
Overview
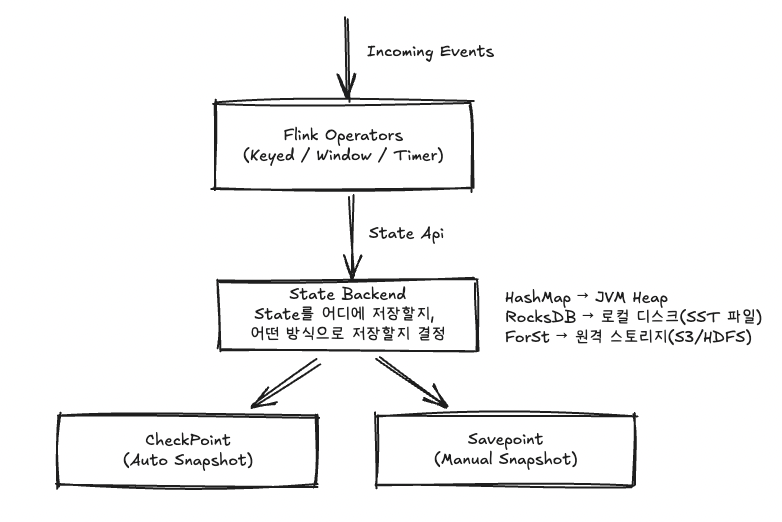
스트림 처리 시스템은 데이터가 끊임없이 들어오기 때문에, “지금 어떤 계산을 하고 있으며 어디까지 처리했는가”를 항상 기억해야 한다. Apache Flink에서는 이러한 정보가 모두 State(상태) 로 관리된다. 집계 결과의 중간값, 윈도우에 쌓여 있는 이벤트, 등록된 타이머, 외부 시스템의 읽기 위치(offset) 등이 모두 이 상태에 포함된다. 문제는 이 상태가 기본적으로 메모리에 있기 때문에, 장애가 생기면 그대로 사라질 수 있다는 점이다. Flink가 안정적으로 스트림 처리를 이어갈 수 있는 이유는 이 상태를 안전하게 저장하는 두 장치, Checkpoint와 Savepoint를 갖고 있기 때문이다.
1. Status
Flink가 실행 중 유지하는 작업의 현재 상황
Status는 Flink가 작업을 이어가기 위해 필요한 정보 묶음이다. 예를 들어 키별 합계를 계산하는 경우, 각 키에 대한 현재 합산 값이 상태로 저장된다. 윈도우 연산자는 특정 시간 범위에 들어온 이벤트들을 상태로 갖고 있어야 하고, Kafka에서 데이터를 읽는 연산자는 “어디까지 읽었는지”를 상태로 기록한다. 이처럼 State는 스트림 처리가 중단 없이 이어지기 위한 기초 자료지만, 장애가 나면 즉시 사라질 수 있다. 그래서 Flink는 이 상태를 정기적으로 외부에 저장하는 방식을 갖추고 있다.
2. Checkpoint
장애가 나도 되돌아갈 수 있는 자동 저장 지점
Checkpoint는 Flink가 주기적으로 자동 생성하는 상태 저장본이다. 특정 시점의 상태를 외부 스토리지(HDFS, S3 등)에 저장해 두고, 만약 작업이 실패하면 이 지점으로 돌아가 다시 시작할 수 있게 해준다. Checkpoint는 가능한 한 가볍고 빠르게 만들어지도록 설계되어 있기 때문에 실시간 스트림 처리에도 부담이 적다. 기본적으로 Checkpoint는 운영자가 관리할 필요가 없으며, 작업이 완전히 종료되거나 취소되면 자동으로 삭제된다. Checkpoint는 말 그대로 “장애 복구를 위한 자동 백업”이라고 이해하면 된다.
3. Savepoint
Job을 멈추지 않고 변경하기 위한 수동 저장 지점
Savepoint는 Checkpoint와 비슷하지만, 목적이 전혀 다르다. Savepoint는 운영자가 명령으로 직접 생성하는 저장본이며, 코드 변경·병렬도 조정·Flink 버전 업그레이드처럼 운영 측면에서 Job을 변경해야 할 때 사용하는 안전한 출발점이다. Savepoint는 이동이 가능하고 오래 보관할 수 있어, 업그레이드 후에도 이전 상태에서 그대로 이어서 실행할 수 있다. 다만 Savepoint를 사용하려면 각 연산자에 UID(고유 식별자) 를 부여해야 한다. 그래야 Savepoint 안의 상태가 어떤 연산자에 연결되어야 하는지 명확하게 구분할 수 있다. Savepoint는 “서비스를 멈추지 않고 시스템을 발전시키기 위한 관리용 백업”이다.
4. 정리
Checkpoint는 장애 복구용 자동 백업이고, Savepoint는 운영 변경을 위한 수동 백업이다.
| 항목 | 목적 | 생성 방식 | 사용 사례 | 특징 |
|---|---|---|---|---|
| Status | 실행 유지 | 내부 유지 | 스트림 처리 전반 | 휘발성 |
| Checkpoint | 장애 복구 | 자동 생성 | 실패 시 재시작 | 빠르고 가벼움 |
| Savepoint | 운영 변경 | 수동 생성 | 업그레이드, 재배포 | 안정적, UID 필요 |
Flink는 이 두 메커니즘을 기반으로 실시간 스트림 처리에서도 안정성과 일관성을 유지한다.
참고자료
- flink 공식문서 : https://flink.apache.org/
