
Overview
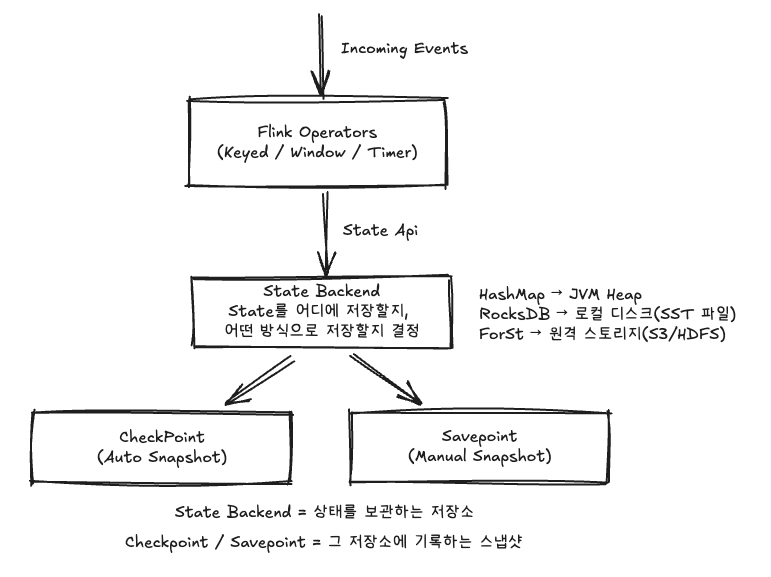
스트림 처리에서는 상태가 계속 쌓이기 때문에, Flink는 이 상태를 어떻게 저장하고 관리할지를 명확하게 정해야 한다. 이를 결정하는 구성 요소가 State Backend이다. Backend는 상태를 메모리에 둘지 디스크에 둘지, 어떤 포맷으로 저장할지, Checkpoint 시 어떤 파일을 만들지를 정의한다. 결국 State Backend는 Flink 상태 관리의 기반이며, Job의 성능·안정성·확장성에 직접적인 영향을 주는 핵심 요소이다.
1. HashMapStateBackend
HashMapStateBackend는 상태를 JVM heap에 Java 객체 형태로 저장하는 방식이다. 구조가 단순하고 메모리 접근 속도가 빠르기 때문에 가장 가볍지만, 메모리 크기와 GC 영향을 직접 받는다는 한계가 있다.
상태 접근은 빠르지만, 상태가 커질수록 GC 비용이 크게 증가한다. 상태가 JVM 메모리를 초과할 수 없기 때문에 대규모 스트림 처리에는 적합하지 않다. 디스크 I/O가 없다는 장점 덕분에 개발 환경이나 상태가 거의 없는 파이프라인에서는 유용하다. 반면, 윈도우나 키드 집계처럼 상태가 점점 증가하는 Job에는 부담이 크다.
2. EmbeddedRocksDBStateBackend
RocksDB Backend는 Flink 운영 환경에서 가장 널리 사용되는 Backend이며, 상태를 TaskManager 로컬 디스크의 RocksDB 데이터베이스에 저장한다. 모든 상태는 직렬화된 byte[] 형태로 저장되며 필요할 때 역직렬화해 사용한다. 이 방식은 메모리 한계를 벗어난 대규모 상태를 안정적으로 관리할 수 있다는 점에서 실전 적용 사례가 가장 많다.
RocksDB는 incremental checkpoint를 지원해 대규모 상태에서도 Checkpoint 비용을 크게 줄일 수 있다. 반면, 직렬화·역직렬화 비용과 compaction으로 인한 디스크 부하는 피할 수 없다. 그럼에도 불구하고 “확장성과 안정성”이라는 실전 요구사항을 충족시키는 Backend라는 점에서 사실상 표준처럼 사용된다.
3. ForStStateBackend (Flink 2.0 Disaggregated State)
ForSt는 Flink 2.0에서 도입된 새로운 Backend로, RocksDB가 가진 디스크 의존 구조를 넘어 상태 파일을 원격 스토리지(S3/HDFS)에 저장하는 방식을 채택한다. 이는 상태 저장을 TaskManager 로컬 디스크에 고정하던 기존 구조에서 한 단계 더 나아가, Compute(연산)와 Storage(상태)를 완전히 분리한 아키텍처이다.
ForSt는 TaskManager가 필요한 메타데이터와 일부 캐시만 유지하고, 실제 상태 파일은 원격 저장소에 보관한다. 덕분에 상태 크기는 사실상 무제한이 되고, Checkpoint는 파일 이동이 거의 없어 매우 가벼워진다. 장애 복구 시에도 로컬 디스크에 의존하지 않기 때문에 복구 속도가 빠르다. 단, 네트워크 지연이 존재하므로 비동기 방식(State API V2)을 반드시 사용해야 하며, 아직은 실험적이라는 제약이 있다. 클라우드 환경에서 대규모 상태를 다루는 경우에 특히 적합한 모델이다.
정리
State Backend는 Flink 상태 관리의 중심이며, 어떤 Backend를 선택하느냐에 따라 Job의 성능 구조가 크게 달라진다. HashMap은 작은 상태를 가진 단순 작업에 적합하고, RocksDB는 대부분의 실전 스트림 처리 환경에서 안정적인 선택이다. ForSt는 대규모 상태와 클라우드 기반 실행 환경을 목표로 하는 Backend로, 앞으로의 확장 가능성을 보여준다.
| Backend | 저장 위치 | 속도 | 확장성 | 적합한 환경 |
|---|---|---|---|---|
| HashMap | JVM Heap | 가장 빠름 | 낮음 | 개발 환경, 소규모 상태 |
| RocksDB | 로컬 디스크 | 중간 | 매우 높음 | 실제 운영 환경 |
| ForSt | 원격 스토리지 | 비동기 기반 | 사실상 무제한 | 대규모·클라우드 환경 |
참고자료
- flink 공식문서 : https://flink.apache.org/
