INTRO
CV Image classification의 역사를 알아보자
1. Problems with deeper layers
오늘날 뉴럴 네트워크 모델들의 layers는 더욱 깊어지고 넓어지고 있다. 깊은 네트워크 모델이 성능이 좋은 이유는 더 큰 크기의 receptive fields를 갖기 때문이다.
하지만 모델이 깊을 수록 반드시 성능이 증가하는 것일까?
깊은 모델은 2가지의 문제점을 갖을 수 있다. gradient가 exploding하거나 vanishing 하는 현상들이 일어날 수 있다. 또한 깊은 모델일수록 계산하기 복잡하다는 것은 당연한 사실일 것이다.
2. CNN architectures for image classification
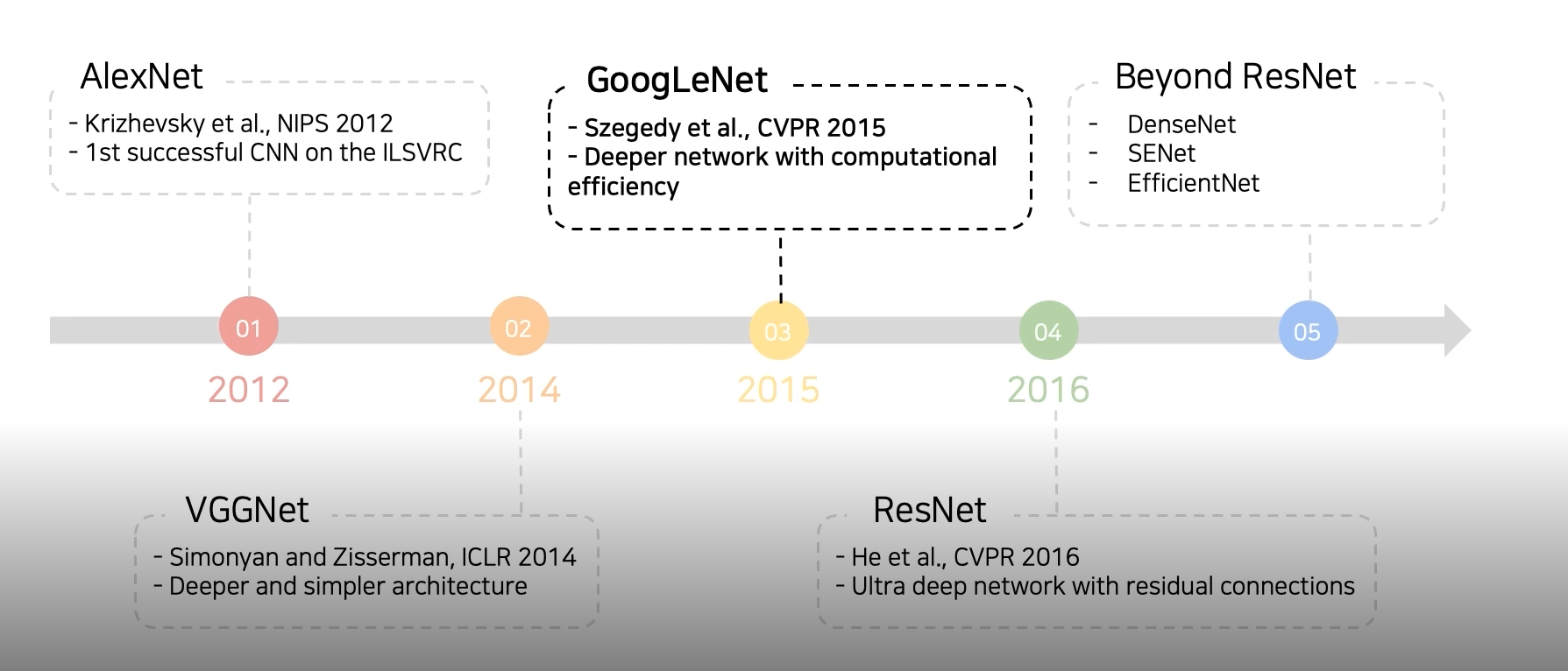
네트워크를 깊게 쌓기 위한 다음의 노력들을 살펴보자
2-1) GoogLeNet
INCEPTION MODULE
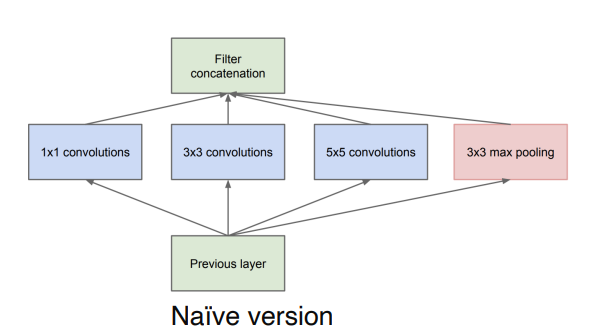
Inception Module은 여러가지 convolution filter을 넓게 사용하는 구조이다. 각각 convolution 연산을 수행한뒤 이들을 합쳐서 값을 도출해낸다. Inception Module의 장점은 이전의 깊은 네트워크에 문제점을 해결해 줄 수 있다는 것이다. 깊은 네트워크와 같이 성능은 높고 네트워크를 깊지 않고 넓게 가져가면서 vanishing gradient의 문제점 등을 해결해 줄 수 있다. 하지만 여전히 parameter의 개수가 너무 많아지는 단점이 존재한다.
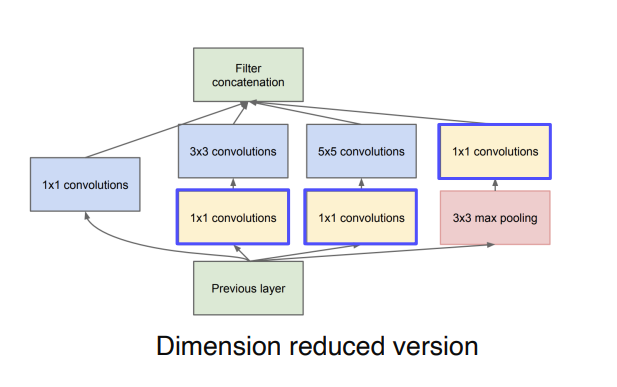
이를 해결하기 위해서 다음과 같은 dimension reduction을 수행한다. 입력을 1x1 Conv에 넣어 channel을 줄였다가 3x3나 5x5 Conv를 거치게해 다시 확장하는 느낌이다. 이렇게 되면 필요한 연산의 양이 확연하게 줄어들게 된다.
Auxiliary classifier
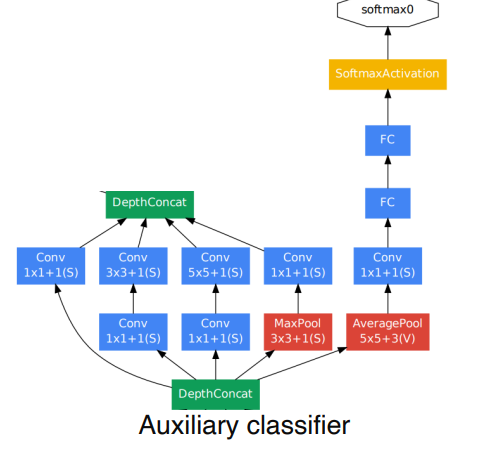
Auxiliary classifier은 GoogLeNet의 깊은 네트워크 구조에서 gradient가 vanishing되는 문제를 해결하기 위해 존재한다. 해당 모델에서는 2개의 Auxiliary classifier가 존재하고 이는 학습시에만 사용되고 test시에는 사용되지 않는다.
2-2) ResNet
Resnet은 깊은 레이어를 쌓을 수록 성능이 높아진다는 것을 증명한 첫 모델이다. 또한 최초로 인간 성능을 뛰어 넘은 모델이기도하다.
DCNN(Deep Convolutional Neural Networks)은 image classification 분야에 있어서 획기적인 발전은 이끌었다. networks의 depth가 중요한 요소로 여겨 졌고, 더 깊은 모델일수록 더 좋은 성능이 나온다고 보여줬었다. 이에 따라 model의 depth를 늘리는 것 만으로도 좋은 성능을 도출해낼 수 있을까?라는 궁금증이 발현됐다.
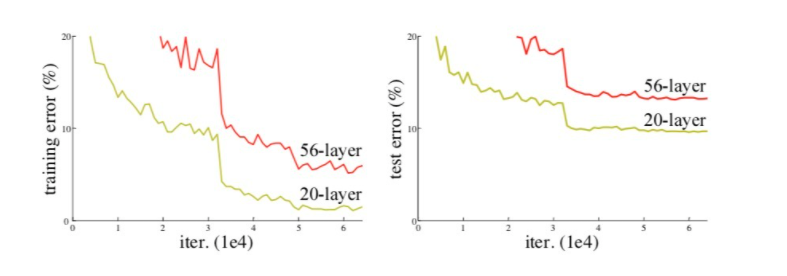
하지만 Gradient Vanishing/exploding 의 문제 때문에 depth가 증가할지라도 어느정도 선에 다다르면 성능이 떨어지는 모습을 보였고 이를 degration이라고 부른다. 이러한 degrationg 문제는 Overfitting이 원인이 아니라, Model의 depth가 깊어짐에 다라 training error가 높아진다는 것이다.
Resnet에서는 기존의 DCNN을 추구하기보다는 residual mapping을 통해 degration문제를 해결할 수 있다고 설명하고 있다.
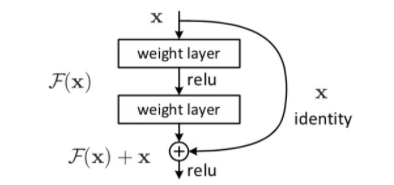
기존의 networks를 라고 했을 때, 를 위 식에 mapping 시킨다. 는 잔차에 해당하고 는 기존의 input을 의미한다. 이러한 Residual mapping 과정을 거치는 것이 기존 model보다 optimize하기 더 쉽다고 말한다.
그렇다면 왜 가 기존의 보다 학습하기 쉬운 것일까? 왜 resnet은 layers의 depth가 깊어져도 degration problem을 보이지 않는 것일까?
Residual block에서의 target function은 가 된다. 여기서 를 치환해보자. layers의 depth가 깊어질 수록 parameter 와 는 사라질 가능성이 있다. 하지만 가 존재하기 때문에 와 가 0으로 수렴하게 되더라도 layers가 skip 도니 것뿐이지 그 이전의 input 값인 는 보존되기 때문에 degration problem을 보이지 않는 것이다.
더 자세한 증명과정은 다음 영상을 참고하면 이해하기 쉽다.
https://www.youtube.com/watch?v=RYth6EbBUqM
2-3) DenseNet

ResNet 이후 DenseNet이 등장하였다. 위의 그림을 보면 DenseNet은 Resnet과 다르게 바로직전의 input 값뿐만아니라 그 전의 input 값들도 참조하게 만드는 빽빽한 구조로 이루어져 있다. 또 DenseNet에서는 resNet과 달리 이전의 input 값을 더해주는 형태가 아닌 concatenation을 사용한다. concatenation은 channel이 늘어나는 대신 그 전의 input 값의 feature의 정보를 그대로 보존하고 있기 때문에 상위 layer에서 하위 layer의 feature을
참조할 수 있게 된다.
2-4) SENet
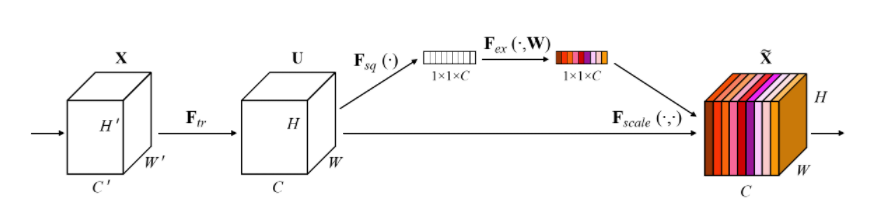
SENet에서 SE는 "Sequeeze-and-Excitation"의 약자이다.
SENet의 아이디어를 논문에 나온 영어로 간단히 써보면 다음과 같다.
- Our goal is to improve the representational power of a network by explicitly modeling the interdependencies between the channels of its convolutional features.
2-5) EfficientNet
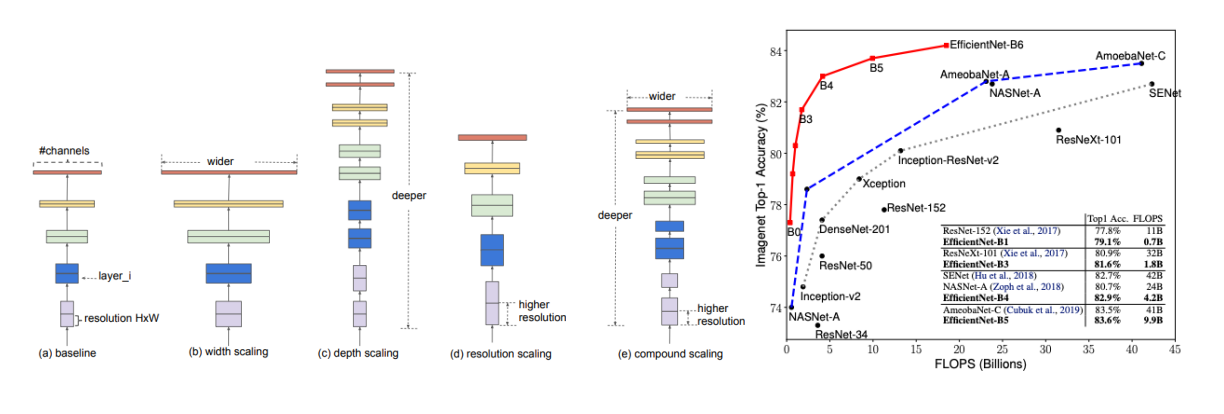
Efficient Net은 우선 baseline code에서 Width Scaling을 거친다. 그 후 ResNet과 비슷하게 depth scaling을 거친다. 그 후 Resoultion scaling을 적용하는데 이는 input 이미지를 크게 가져가는 것이다. 이 세가지 방법 모두 모델의 성능을 증가시키는데 그 성능이 증가되는 시점이 각기 다르다. 따라서 이 세가지 방법을 적절한 비율로 조화시키는 것이 성능에 많은 향상을 미칠 것이라고 가정했고 이를 하는 것이 compound scaling이다.
