Intro
1. Semantic Segmentation
Sementic segmentation이란 이미지분류를 영상단위로 하는 것이 아닌 픽셀단위로 하는 것이라고 생각하면 된다. 즉 하나의 픽셀이 사람에 속하는지, 자동차에 속하는지, 동물에 속하는지 판단하는 것이다. 또한 기본적인 Sementic segmentation은 다른 사람일지라도 같은 사람으로 분류하기때문에 각 instance별로 구분하는 것은 아니다.
Semantic Segmentation은 어디에서 활용될까?
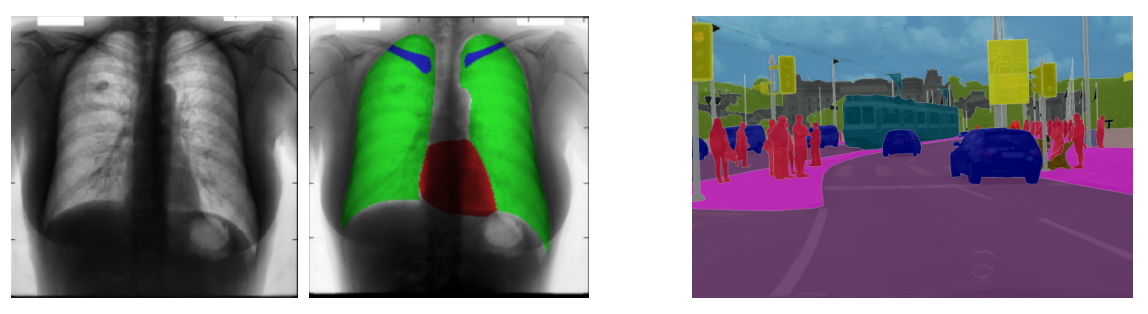
위의 그림과 같이 의학적 이미지에서도 활용되고 자율 주행에서도 많이 활용된다. 또한 Computational photography와 같이 특정 object를 선택해 그 object만 변경하는 등, 이미지 편집에서도 광범위하게 활용된다.
2. Semantic segmentation architectures
2-1) Fully Convolutional Networks(FCN)
FCN은 기존 CNN 모델을 Segmentation에 적합하게 변형해, segmentation 발전의 토대를 이룬 초기 모델이다. 가장 큰 특징은 FC Layer 없이 Convolutional Layer 만으로 구성되었고, Unsampling을 사용했다는 점이다. FCN은 Input 이미지를 patch 단위로 분석하지 않고 모든 영역을 receptive field로 보는 filter를 사용한 CNN이라고 볼 수 있다.
Fully connected vs Fully convolutional
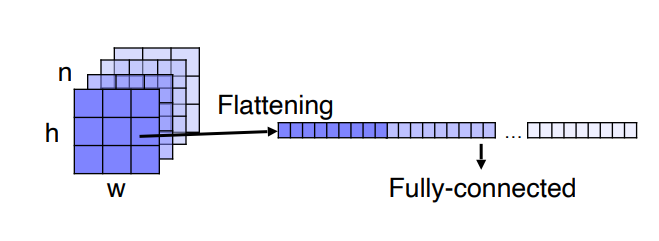
기존의 CNN 모델의 구조에서는 위와 같은 FC(fully connected) layer를 가졌는데, FC layer에 입력하기 전에 각각의 channel을 flattening 하는 과정을 수행했다. 이렇게 flattening과정을 수행하게 되면 영상의 위치를 고려하지 않는 하나의 vector가 되는 셈이다. 그렇다면 어떻게 영상의 위치를 고려해줄 수 있을까?
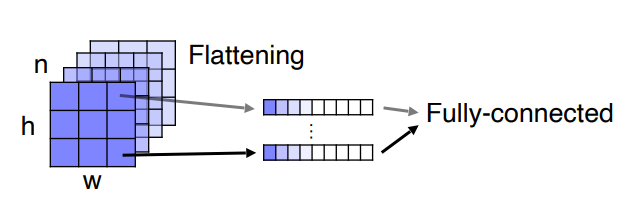
위의 그림을 보면 각각의 channel 축으로 vector를 만들어주고 있음을 알 수 있다. 즉 9개의 vector가 생기는 셈이다. 그후 각각에 대해서 fully connected layer을 적용하면 영상의 위치를 보존한 채로 classification을 할 수 있다. 이는 1x1 convolution filter을 적용 한 것과 완전히 동일하게 된다.
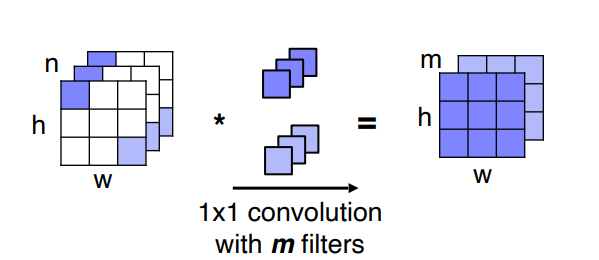
위의 그림에서 각 채널축에 convolution filter을 내적하는데 이는 바로이전에 언급된 모델과 같은 개념이다. 차이점은 convolution filter가 추가되어 weight의 역할을 하고 있는 것이다. 필터의 개수 m 만큼 channel 이 생긴다.
Upsampling
Convolutional의 문제점은 무엇일까?
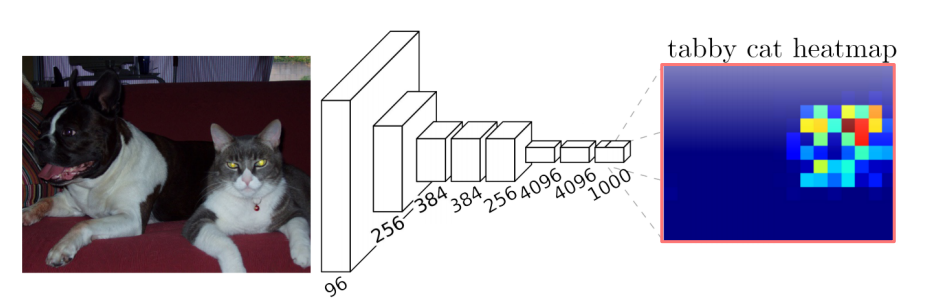
그림만 보고 직관적으로 알수 있는 점은 바로 Convolutional Layer를 거치면서 Downsampling 됨에 따라 feature map의 크기가 줄고 두께는 점점 두꺼워진다는 것이다.
이를 해결하기 위해 등장한 것이 바로 upsampling이다. 말그대로 이미지를 다시 키우는 것이다. upsampling에는 주로 사용되는 두가지 종류가 있다. Transposed convolution과 upsample and convolution이다.
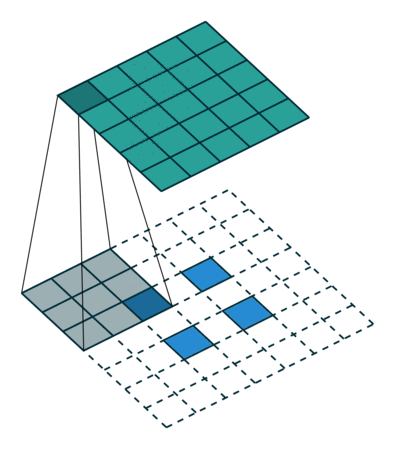
Transposed convolution은 Input 이미지의 크기의 이미지를 얻어내기 위해 convolution 과정을 그대로 수행한다. 하지만 Transposed convolution의 output은 convolution의 input과 크기는 같지만 그 값은 다를 수 있다. 예를들어 위의 그림처럼 2x2 이미지를 upsampling 하여 (일반적으로 빈 공간을 0으로 채운다) 7x7 이미지로 만든 뒤 3x3 filter를 stride 1로 움직여 5x5 크기의 이미지를 얻어낸다.

Transposed convolution의 문제점은 앞서 언급한 바와 같이 이미지의 크기는 같지만 위와 같은 blocky한 현상이 나타날 수 있다는 것이다. 그래서 위와 같은 overlap 문제를 해결하기 위해 등장하는 것이 upsample and convolution이다.
upsample and convolution은 말그대로 upsampling과 convolution을 같이 사용하는 것이다. Transposed convolution은 학습가능한 upsampling을 하나의 layer로 한방에 처리한 것으로 볼 수 있다. 하지만 upsample and convoluiton은 upsampling 동작을 2개의 layer로 분리한다. 우선 parameter가 없는 간단한 interpolation을 적용 그후 parameter가 존재하는convolution을 적용하는 순서이다.
다시 전반적인 FCN의 흐름을 살펴보자
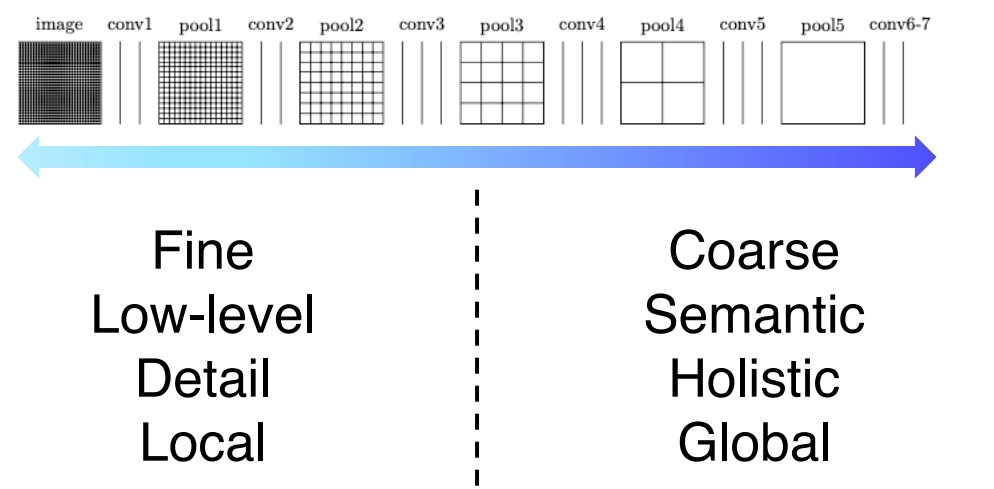
먼저 초기 layer의 부분을 보면 receptive field 사이즈가 작기 때문에 굉장히 국지적이고 작은 디테일을 보고 작은 차이에도 민감한 경향이 있다. 반대로 높은 layer의 부분을 보면 해상도는 낮아지지만 큰 receptive field를 가지고 전반적이고 젠체적인 의미론적 정보를 많이 포함하는 경향을 가지고 있다. Sementic segmentation은 이런 국지적인 정보와 전체적인 정보가 모두 필요하다.
이러한 2가지의 상반되는 정보를 모두 이용하기 위해 낮은 층의 레이어에서 upsampling을 바로 거쳐 output에 통합하기도 한다. FCN-16s , FCN-8s가 이와같은 예이다.
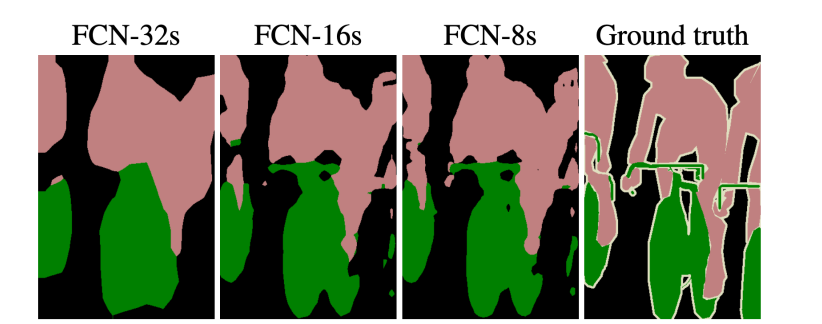
그림을 보면 오른쪽 그림으로 갈수록 Semantic segmentation이 잘 이루어졌는데 FCN-32s부터 우측으로 갈수록 더 많은 낮은 층 레이어들과 통합된 모델이기 때문이다.
Outro
Semantic Segmentation의 또 다른 architecture인 U-Net과 DeepLab 좀 더 공부를 한 후 나중에 다시 다뤄보도록 하겠습니다..
