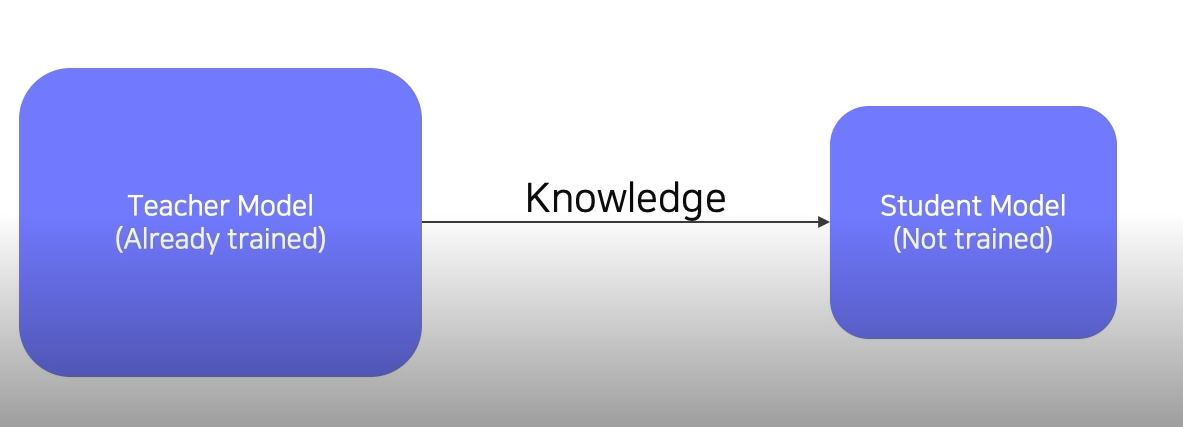
Knowledege distillation은 Teacher-student learning이라고도 부른다.
Knowledege distillation은 큰 모델이 작은 모델을 학습시키는 방법으로 이루어진다. 주로 model compression에서 많이 사용된다. 최근에는 pseudo-labeling(라벨링이 되지 않은 데이터셋에 모델을 통과시켜 라벨링을 부여하는것)에서 많이 사용된다.
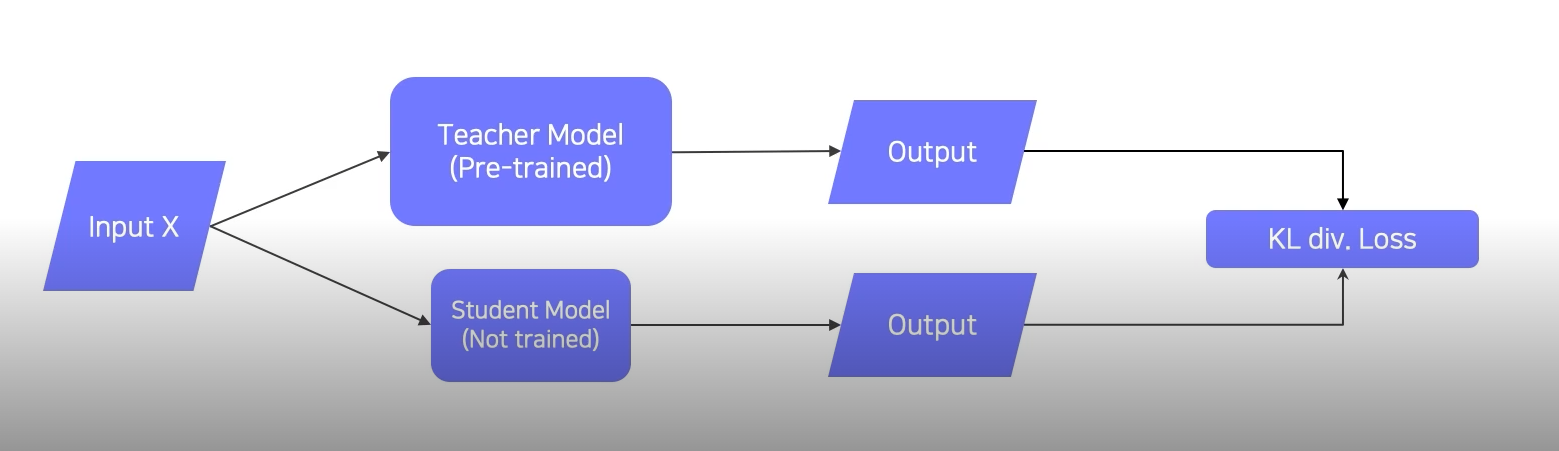
위의 그림이 일반적인 knowledge distillation의 모습이다. 우선, teacher 모델과 student 모델에 같은 input을 넣어서 loss를 KL div로 비교한다. 그 후 back propagtion을 통해서 student model만 학습시킨다.
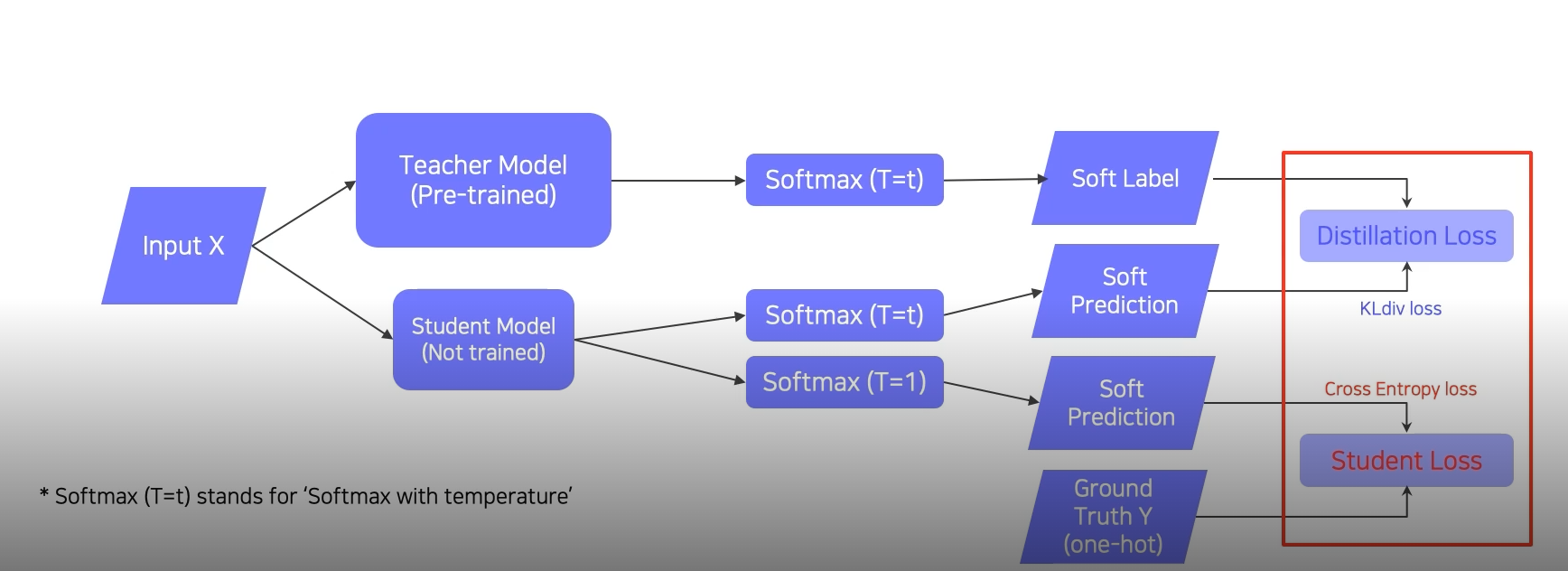
labelling이 된 dataset을 통해 knowledge distillation을 하는 경우는 Distillation Loss와 Student Loss를 모두 사용한다.
Distillation Loss 를 산출하는 경우에는 KL div loss function을 사용하고 Student Loss를 산출하는 경우에는 Corss Entropy Loss function을 사용한다. 그 후 이 두 loss function을 이용해서 back propagation이 이루어지고 student model만을 학습시킨다.
3. Leveraging unlabeled dataset for training
semi-supervised learning
semi supervised learning 은 unlabeled learning 과 labeled learning을 합친 방법이라고 볼 수 있다.
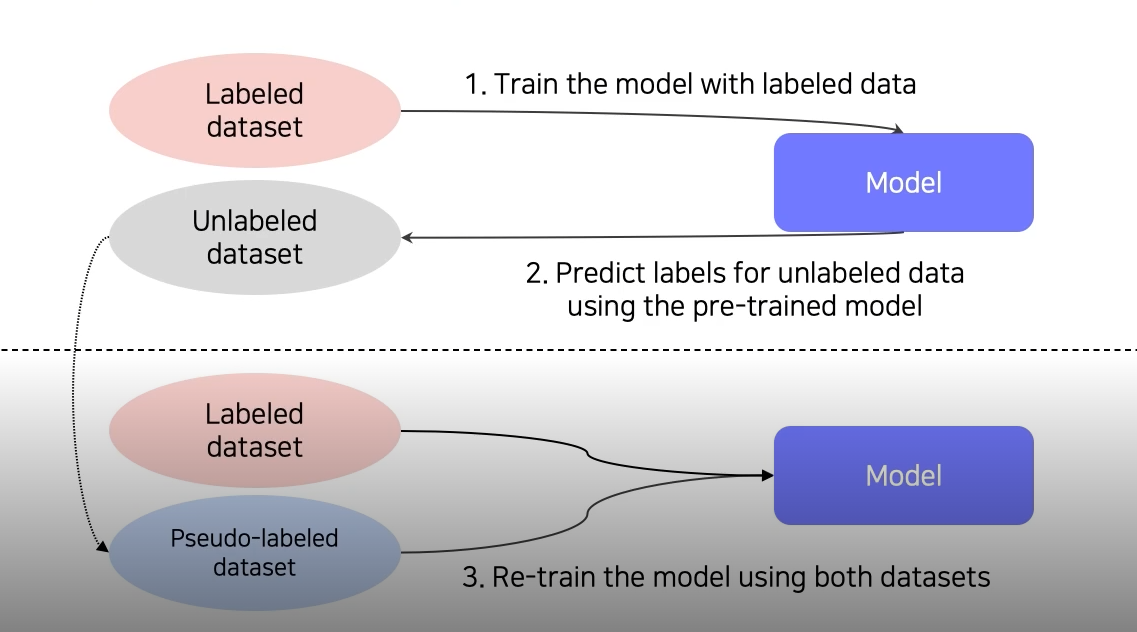
우선 labeled data로 model을 학습시킨다. 그후 unlabeled data를 model에 통과시켜 Pseudo-labeled dataset을 잔뜩 생성시킨다. 그 후 해당 데이터셋을 이용해 모델을 재학습시킨다.
self training (self-trainig with noisy student)
Augmentation+Teacher-Student networks+ semi-supervised learning
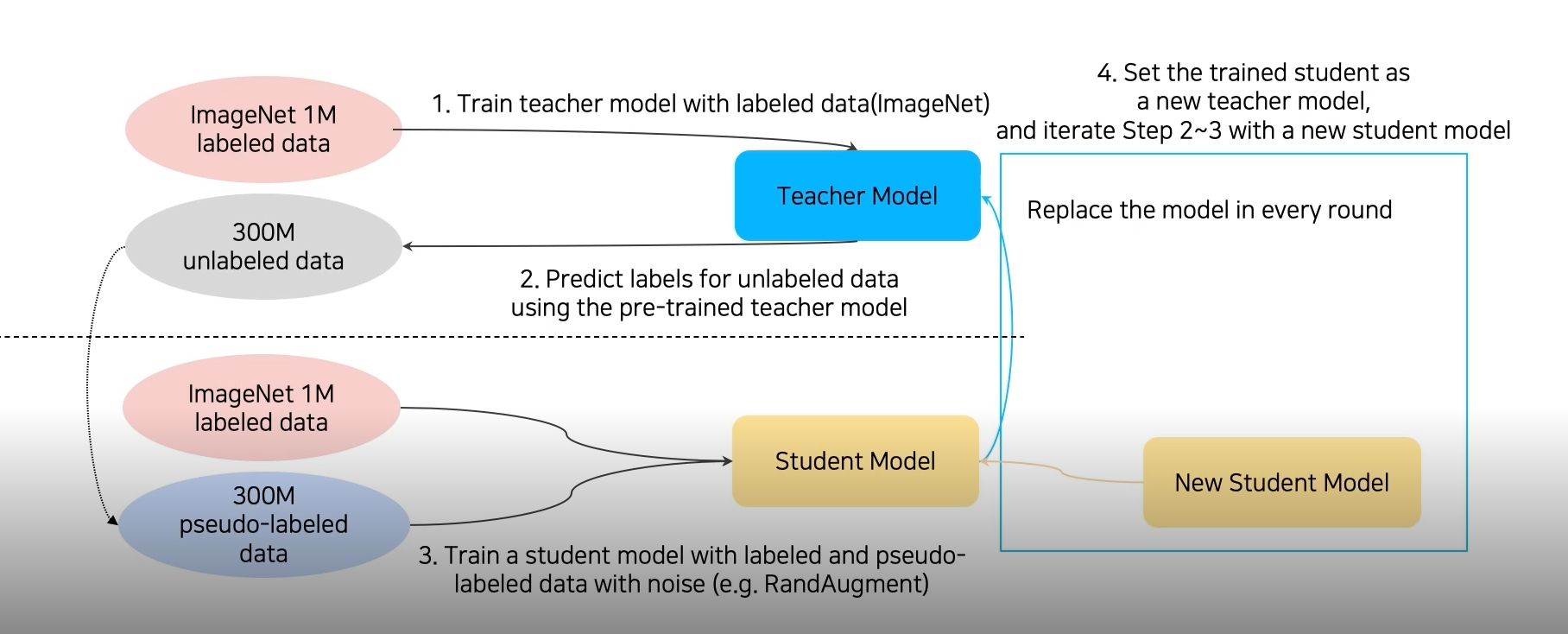
과정은 semi-supervised learning 과 거의 동일하다. ImageNet 1M dataset으로 Teachet모델을 학습시킨다. 그 후 300M unlabeled data를 해당 Teacher model에 통과시켜 300M pseudo-labeled data를 생성해낸다. 다시 1M개의 ImageNet labeled dataset과 300M pseudo-labeled data에 augmentation을 적용해 대량의 데이터로 student model을 학습시킨다. 여기서 학습된 student model은 기존의 Teacher model을 대체하고 그 후 이전과 같은 과정을 반복한다. 이러한 Iteration을 거쳐 stduent model을 점점 확대시킨다. 여기서 주의할점은 이전에 배웠던 Teacher-student networks와 다르게 student model이 teacher model보다 크다는 점이다.
Outro
포스팅을 미루지 않기를 잘한 것 같다. 이미 한번 다룬 내용들이지만 이번 강의를 듣고 정리하면서 다시한번 되새긴 기분이다. 그 동안 깜빡 잊고 있던 내용들도 상기시켜주고 잘못 알고 있었거나 헷갈렸던 내용들도 정리된 것 같다.
요새 부스트 캠프 프로젝트가 끝나고 github에 소홀히 했는데 다시 토이 프로젝트를 하나 시작해서 1일 1커밋을 시작해야 겠다.
