Intro
지난 포스팅에서는 모델을 설계하는 부분까지 다루어 보았다. 모델을 어떻게 디자인하고 Pretrained 모델을 사용하는데 있어서 주의할점과 어떻게 잘 활용할 수 있는지 알아보았다.
이번 포스팅에서는 잘 만들어진 데이터와 모델을 갖고 어떻게 학습해는지 알아보려고 한다.
학습에 필요한 요소를 크게 셋으로 분류해 볼 수 있다.
1. Loss
2. Optimizer
3. Metric
위 세가지는 학습하는 데에 있어서 반드시 명시되어야 되는 것들이다. 위에서부터 차례대로 하나 하나 알아보도록 하자
1. Loss
1-1 Backpropagation (오차 역전파)
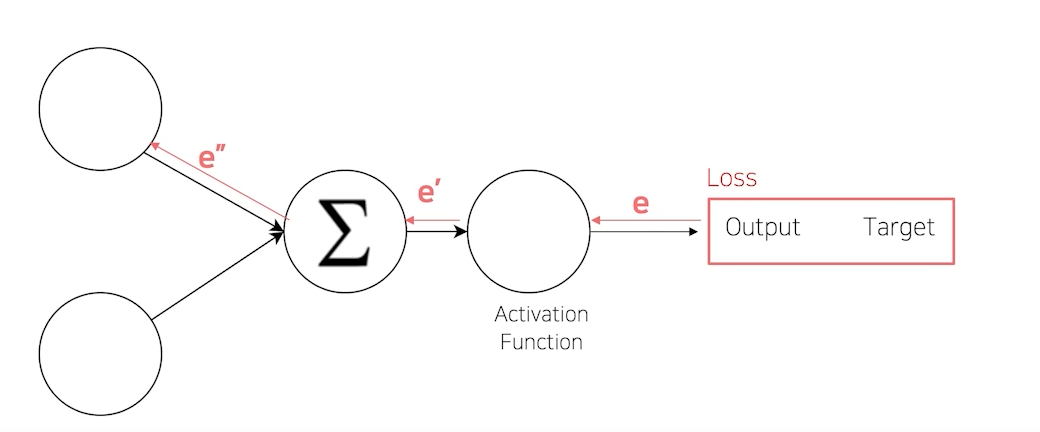
먼저 Loss 함수는 모델이 잘 학습되도록 해주는 함수이다. 즉, 모델에게 기준을 선정해준다. 최소의 Loss 를 목표로 지금 학습이 잘 되고 있는지 아닌지를 판단할 수 있다.
Loss 함수는 output과 target의 차이로 만들어진다.
즉, 어떤 loss 함수가 모델에 선언되어 있나에 따라서 모델이 변할 수 있다는 것이다.
여기서 중요한 점은, nn.Loss 도 사실 nn.Module 안에 있다는 사실이다. (Loss도 사실은 nn 패키지에서 찾을 수 있다.)

즉, Loss 도 nn.Module을 상속하고 있기 때문에 연쇄적으로 model이 nn.loss에게 까지 연결되게 되고 backpropagation 과정을 거치면 제일 끝단부터 앞단까지 영향을 미치게 된다.
loss.backward() 를 통해 쉽게 backpropagation을 실행할 수 있다. 단 여기서 requires_grad가 false인 parameter들은 학습에서 제외된다.
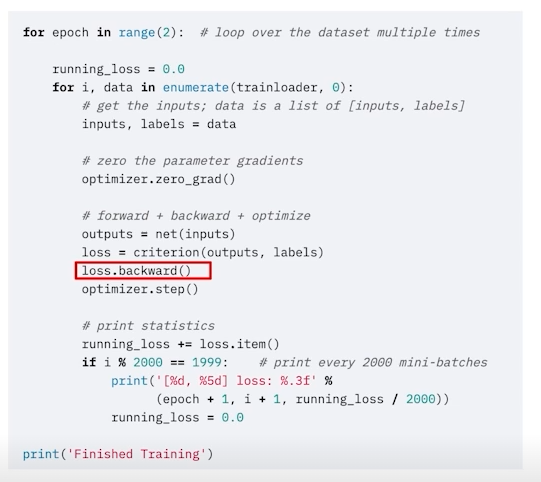
위와 같이 loss.backward()를 통해 모델에 있는 param의 모든 grad를 update할 수 있다. 자세한건 이따 다시 다루어보자 .
1-3 조금 특별한 loss
loss 함수는 쉽게 말해서 Error를 만들어내느 과정에 양념을 치는 것이다. 양념을 치는 방법에는 당연히 여러가지가 존재한다.
-
Focal Loss : Class Imbalance 문제가 있는 경우, 맞춘 확률이 높은 Class는 조금의 loss를, 맞춘 확률이 낮은 Class는 Loss를 훨씬 높게 부여.
-
Label Smoothing Loss : Class target label을 Onehot 표현으로 사용하기 보다는 조금 soft 하게 표현해서 일반화 성능을 높이기 위함
ex) [0,1,0,0,0,...] -> [0.0025,0.9,0.0025,0.025,...]
2. Optimizer
2-1 기본적인 formula
optimizer 는 어느 방향으로, 얼마나 움직일 지를 결정하는 것이다.

parameter를 학습률만큼 학습방향으로 update 한다.
즉, 영리하게 움직일수록 수렴은 빨라진다.
2-2 LR scheduler
그렇다면 Learning Rate를 동적으로 조절하므로써 더욱 빠른수렴을 하도록 할수 있지 않을까? 그 역할을 하는 것이 LR scheduler 이다.
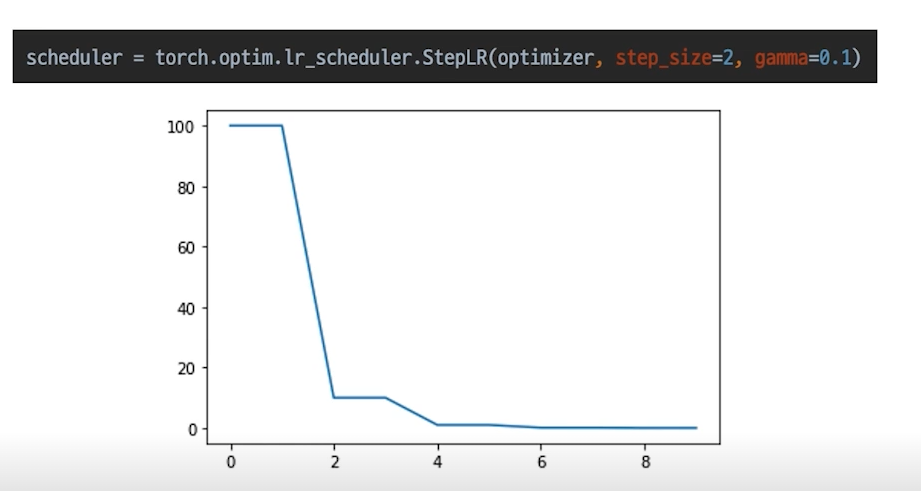
StepLR
특정 step 마다 LR을 감소시키는 단순한 LR scheduler 이다.
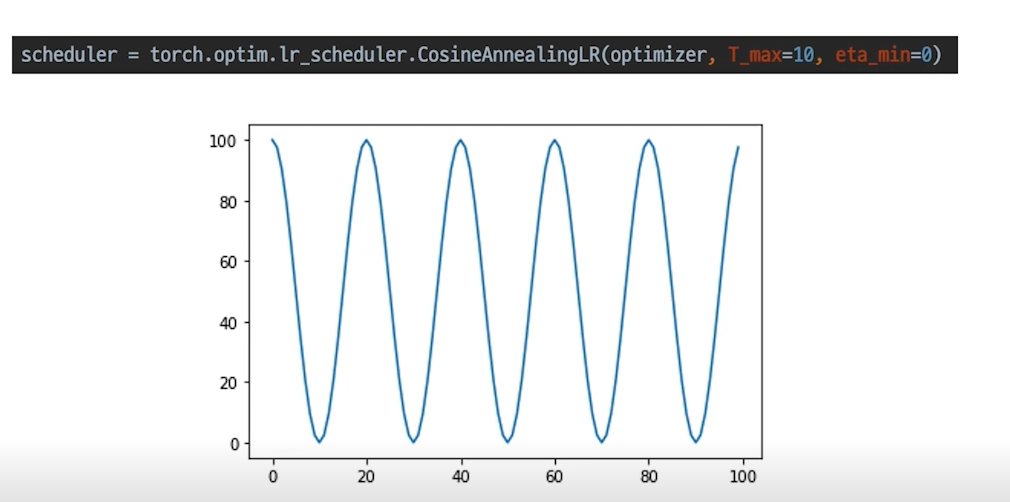
CosineAnnealingLR
코사인 함수처럼 LR을 급격히 변경한다.
변화를 다양하게 줄 수 있는 장점이 있다. 이 방식을 적용했을 때 local minimum에 빠지는 오류를 피할 수 있게 해준다.
ReduceLROnPlateau
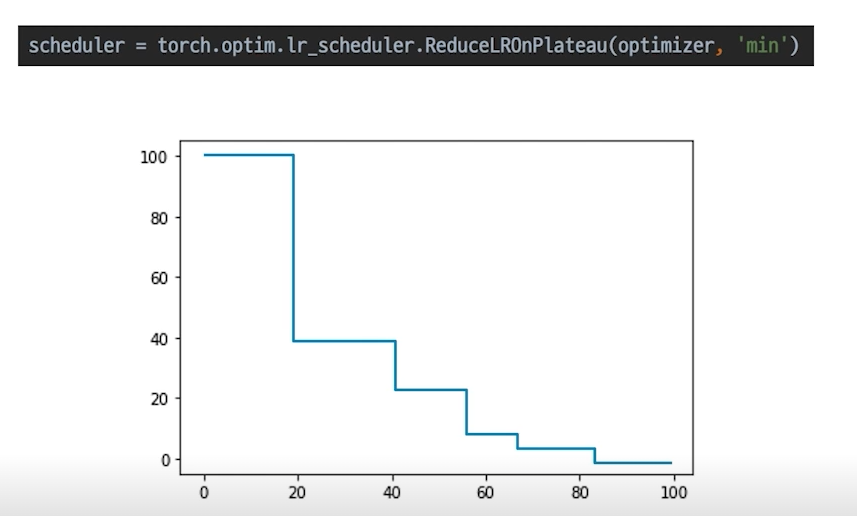
일반적으로 가장 많이 쓰이는 optimizer다.
더 이상 성능 향상이 없을 때 Learnig rate를 감소시킨다.
성능 향상이 없을 때 학습률을 줄여 미세하게 오차의 minimum을 찾아나간다.
3. Metric
Metric이란 무엇일까?
아래와 같이 2개의 sector로 나눠서 알아보자
모델의 평가
score의 허와 실
3-1 모델의 평가
Metric은 말그대로 학습된 모델을 test dataset으로 평가하는 것을 의미한다.
Metric은 모델의 목적마다 여러 종류가 있다.
Classification : Accuracy, F1-score, precision, recall, ROC&AUC
Regression : MAE, MSE
Ranking : MRR, NDCG, MAP
Metric은 학습에 직접적으로 사용되는 것은 아니지만 학습된 모델을 객관적으로 평가할 수 있는 지표이기 때문에 중요하다.
3-2 Metric의 허와 실
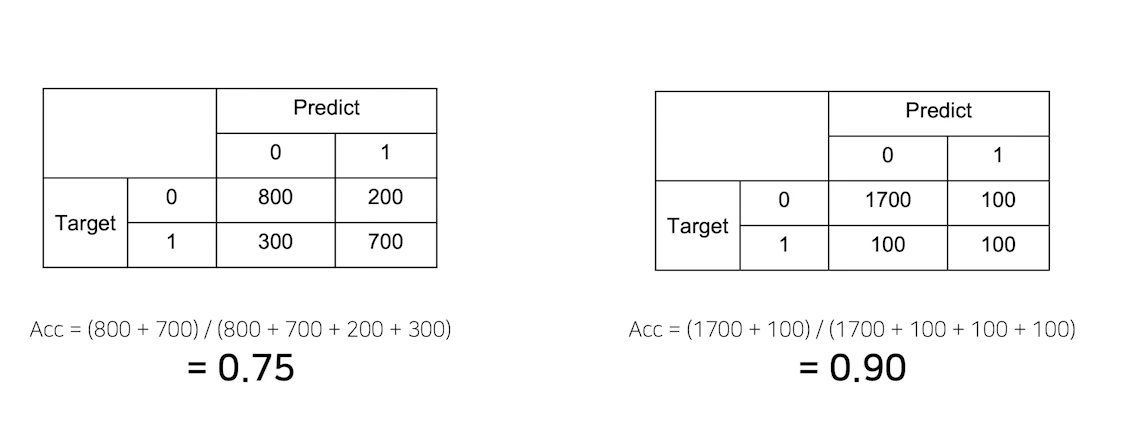
2개의 모델 중에 더 좋은 모델은 무엇일까? 수치로 보기에는 오른쪽 모델이 더 성능이 좋아보인다. 하지만 Metric을 자세히 보면 오른쪽 모델은 Target 이 1 일때 50% 정확도를 보인다. 위의 2개의 그림은 올바른 Metric을 선택하는 것도 중요하다는 것을 시사한다.
올바른 Metric의 선택하기
데이터의 상태에 따라 적절한 metric을 선택하는것이 필요하다.
Class별로 밸런스가 적절히 분포되어 있을 때에는 Accuracy,
Class별로 밸런스가 좋지 않아서 각 클래스 별로 성능을 잘 낼 수 있는지 확인 필요할 때에는 F1-Score
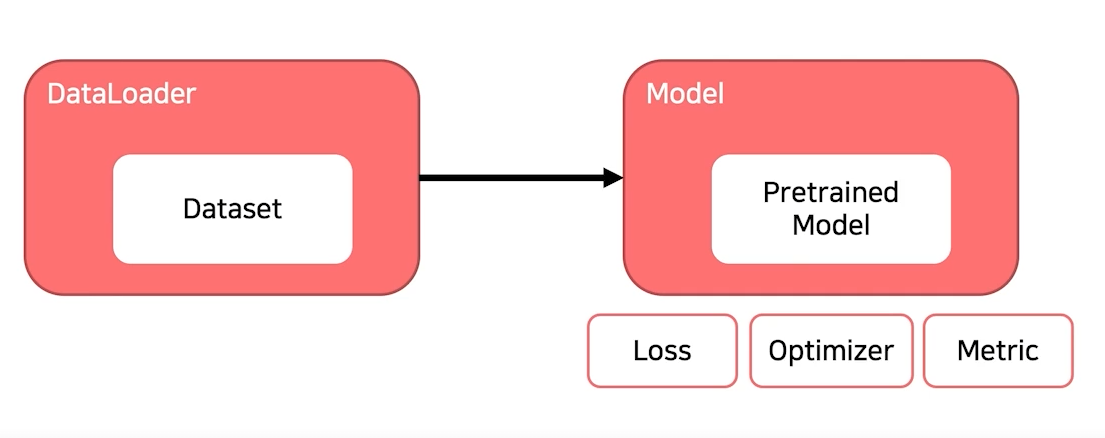
4. Process
프로세스는 크게 2가지로 나눠서 볼 수 있다. trainig process 와 inference process
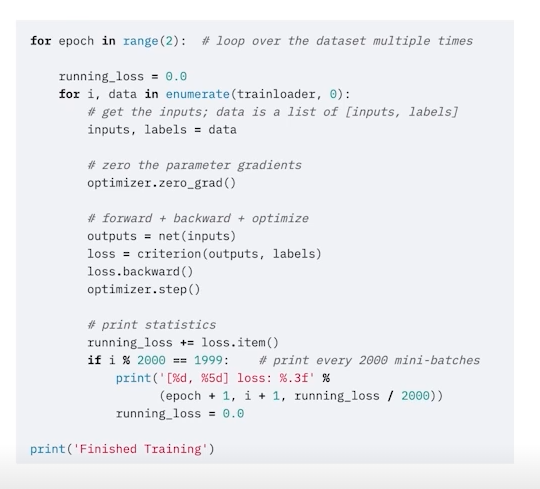
위의 사진이 training process (학습)

위의 사진은 inference process (추론) 이다.
4-1) training process
학습을 위해, 이전 포스팅에서 배웠던 내용들을 모두 종합해서 살펴보자
model.train()
모델을 트레인 모드로 바꿔주는 과정이다. (requires_grad= True로 설정하는 것과는 다름)
-> Dropout, BatchNorm은 train과 eval 모드에서 상이하기때문에 train 모드를 명시해주는 것이 중요하다.
optimizer.zero_grad()
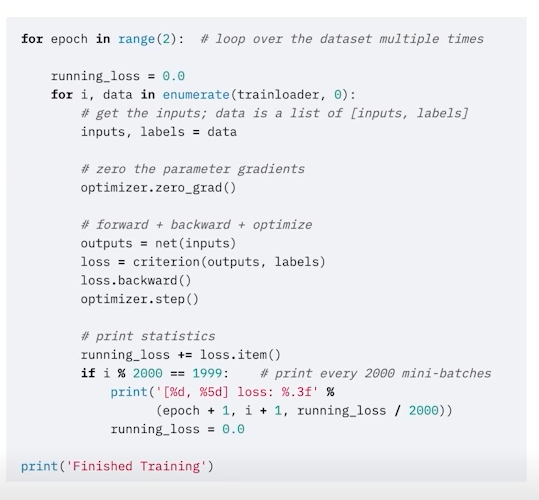
for epoch in range(2) 에서 epoch만큼의 반복을 실행한다. 즉, epoch는 전체적인 학습 횟수라고 볼 수 있다.
그 다음의 반복문인 for i, data in enumerate(trainloader, 0) 에서는 batch size만큼의 data가 trainloader 로부터 나오는 것을 알 수 있다.
즉, 모든 batch를 다한번 거치는 것이 하나의 epoch, 하나의 학습이고 위의 코드에 따르면 이 과정을 2번 반복하는 것으로 이해하면 된다.
중요한 것은 optimizer.zero_grad() 부분인데, 우리가 아는 optimizer는 빠르게 학습할 수 있도록 해주는 함수인데 zero_grad가 의마하는 바는 무엇일까?
batch iteration이 돌아갈 때 zero_grad()해주지 않으면 2번째 batch iteration 부터 이전에 산출된 grad 값을 사용하게 된다. 하지만 일반적으로 각 batch를 독립적으로 보기 때문에 이전에 있는 grad를 사용하지 않고 zero grad에서 그 batch에 맞는 새로운 grad를 산출한다.
loss.backward()
loss = criterion(outputs, labels)
말 그래도 손실함수, 오차함수이다.
ouputs에는 예측값이 들어가고 output과 label을 비교하게 된다.
loss.backward()를 실행하게 되면 backpropagation이 진행된다. 위에서도 잠깐 언급했다 싶이 loss함수는 기본적으로 nn.Module을 상속받고 있는 클래스이다. 즉, model의 layer들의 끝에 loss 함수가 붙게 되어 backward함수를 실행하면 loss함수에서부터 차례로 backpropagation 과정이 진행되는 셈이다.
optimizer.step()
loss.backward() 과정을 지나면 각 parameter들의 grad는 update 된다. 이제 이 grad 를 토대로 step 을 밟아서 parameter를 조정하는 과정이라고 보면된다.
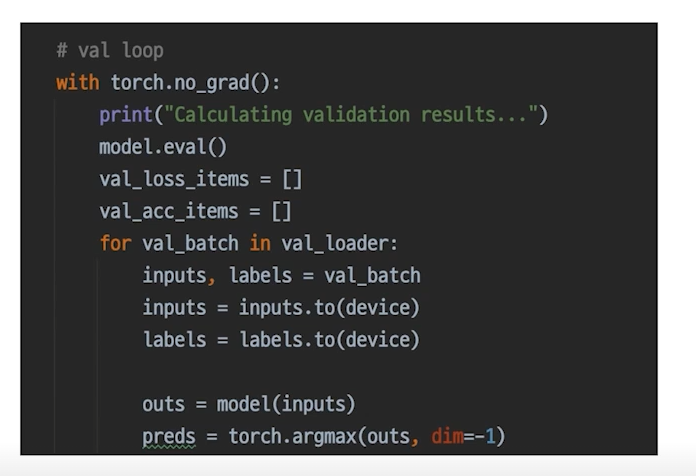
4-2) Inference process
model.eval()
train 모드가 아닌 eval 모드이다. eval 모드를 설정해줘야 하는 이유는 train 모드를 설정하는 이유와 동일하다고 보면 된다.
with torch.no_grad():

말 그대로 grad가 필요 없다는 의미로, model의 parameter가 변하지 않게 해주며, 불필요한 연산과정을 없애준다.
eval 모드는 test dataset 말고도 valid dataset을 실행할 때도 사용된다.
코드는 아래와 같다.
! 만약 추론과정(inference process)에서 Validation set이 들어가면 그게 검증과정이다.
Checkpoint
체크포인트는 말그대로 validation set을 토대로 학습 중간 중간 checkpoint를 남겨주는 과정이다. sql에서 rollback과정에 사용되는 checkpoint와 같은 맥락으로 보면 된다.

학습회고
8시간 동안 돌렸던 vit model 이다. 몇몇 vit 모델은 매우 고성능 이어서 해당서버에 있는 gpu로 돌아가지 않는 것 같다. 그래서 고안해낸 방법이 batch size를 매우 작게 줄이는 것이었고 당연히 시간이 엄청나게 걸렸다.
결과를 매우 기대했는데 초반에 20분만에 돌렸던 resnet 보다 성능이 않나왔다. 여러가지 설정을 바꿔서 다시 돌려보고 싶지만 8시간을 또 기다리고 싶지는 않다...
(어제 이거때문에 컴퓨터를 켜놓고 잤다)
오늘은 우리 조 github repository에 첫 commit을 했다. default인 master branch에서 pull해서 각자의 branch를 생성 후 작업하기로 우리 조만의 컨벤션을 정했다.
앞으로는 팀원들과의 협업이 시작되기 때문에 성능 개선도 중요하지만 당분간은 좀더 framework 개발에 중점을 두어야 할 것 같다.
오늘을 회고하며 느낀점은 내가 너무 EDA 과정을 소홀히 했던 것 같다. EDA 과정을 통해 data를 여러방면으로 살펴보면서 했어야하는데 모델을 돌리는 데 급급했었다. 다시 처음으로 돌아가 data를 살펴보는 작업을 시작해야 겠다.
또 여태까지 돌려 놓은 모델들은 torch.save 를 통해 logging 해놓는 습관도 들여야겠다.
