Intro
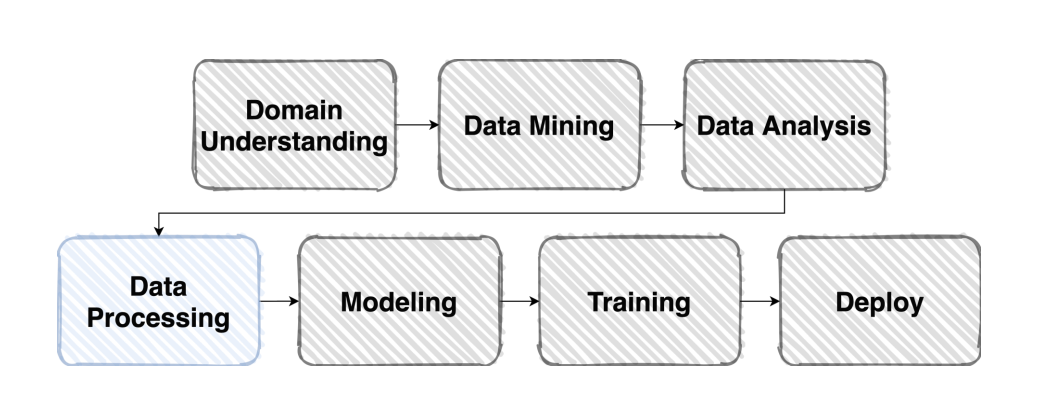
전날은 EDA를 통한 Data Analysis를 했었다면 오늘은 Data processing부터 진행해보자
1. pre-processing (전처리)
pre-processing 이란 말 그대로 data를 정제하는 과정이다. 자신이 갖고 있는 Vanilla Data를 학습하게 될 모델이 좋아하는 형태의 dataset으로 변환시켜주는 단계라고 보면 된다.
pre-processing의 방법은 정말 여러가지가 있다.
현재 진행되는 competition의 주제가 이미지 분류이기때문에 다루는 데이터는 대부분이 image 데이터이다.
강의에서 소개된 image data pre-processing 방법은 크게 2가지인데 Bounding box와 Resize 이다.
Bounding box
Bounding box는 데이터에 필요이상의 정보가 담겨 있기 때문에 그 필요이상의 정보를 줄이는 과정이다.

위의 사진을 보면 내가 분류하고 싶은 모델은 자동차 이지만 한장의 사진에는 자동차 외에 수많은 요소들이 담겨 있다. 이렇게 수많은 요소들은 사실상 학습에 필요하지 않는 데이터인 경우가 크다. 그렇기 때문에 빨간 bounding box로 필요한 부분을 지정해주는 작업은 매우 중요하다.
Resize
Resize는 단어 그대로 데이터 사이즈를 변환 시킨다.
왜 이미지 데이터의 사이즈를 변환 시켜야 할까?
적당한 크기의 사이즈로 변환시켜야 계산의 효율을 높일 수 있다. 생각해보면 당연한 말인게 사이즈가 크면 Tensor로 변환되었을 때의 크기도 크게 되고 transform 과정을 통해 이미지를 pre-processing 할때 더 많은 연산을 필요로 하게 된다.
2. Generalization (일반화)
일반화 과정의 궁극적인 이유는 학습환경이 아닌 실제 환경에서도 model이 잘 적용될 수 있도록 하는 것이다.
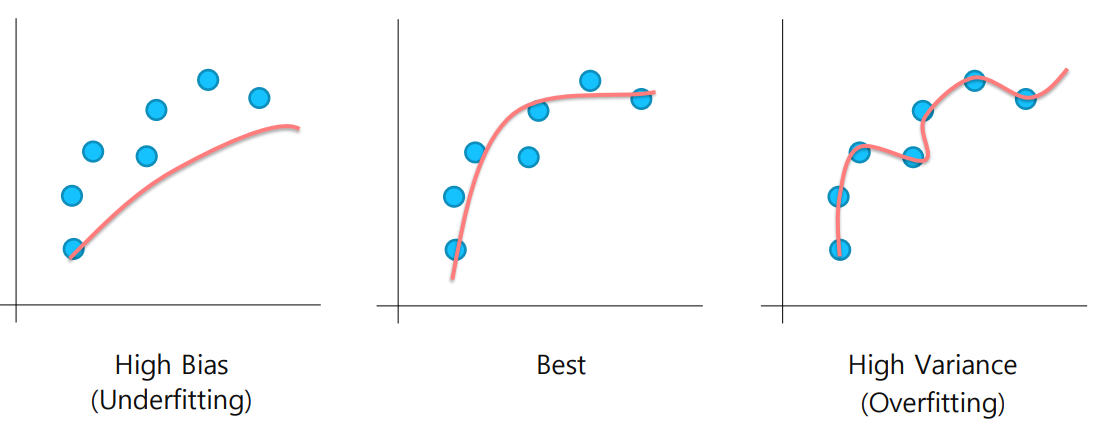
Bias & Variance
High Bias(Underfitting)은 학습이 너무 안된 경우이다.
반대로 High Variance(Overfitting)은 학습이 너무 과하게 된 경우이다.
High Variance는 언뜻 보면 좋은 결과 같지만, 실제로 model이 접해보지 못한 data로 테스트를 해보게 되면 성능이 좋지 못하다는 것을 금방 알게 된다.
Train / Validation
그래서 이때 사용하는 것이 Validation dataset 이다.
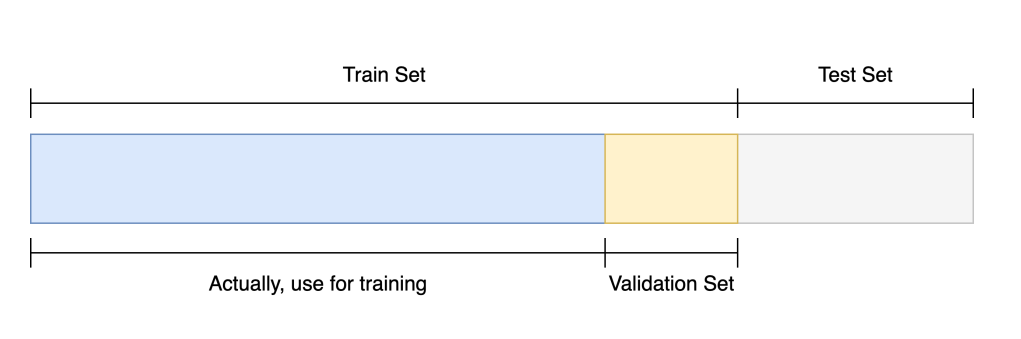
Test set의 데이터를 모델에 학습시키는 것이 cheating 이기 때문에 Train Set안에서 다시 Validation Set을 구분한다. 즉 임시의 train set을 만들어서 모델이 잘 학습되었는지 검증하는 것이다.
Data Augmentation
또 다른 방법으로는 Data Augmentation이 있다. data augmentation이란 데이터에 인위적인 변화를 가해 새로운 훈련 데이터를 대량 확보하는 방법론을 의미한다.

위의 그림 처럼 이미지를 어둡게 만들 수도 있고 이미지를 blur 처리할 수도 있으면 뒤집거나 자르거나 등 여러가지 방법이 존재한다.
이때 이용하는 함수가 바로 torchvision.transforms 이다.

torchvision.transforms만해도 충분히 종류가 많다고 느껴지지만 Albumentations라는 더빠르고 더다양한 Augmentation 전용 모듈이 있다.
3. Data Feeding
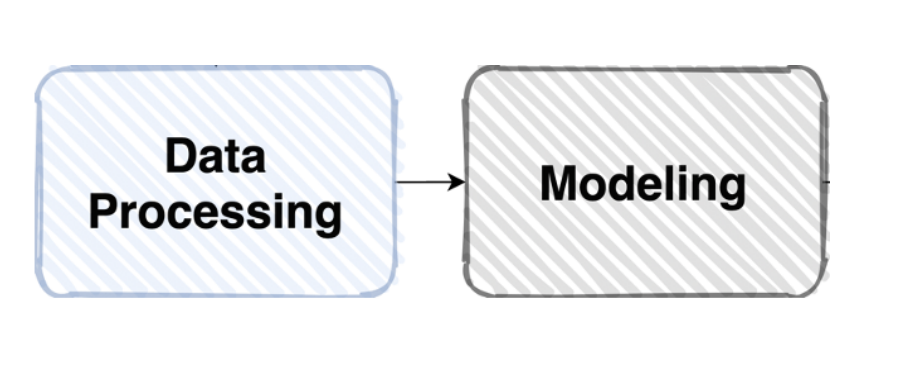
데이터의 일반화를 피하기 위해 데이터를 잘 pre-processing 해주었다면 이제 이 Data를 모델에게 Feeding 해주어야한다. 즉 모델에 잘 입력시켜주어야 한다.
먹이를 준다는 말 그대로 모델의 상태를 고려해서 적절한 양의 데이터를 피딩(feeding)해 주어야 한다.
흔히 우리는 model을 Dataset 클래스로 정의하고 DataLoader를 통해 model로 data를 피딩해준다.
이 과정에서 많은 사람들이 쉽게 오류를 범한다.
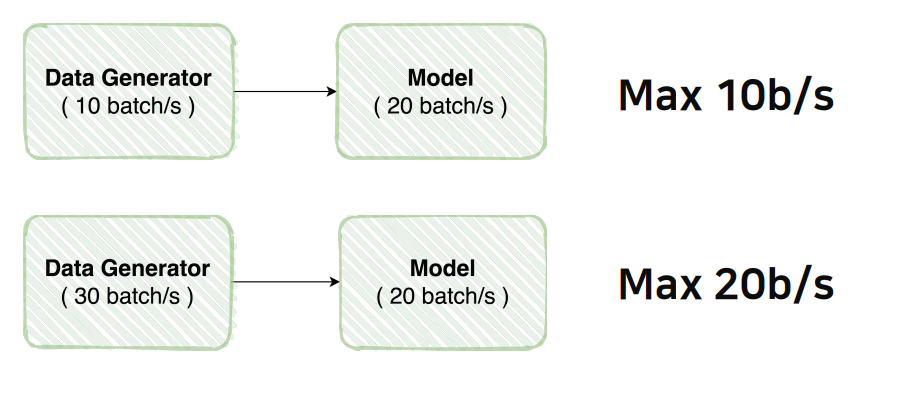
위의 그림 처럼 DataLoader의 속도와 model의 속도를 잘 고려해주어서 적절한 data 피딩을 해주는 것이 중요하다.
torch.utils.data
위에 언급한 바와 같이 Data는 크게 Dataset 과 DataLoader로 나뉜다.
Dataset은 vanilla data를 모델에 알맞는 data로 pre-processing 해주는 과정을 의미한다.
DataLoader은 정제된 Dataset을 model 피딩해주는 역할을 한다.
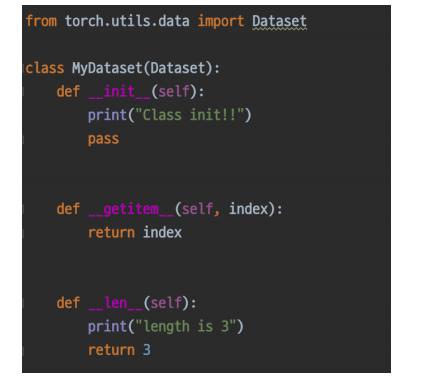
Dataset은 위의 사진과 같은 구조의 class로 선언한다.
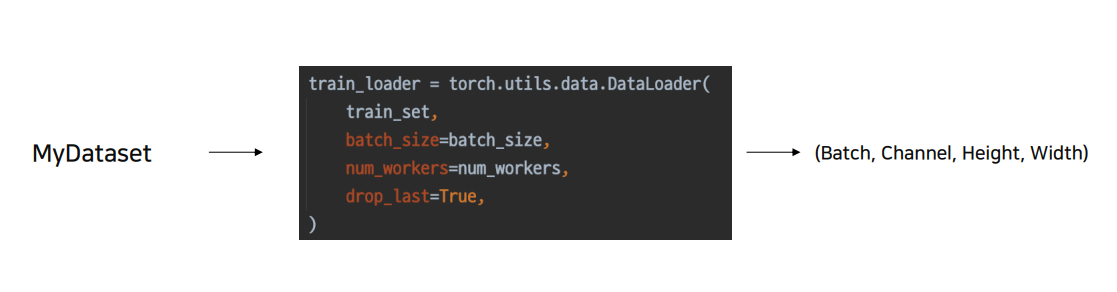
DataLoader 또한 직접 class의 형태로 구현해주어도 상관 없지만 주로 torch.utils.data.DataLoader의 class에 인자를 넣어 객체를 생성하는 방식으로 많이 한다.
Dataset 과 DataLoader의 역할을 다시 한번 분류 해보자
- Dataset : Vanilla 데이터를 원하는 형태로 출력해주는 클래스
- DataLoader : Dataset을 더 효율적으로 사용하기 위함
개인 학습 회고
오늘의 aistage 플랫폼에 모델 제출만을 목표로 하였다.
학습은 매우 기본적인 CNN 모델을 이용해서 학습하였다.
제일 애를 먹은 부분은 이미지 경로를 mapping 시켜주는 부분이다..
모든 데이터가 똑같은 확장자 였으면 좋겠지만 어떤 이미지 파일은 jpg, 어떤 이미지 파일은 png, 아니면 jpeg , 정말 중구난방 이었다.
심지어 더 최악이어었던 점은 DataLoader를 통해 Model에 Data를 피딩할 때에 발견 했는데
한 이미지 폴더에 여러가지 확장자가 섞여있는 것이 있었다.
0002_female_Asian_45
├── incorrect_maks.jpg
├── mask1.jpg
├── mask2.jpg
├── mask3.jpg
├── mask4.jpg
├── mask5.jpeg
└── normal.jpg
이렇게 항상 mask5가 문제였다.
우여곡절해서 학습을 마무리 할 수 있었다.
(Accuracy는 정말 낮았다)
내일은 아무래도 pre-trained model을 사용해서 학습을 시켜봐야 겠다.
비록 정확도는 낮았지만 처음으로 data pre-processing 부터 data feeding 모델 학습 까지 내 손으로 직접 해보았기 때문에 감회가 새롭다.
