Intro
부스트 캠프는 U-stage 그리고 P-stage로 구분되어 있다.
U-stage에서는 이론적인 부분을 학습하며, P-stage는 project 레벨로 대회를 진행한다.
이번 P-stage에서는 Image Classification을 주제로 진행된다.
우선 P-stage를 위해 몇가지 준비할 점이 있었다.
aistage 플랫폼에서 제공하는 가상서버, 팀과 함께 협업을 위한 형상관리도구 github, 기본적인 python, pytorch와 같은 프로그래밍 지식, 그리고 AI 지식이다.
aistage 플랫폼에서 제공하는 서버는 gpu 하나가 달려있는 서버이다. 다른 서버를 원격제어할 때와 마찬가지로 ssh를 통해 해당 서버와 통신하게 된다.
ssh란 무엇일까?
ssh는 이름그대로 Secure Shell Protocol의 약자이다. 우리가 통신을 할때 여러가지 프로토콜이 있는데 그러한 프로토콜의 종류 중 하나라고 생각하면 편하다.
다른 프로토콜이 아닌 ssh 를 사용하는 이유는 안전하기 때문이다.
ssh는 기본적으로 private-key와 public-key의 쌍으로 구성되어 있다.
public-key는 암호화 용도로 사용되고, private-key는 복호화 용도로 사용된다.
aistage 플랫폼에서 서버를 생성하면 자동으로 .pem 확장자의 key가 다운로드 되는데 이것이 바로 복호화 때 사용하는 private-key의 역할을 한다. (매우 중요하므로 소중하게 보관하자 !)
ssh 연결하는 방법은 비교적 간단하다.
터미널에서 ssh -i {key위치} 사용자이름@{ip 주소} -p {port번호} 입력하면된다.
하나 복잡한 점은 window os 환경을 쓰는 경우이다.
linux기반의 os인 경우 chmod명령어를 통해 파일 권한을 수정하면 되지만
window os는 chmod명령어가 없기 때문에 직접 파일을 클릭해서 권한을 수정해주어야 한다.
(window만의 command 가 있을 수도 있지만 나는 모르겠다)
window os 파일 권한 수정방법은 구글링을 통해 쉽게 찾을 수 있다.
aistage에서 제공하는 os는 ubuntu os 이기때문에 기본적인 linux command를 공부할 필요가 생겼다.
model의 pipeline 구성하기
좋은 gpu가 장착된 서버에 연결되었으니 모델을 학습을 시킬 준비가 된 것 같다..?!
P-stage는 기본적으로 competition이기 때문에 주어진 데이터를 이용해 좋은 결과를 만들어내야 한다. 이를 위해 기본적인 model의 파이프라인을 구성할 필요가 있다.
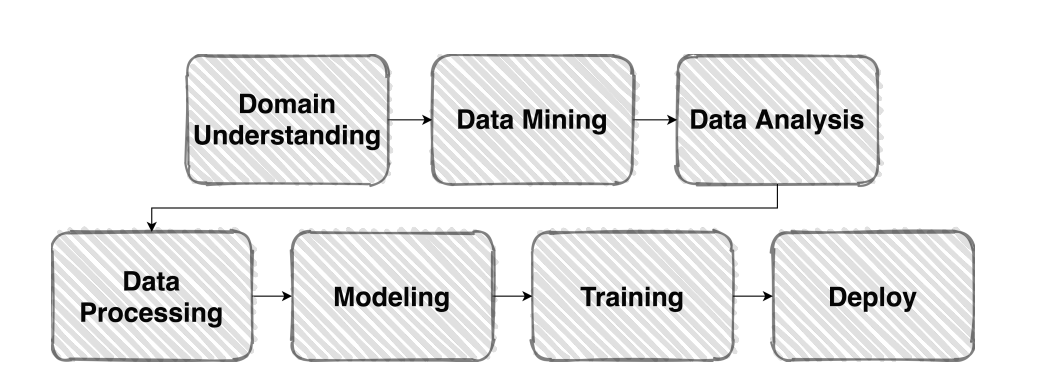
기본적인 model의 파이프 라인은 위와 같은 구성을 갖고 있다.
우선 Domain에 대해 이해를 하고 data를 수집해야 한다. 하지만 competition의 경우에는 data가 제공되는 경우가 많다. 따라서 우리는 Data Analysis로부터 시작하면 된다.
EDA(Exploratory Data Analysis)
EDA는 수집한 데이터가 들어왔을 때, 이를 다양한 각도에서 관찰하고 이해하는 과정이다.
EDA를 쉽게 풀어 이야기하면 데이터를 이해하기 위한 노력이라고 할 수 있다.
EDA가 필요한 이유는
1) 데이터의 분포 및 값을 검토함으로써 데이터가 표현하는 현상을 더 잘 이해하고, 데이터에 대한 잠재적인 문제를 발견할 수 있기 때문에, 이를 토대로 본격적인 분석에 들어가기 앞서 데이터의 수집을 결정할 수 있다.
2) 다양한 각도에서 살펴보는 과정을 통해 문제 정의 단게에서 미쳐 발생하지 못했을 다양한 패턴을 발견하고, 이를 바탕으로 기존의 가설을 수정하거나 새로운 가서을 세울 수 있다.
EDA를 수행하는 방법으로는
- 개별 데이터 관찰
- 통계 값 활용
- 시각화 활용
- 머신러닝 기법 활용
- 그 외의 이상치 발견 기법 등
여러가지를 활용할 수 있다.
프로그래밍 지식이나 AI 관련 지식은 앞으로 꾸준히 다룰 계획입니다 !
