Intro
이전 포스팅까지 데이터 정제에서부터 모델 학습, 그리고 평가까지 하는 단계를 순차적으로 알아보았다. 이번 포스팅에서는 이렇게 만들어진 결과물들을 굳히는 과정을 알아보자
1. Ensemble 앙상블
아마 우리는 여러 실험을 하면서 여러가지 모델로 여러가지 결과를 만들었을 것이다.
앙상블이란 싱글 모델보다 더 나은 성능을 위해 서로 다른 여러 학습 모델을 사용하는 것을 의미한다.
딥러닝 모델들은 주로 많은 데이터가 있다는 전제 하에 overfitting 하는 경향이 있다. 이를 개선하기위해 고안된 것이 바로 앙상블이다. 주로 overfitting하는 모델과 bias가 높은 모델을 합쳐서 모델을 일반화시키는게 보편적이다.
1-1) Model Averaging (voting)
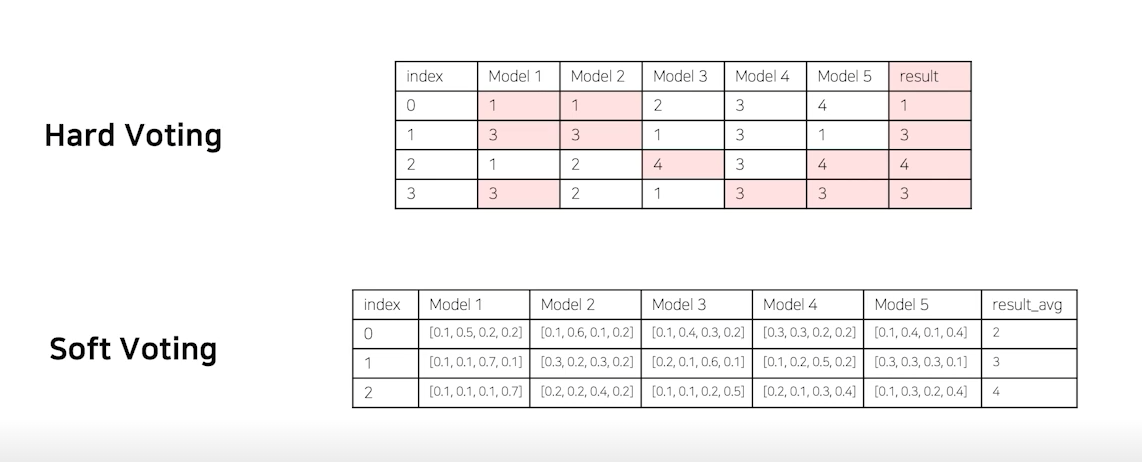
averaging, voting은 단어 뜻 그대로 투표를 통해 결정하는 방식이다. 위의 그림에서 보이다 싶이 각 모델이 도출해 낸 결과물에 대하여 최종 투표하는 방식을 통해 최종결과를 선택하는 것이 바로 Model Averaging(voting)이다. voting은 hard voting과 soft voting으로 나뉘어진다.
hard voting은 결과물에 대한 최종 값을 투표해서 결정하고, soft voting은 최종 결과물이 나올 확률 값을 다 더해서 각각의 확률을 구한뒤 최종 값을 도출해 낸다.
1-2) Cross Validation
앙상블 과정에서 인기가 많은 기법이다.
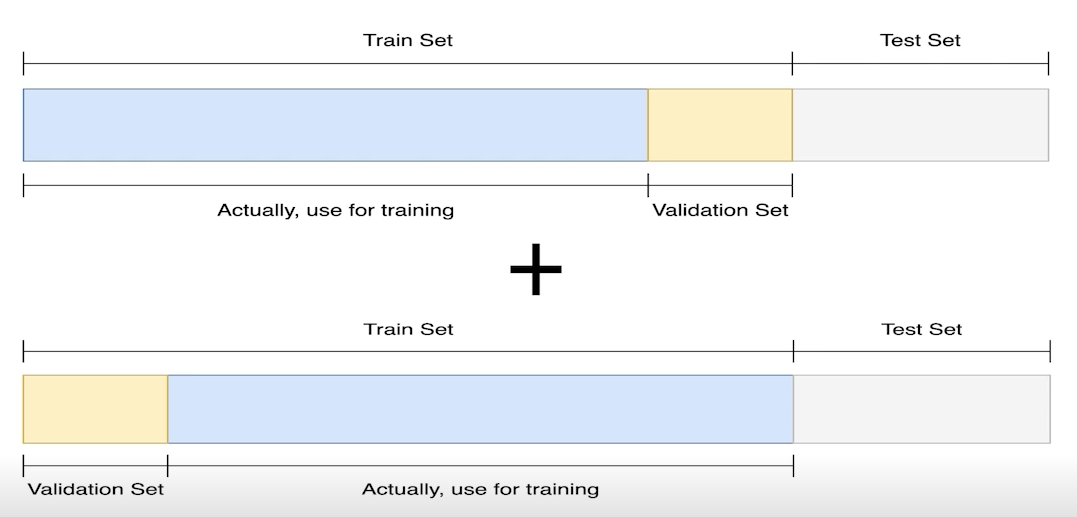
Validation 은 train set 에서 일부를 validation set으로 가져와 학습을 하는 동시에 검증을 하는 과정을 말한다. 하지만 이렇게 되면 train set의 데이터가 줄어들어 학습의 bias가 커질 가능성이 높아진다. 이를 위해 고안된 것이 바로 Cross Validation이다. 사진에서 보면 알 수 있듯이 학습마다 train set 과 validation set을 번갈아가며 만들어 학습하게 된다.
여기서 확장된 개념이 Stratified K-Fold Cross Validation 이다
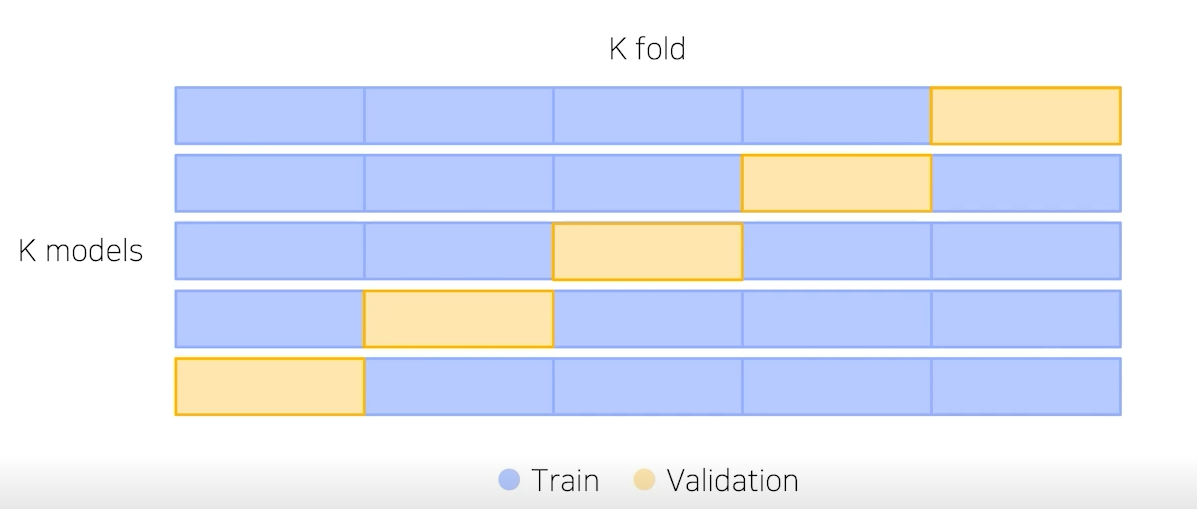
예를 들어, validation set을 20%로 설정한다면 위처럼 5가지의 case를 만들 수 있다. 이는 가능한 경우를 모두 고려하며 split 시에 class 분포까지 고려한다. 결과적으로 K개의 모델이 생성되고 이 K개의 모델을 앙상블함으로써 좋은 성능을 기대하게 된다.
1-3) TTA (Test Time Augmentation)
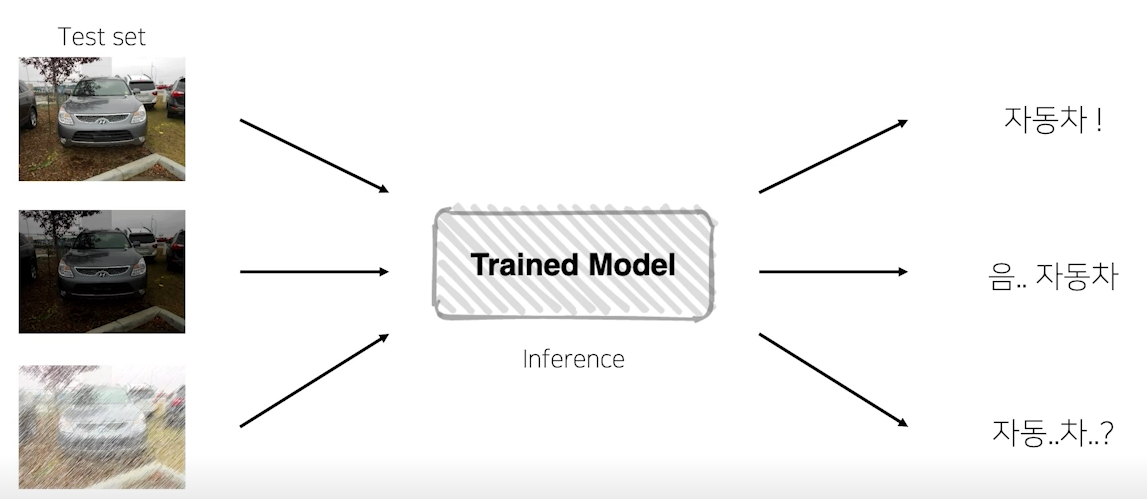
위에사진 처럼 Test 시에 test set에 augmentation을 주어서 데이터 셋을 변형시켜준다. 이 과정을 하는 이유는 데이터 셋이 같은 모습일 때 노이즈를 준다고 하면 모델을 그 데이터를 어떻게 판단할까?라는 물음에서 시작되었다.
하지만 이 과정이 왜 앙상블인지 의아할 수도 있다.
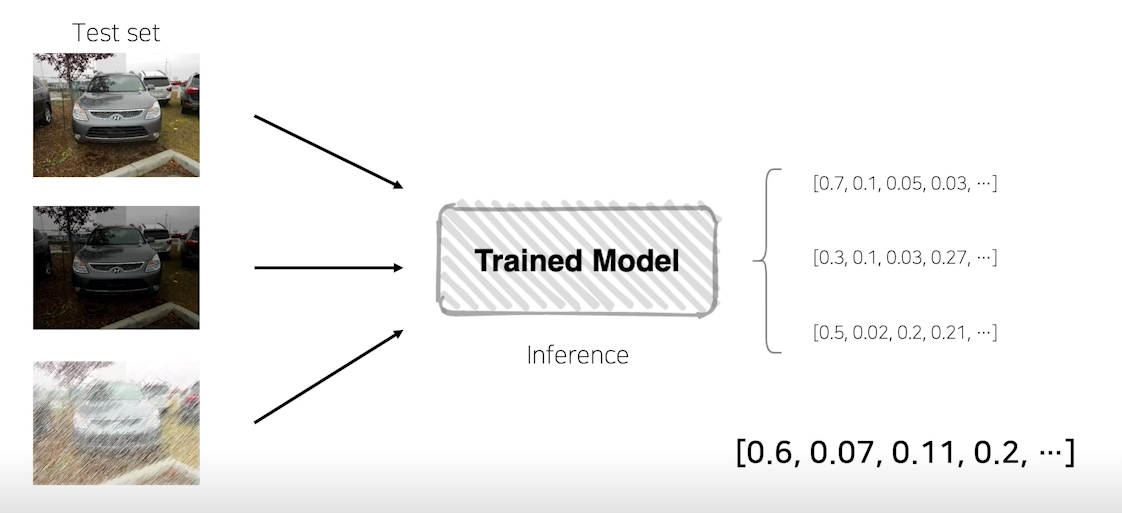
TTA가 앙상블의 하나가 되는 이유는 각각의 augmentation을 거친 data셋마다의 모델을 만들고 그 모델의 합쳐서 하나의 모델로 만들기때문이다.
2. Hyperparameter Optimization

딥러닝에서 모델링을 할 때 중요한 부분이 바로 하이퍼 파라미터(hyperparameter)의 조정이다.
하지만 하이퍼 파라미터는 분석자가 조종해야 하므로 초기값을 어떤 값으로 정해야하는지 어떻게 파라미터값을 수정해야 하는지 고민이 생기기 마련이다.
시간과 장비가 충분하다면 모든 하이파라미터를 테스트 해볼 수 있지만 실상은 그렇지 않다.
Optuna
바로 이러한 고민을 덜어주는 도구가 Optuna이다.
Optuna는 hyperparameter Optimization을 도와주는 모듈이다.
3. Experiment Toolkits & Tips
딥러닝을 할때 실험을 도와주는 여러가지 도구들을 알아보자
3-1) Training Visualization
| Tensorboard
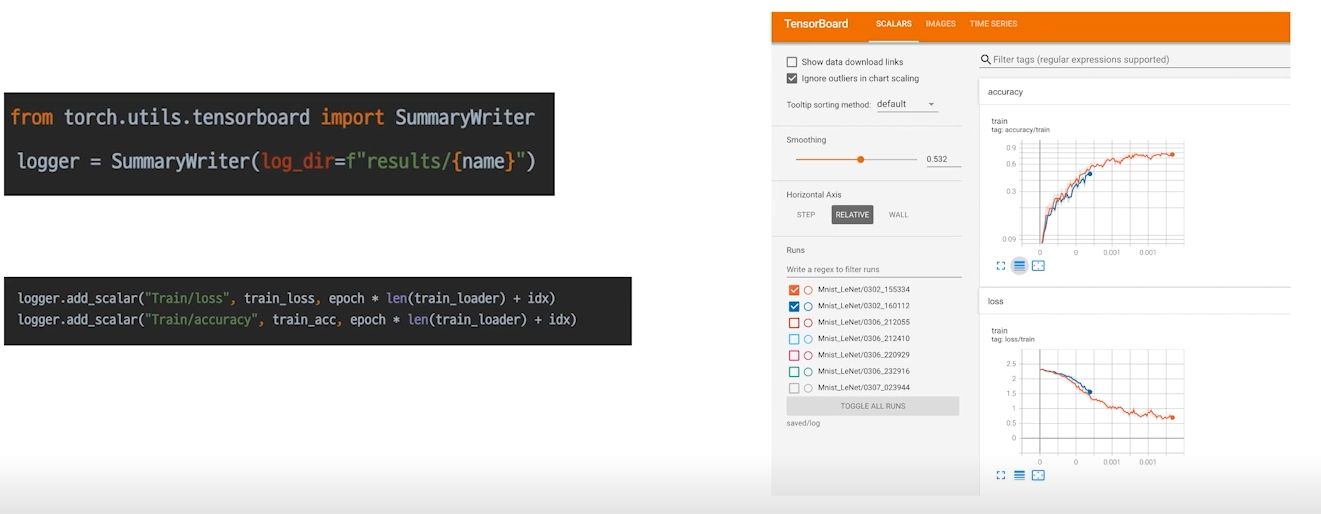
학습 과정을 트래킹하는 용도, 이전의 학습과 비교할 수도 있음
| Weight and Bias
딥러닝 로그의 깃허브같은 느낌이다.
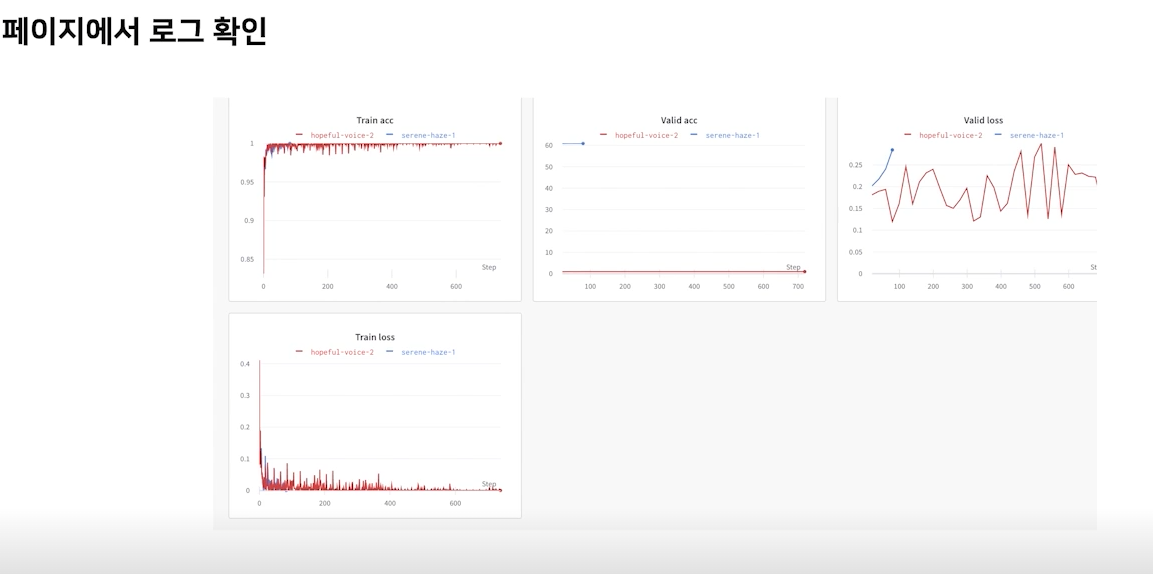
위와 같이 페이지에 접속해 로그를 확인할 수 있다.
3-2) Machine Learning Project
| Jupyter Notebook
코드를 아주 빠르게 Cell 단위로 실행해볼 수 있다는 것이 장점이다.
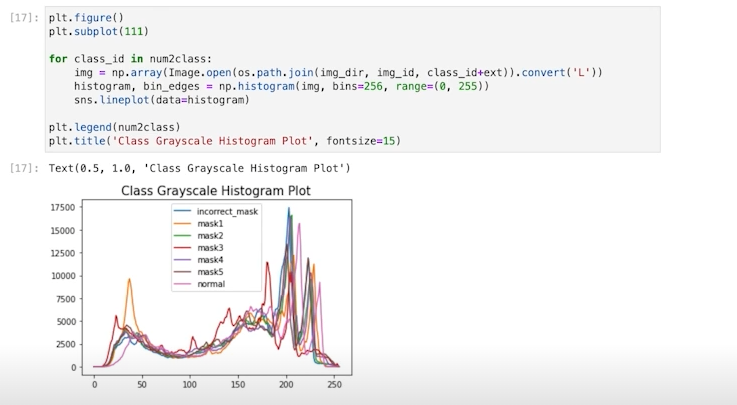
특히 EDA를 할 때 사용하면 매우 편리하다.
| Python IDLE
구현 한번만으로 언제든 사용하고 간편하게 코드를 재사용하기도 용이해진다.
또한 잘 다루는 법만 알면 디버깅을 하기에도 매우 용이하다.
또한 자유롭게 argparser 또는 configparser를 통해 자유로운 실험 핸들링도 가능하다.
학습회고
다음주부터 본격적으로 팀 competition에 들어간다. 오늘은 팀원들과 함게 여러가지 convention을 정했다.
우선 형상관리도구인 github의 convention에 대해 논의했다. pull request와 commit, code 등 아직 기본적인 사항에 대해서 팀원들간의 논의가 부족했었던 것 같다. 또한 이번주 주말에 팀원들과 한번더 미팅을 갖고 전체적인 베이스라인코드를 설정하기로 했다.
github뿐만아니라 aistage에 제출하는 규칙에 관해서도 팀원들과 논의했다. 하루에 10회로 제출이 되어있기때문에 어떤 방식으로 제출할지 정하는 것이 필요했다. 일단 기본적으로 하루에 10회뿐이 없기때문에 하루에 주어진 할당량은 다 쓰는 방향으로 가도록 했다.
이번주 한주 동안 모더레이터를 맡아서 꽤 바빴던 것 같다. 팀회고 제출, 피어세션 정리, 멘토링 정리 들 해야하는 일이 생각보다 많았다. 그동안 모더레이터분들의 고충을 느낄 수 있었다.
이번 주말에는 모델 학습보다는 코드 구성 위주로 작업하고, 그동안 소홀히 했던 EDA 과정을 다시 복습할 필요가 있는 것 같다. 또 공부도 공부지만 주말만큼은 리프레시하는 것도 중요한 것 같다.
