Recurrent Neural Networks (RNN)
입력, 출력 중 하나가 시퀀스이거나 둘 모두 시퀀스인 경우에 시퀀스모델(RNN)을 사용할 수 있음. 지도학습으로 처리 가능
Notations (w/ Motivating Example)
시퀀스 모델에서 입출력의 길이가 같으리라는 보장은 없다. (seq to seq 모델이라도)
- , : 입력, 출력 시퀀스 내 t번째 인덱스의 요소 (e.g., 문장에서 t번째 단어)
- , : 입력, 출력 시퀀스 길이 (e.g., 단어 개수, 단어에 대응되는 출력의 개수)
문장에서 개별단어 의 표현은 사전을 이용한 one-hot 벡터로 한다.
- 단어 집합 (=dictionary, 사전)을 만들어야 함 : 사용할 수 있는 표현들의 집합.
- 빈도수 상위의 몇 개 단어를 모아서 딕셔너리를 만들 수 있음
- : 단어 집합 크기 (단어 개수)
- 딕셔너리를 사용해서
- 인 입력 시퀀스 X의 각 단어 를
- 차원의 one-hot vector로 만든다.
- 사전에 없는 단어인 경우 UNK(unknown)로 처리(=존재하지 않는 가짜 단어로 채우기)
예를 들어 사전과 입력가 아래와 같다면
- "I want to go home and sleep"
one-hot encoding된 들은 아래와 같이 정리해볼 수 있겠다.
그러나 여기서 살펴본 나이브한 신경망은 시퀀셜한 데이터를 처리하기에 부적합하다.
특정 단어의 위치를 one-hot 벡터로 준다면 순서가 바뀔 때 대응하지 못할 것임.
인풋레이어 파라미터도 너무많다.
RNN 모델 구조
기본 신경망 구조로는 아래의 처리가 곤란
- 각 단어가 시퀀스 내에서 위치가 달라지는 경우 (일반화 안됨)
- 입출력 각 길이가 달라지는 경우
RNN은 이전 상태(time step)의 정보를 다음 상태로 전달. 시간순서가 중요한 데이터 처리에 적합.
- 단방향 RNN : 과거 정보만 사용 (미래 고려 안함)
- 를 내기 위해서 의 정보(활성화값) 사용 가능
- 그러나 의 정보는 쓸 수 없다. 미래의 정보니까.
- 양방향(BRNNs) : 미래 정보도 고려.
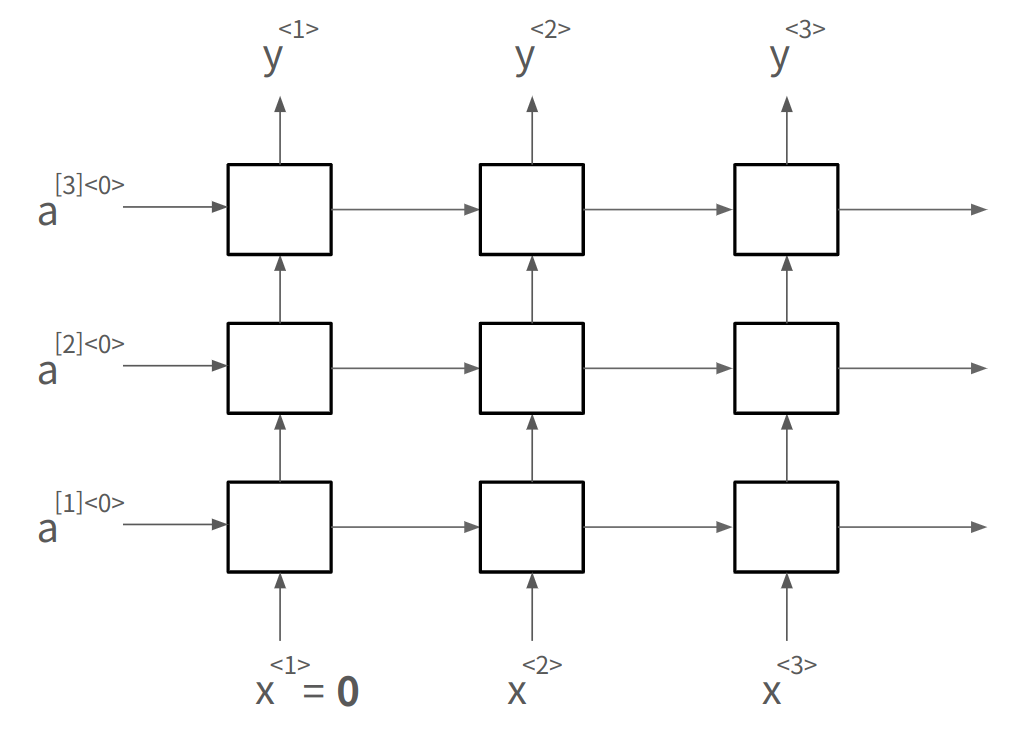
두 가지 표현 방법
- Unrolled Diagram : 모든 시간 단계 명시적으로 펼쳐 표현 (이걸 주로 쓰자)
- Recurrent Diagram : 반복되는 구조를 하나의 셀로 표현
모든 time step에서 같은 파라미터 을 공유한다.
- : 입력 에서 신경망 레이어로의 연결
- : activation 수평 연결
- : 신경망의 출력(예측값) 제어
인 경우에 대해, 아래 그림과 같이 정리해볼 수 있음.
참고로 출력값 가 다음 레이어에 들어가는 경우도 있음.
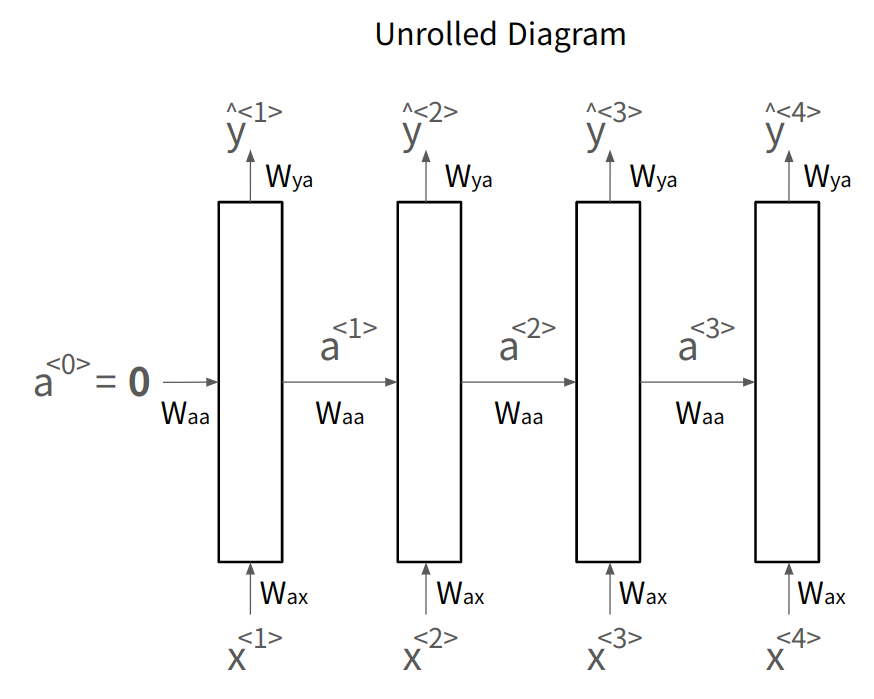
Forward Propagation에서 활성화 값, 출력, 손실을 구하면
-
- (주로 첫 활성화값은 영벡터)
- 활성화함수 보통 tanh, 가끔 ReLU
- 활성화함수 보통 sigmoid, softmax
Back Propagation은 BPTT라고 부른다. (Back Propagation Through Time)
- 적당히 역전파 값 (W, a, b의 기울기) 구해서
- 경사하강법으로 업데이트하면된다. 늘 하던것처럼.
RNN 유형
입출력에 따라 다양한 구조 있음
- 1-to-1: 일반적인 신경망 구조. 입력이 하나이고 출력도 하나인 경우. (예: 전통적인 뉴럴 네트워크)
- Many-to-One: 다수의 입력이 하나의 출력으로 이어지는 구조. (예: 감정 분석, 리뷰의 감정 점수 예측)
- One-to-Many: 하나의 입력이 다수의 출력으로 이어지는 구조. (예: 음악 생성)
- Many-to-Many (Tx = Ty): 입력 시퀀스와 출력 시퀀스의 길이가 동일한 경우. (예: 이름 엔터티 인식)
- Many-to-Many (Tx ≠ Ty): 입력 시퀀스와 출력 시퀀스의 길이가 다른 경우. (예: 기계 번역 --> Encoder-Decoder 구조 사용)
Language Model and Sequence Generation
언어모델은 주어진 문장의 확률을 예측하는 모델
자연어처리의 가장 기본이 되는 일이고 RNN이 잘하는 일.
RNN 언어모델 구축
대규모 Corpus(텍스트 말뭉치) 필요
텍스트를 Tokenize(토큰화)함. (고유한 인덱스로 매핑, one-hot 벡터로 변환)
문장 끝에 EOS (End of Setence) 추가
train example에 없는 단어는 UNK토큰으로 처리 : UNK토큰일 확률도 계산되는 것임.
RNN 언어모델 구조
RNN 언어모델은 다음 단어를 예측하는데, 문장을 생성하는데 사용할 수 있다.
첫 time-step의 입력 은 영벡터 으로 둔다.
- 그럼 첫 출력 는 뭐가됐든 어떤 단어가 다음 토큰으로 나오겠다는 예측을 한다.
두 번째 입력부터는 y(학습시키려는 문장의 토큰)으로 대체한다.
- 즉, 로 둔다.
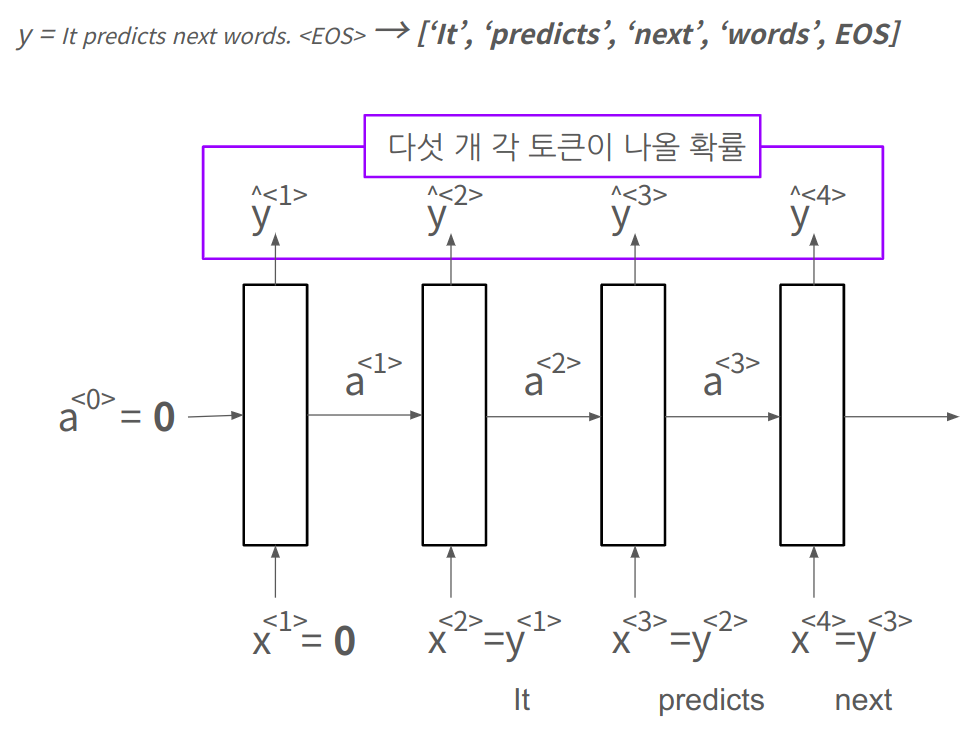
그래서 손실함수를 정의해보면 (softmax)
Sampling Novel Sequences
훈련된 모델이 무엇을 학습했는지 informal하게 알아볼 수 있는 방법
훈련된 시퀀스 모델로부터 새로운 시퀀스를 생성하기 위해 샘플링
하는 방법은
- 첫번재 Time-step에 a, x 영벡터로 넣어주고, dictionary에서 아무 단어(vocabulary, word) 하나 골라서 출력
- 이제부터 을 다음 입력 에 넣음
- 그럼 학습한대로 문장을 만들 것임
언제 까지 함? : 문장이 끝날때 까지
- EOS가 사전에 있다면 : EOS 나올 때 까지
- EOS가 사전에 없다면 : 적절한 길이 (단어개수든 글자개수든) 지정.
아주 운좋게 첫번째 예측단어로 It이 나왔다고 해보자.
학습이 아주 야무지게 됐다면 아래처럼 샘플링이 돼서 예쁜 문장을 만들어 줄 것.

토큰 단위에 따른 언어모델
- Vocabulary-level model : 단어(e.g., lion, wonjin, a, UNK) 단위로 샘플링
- 장점 : 장기적 종속성 잘 학습 (Capturing long range dependencies)
- Character-level model : 글자(e.g., a, b, c, 공백, 2) 단위로 샘플링
- 장점 : 단어레벨 모델에서는 UNK로 처리해야 됐던걸 글자단위 모델에서는 뭔가로 매핑 가능
- 단점 : 계산비용 비쌈. 장기적 종속성 학습 어려움.
기울기 소실과 폭발 (Vanishing, Exploding Gradients)
RNN에서 기울기가 폭발한다는 것은
- 그냥 원래 알던 그거 맞다. 파라미터가 너무 커져서(기울기가 커져서) 수렴못하는 것.
RNN에서 기울기가 소실된다는 것은
- 긴 시퀀스를 처리할 때 앞쪽의 정보가 뒤쪽부분에 전달되지 못하는 것
- 기본적인 RNN은 태생적으로 가까이에서 오는 (지역적인) 입력에 의해 영향을 받기 때문임.
- Capturing long-range dependencies에 그닥 좋지 못하다고 표현한다.
- 해결법의 예시
- GRU (Gated Recurrent Units)
- LSTM (Long short term memory)
변형된 RNN
GRU
time-step 마다 메모리 셀 를 사용
- 요소
- : 메모리 셀 (저장해서 뒤에 알려줘야 될 내용 저장)
- : Update Gate
- : Relevent Gate
- ) : 후보 셀
- 동작 방법
- 입력으로 가 들어온다
- 후보셀과 업데이트 게이트를 계산한다
- 아래 식에 따라 이번 time-step의 메모리셀 내용을 후보셀로 바꿀지, 기존 메모리셀 내용으로 유지할지 결정
- 는 element-wise 곱
- 결정된 는 소프트맥스같은걸 거쳐서 로도 만들 수 있음.
- 차원
- 는 같은 차원의 행렬임. 원하면 정수 비트일 수도 있고.
- 참고 : GRU는 LSTM보다 구조가 단순한데 비슷한 성능 보여주는 경우 많음.
LSTM
GRU의 아이디어와 유사. 좀 더 일반화된 버전. 그런데 라고 보장할 수 없다.
- 요소
- : Update gate - 메모리셀 업데이트 할지 결정
- : Forget gate - 메모리셀에서 과거 정보를 잊을지 결정
- : Output gate - 현재 메모리셀 정보를 출력할지 결정
- 동작
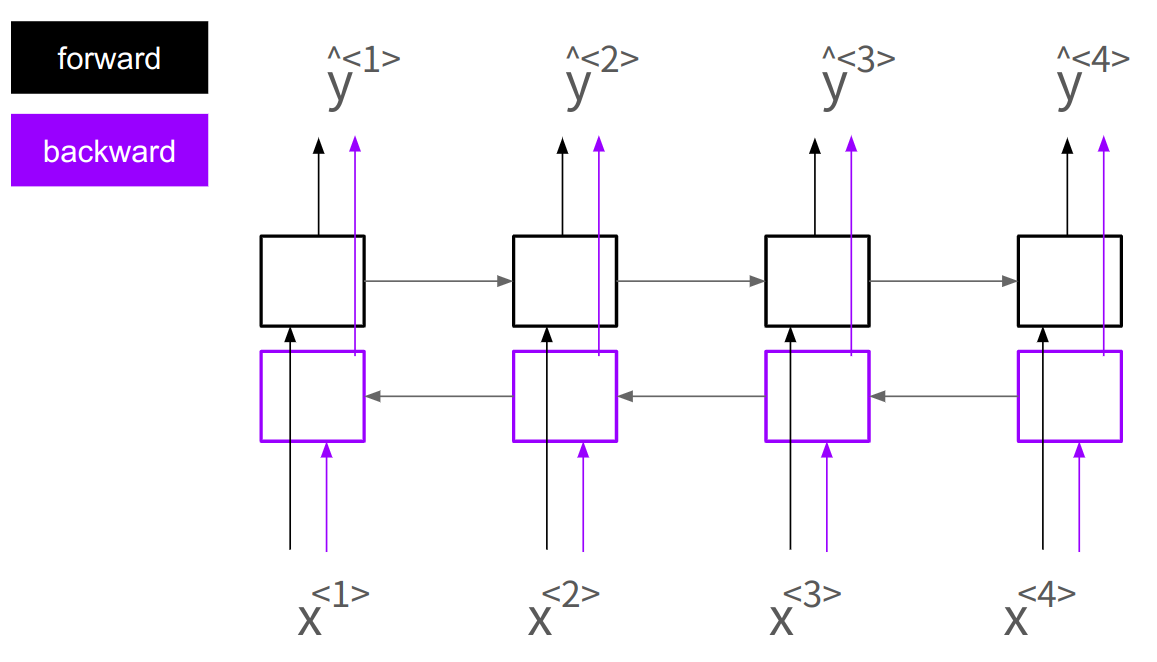
BRNN (Bidirectional RNN)
단방향 RNN처럼 앞의 데이터도 사용할 수 있고, 여기에 더해 뒤쪽의 데이터도 사용가능.
시퀀스를 양쪽으로, 앞->뒤, 뒤->앞 두 번 처리한다.
- 시퀀스의 각 입력에 대해 두 개의 RNN이 작동하는거나 마찬가지.
활용
- NLP에서 유용. 문장내 단어, 문맥 분석할 때 앞뒤정보를 다 볼 수 있으니까
- NLP에서 문장단위 작업 처리할 때 양방향 LSTM 많이 씀.
한계
- 전체 시퀀스를 다 받아야 예측값을 낼 수 있어서 실시간처리에는 좀 곤란.
- 성능문제 해결하려면 더 복잡한 모델 필요함.
Deep RNN
이제껏 본 기본 RNN은 레이어가 1개였다.
이제 여러 레이어를 쓴다. 앞 레이어의 출력 가 다음 레이어의 입력이 된다.
앞의 레이어가 저수준 패턴을, 뒤쪽의 레이어가 복잡한 패턴을 학습한다.
NLP & Word Embeddings
단어 임베딩 개요
임베딩은 인코딩과 비슷한 말이다.
왜함?
- 위에서 언급한 원핫벡터는 단어간 유사성을 반영하지 못함.
- 그러나 고차원의 벡터로 표현(임베딩)하면 단어간 유사성을 반영할 수 있어 일반화가 쉬워짐.
- NLP모델이 더 정교한 관계(유사성)를 학습할 수 있게 됨. - 대규모 비지도학습
- e.g., durian이 과일이라는 것을 알면, durian을 본적 없지만 orange와 어느정도 가깝다는 점을 알아챔
- 본적없는 문제를 푼다는 점에서 얼굴인식과 유사하다. 다만 얼굴인식은 항상 새로운 얼굴을 처리하지만 워드임베딩은 고정된 집합에 대한 문제를 푼다.
- 데이터셋이 적을 때 유용하다. (인터넷에서 긁으면 되고, 프리트레인된거 가져와서 파인튜닝해도 되니까)
구성요소
- 여러 차원의 특징 feature (성별, 특정 카테고리에 속하는지 여부)
- 원핫벡터가 아닌 피쳐에 대한 값으로 나타낸다는 점에서 featurized representation
시각화
- 피쳐는 보통 많다. 300개피쳐(300차원) 공간은 상상하기 힘들다
t-SNE같은걸 쓰면 좋다.- 주의 : t-sne은 매우복잡한 비선형과정을 거쳐 2차원에 매핑하므로, 비슷한 관계가 비슷한 벡터방향을 보여줄거라고 예측하면 안된다. 애초에 2차원이 아닌걸 2차원으로 보여주는거다.
단어 임베딩 특징 : 유추(Analogy)
man-woman의 벡터 차이는 king-queen의 벡터 차이와 유사하다.
- 둘의 차이는 성별 차이에 대한 패턴을 의미한다.
- 임베딩을 사용해 둘의 차이를 학습한 알고리즘은, 이걸 들고 다른데 가서 또 유추할 수 있다.
- Linguistic Regularities in Continuous Space Word Representations
- 처음보는 단어 찾기 : argmax similarity()
새로운 단어를 찾기 위해서 코사인 유사도 사용.
- 두 벡터의 각도로 유사도 측정 (1:같은방향, 0:직각, -1:반대방향)
- 정규화도 되니까 다양한 길이의 벡터 비교에 좋음
Embedding Matrix
단어임베딩 학습때 학습하는게 임베딩 매트릭스 다.
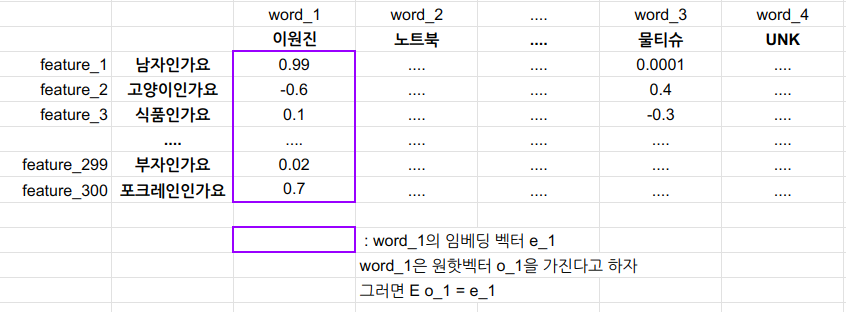
- 어떤 단어가 원핫벡터 를 갖는다고 하자. (4312번째 요소만 1이고 나머지 0인 벡터)
- 이 단어의 임베딩 벡터는
- 는 해당 단어의 특징을 표현한다.
Word embedding 학습
원리
- 언어모델(다음단어 예측)로 단어임베딩 학습 가능
- 문장 내 단어들 원핫벡터로 표현, 임베딩 벡터 구해서 신경망 입력으로 넣기
- 문장이 길다고 다 고려해서 다음 단어 예측하는게 아님. 몇 개 볼지 고정함 (fixed history window)
- 입력 개수 일정해지는 이점.
- 문맥은 다양하게 설정할 수 있음
- 다음단어가 아니라 앞 뒤 2개 단어씩 봐서 중간단어 예측을 목표로 학습할 수도.
- 바로 전 단어만 보고 다음단어 예측하도록 할 수도. (skip-gram에 유사)
- 문맥이 간단해도 되는거맞음? : 이거 언어모델 만드는게 아니다. 단어임베딩은 문맥이 간단해도 된다.
단순한 문맥을 사용하는 대표적인 모델 Word2Vec
학습방식에 따른 두 가지 모델로 나뉨 : Skip-gram, CBOW
Skip-gram
- 주어진 단어(컨텍스트) 주변의 단어(타겟)을 예측하는 문제 학습
- 샘플링은 균형잡힌 학습이 가능하도록 할 수 있음 (랜덤해도 되긴 함)
- 덜 등장하는 단어도 적절히 학습되도록 함
- 임베딩벡터를 소프트맥스에 입력, 타겟단어가 나올 확률 예측
- 모든 단어에 대해 확률 계산하니까 성능작살남
- 그래서 계층적 소프트맥스 방법 사용 (트리가 대칭적이지는 않음)
- 자주등장하는 단어는 트리 상위에서 가르고, 덜 등장하는건 하위에서 가름.
CBOW (Continuous Bag of Words)
- Skip-gram모델와 반대
- 타겟단어 주변의 컨텍스트를 학습
Negative Sampling
Skip-gram은 소프트맥스 확률을 너무 많이내서 성능이 안좋으니까
계층적 소프트맥스에 대신 네거티브 샘플링이라는 방법을 도입해서 보완할 수 있음
- 키 아이디어 : 이진분류 문제로 바꿔서 해결합시다. 싹다 소프트맥스돌리지 말고 몇개만 뽑아서 이진분류 합시다.
- 지도학습이다. 그럼 데이터셋이 필요하다
방법 (train set 뽑기)
- 컨텍스트 타겟 단어 a를 고른다.
- 가까운 단어 a, b를 positive example()로 둔다 ( =target=1)
- a와 무작위 단어들의 관계를 묶어서 각각 negative example로 둔다 (target=0)
- (무작위라고 하지만 단어빈도에 기반한 확률적 방법으로 선택. 단어빈도에 대해 확률)
- negative exmaple의 개수 는
- 큰 데이터셋에 대해 2~5개
- 작은 데이터셋에 대해 5~20개
- a를 (context), 뽑힌 단어들을 라고 한다.
- 와 의 관계가 =target=1일 확률을 예측하는 문제를 풀자
- (두 단어가 윈도우 크기내에 있는 이웃이냐 아니냐)
- Logistic classification
GloVe Word Vectors
GloVe : Global vectors for word representation
단어 임베딩학습에 단어의 전역적인 동시 발생 빈도 활용 (Word2Vec이 주변의 문맥을 이용한 반면)
특징
- 전역 문맥 활융. 다양한 정보 반영된 임베딩 학습
- 단순한 수학적 모델. 행렬인수분해와 유사한 학습과정
- 유연한 가중치 함수.
Co-occurrence matrix (공동출현행렬)
- text corpus에서 단어 와 가 함께(단어쌍) 나타나는 횟수 세서 기록한 행렬
- i는 c(context), j는 t(target)
- 즉, 는 i의 컨텍스트에서 j가 나타난 횟수
- symetric 행렬이다. ()
아래 함수 J를 최소화하는게 목표
단어 임베딩 활용 : Sentiment classification
리뷰 내용으로 별점을 예측한다고 하자.
단순하게는 단어임베딩을 쓸 수 있다.
단어별로 싹다 임베딩벡터 구해서 적당한 식 avgmax한 다음 소프트맥스 돌려버리기
- 문제 : 단어순서가 무시됨. not good인데 good많이나온다고 별점5점이라고 헛소리할 수 있음
- 장점 : 단어 순서를 무시하고 모든 평균을 취하니까, 리뷰길이 상관없이 적용가능.
복잡하게는 many-to-one RNN모델을 쓸 수 있다.
- 문장의 단어들 임베딩벡터 구해서 RNN입력에 넣기
- 마지막 토큰 활성화값을 소프트맥스에 넣어서 별점 예측하기
- 순서를 고려한다. 순서 갖다버리는 임베딩모델 문제 해결 (not good을 나쁜평이라고 이해)
dibaiasing word embeddings
단어 임베딩은 세상에 존재하는 데이터로 학습. 편견도 학습.
일반적인 경향으로 볼 수도 있지만 정답으로 단정짓도록 학습시키는 것이 올바르지 않을 수 있음
- 성별, 인종, 지위 등
- e.g., 남자는 의사, 여자는 간호사 / 남자는 직장인, 여자는 주부 등
디바이어싱 방법
- Identify bias direction
- Neutralization : 편향축에 투영하여 편향 제거
- Equalization pairs : 반대 단어쌍이 어떤 편향가능성 있는 단어와 같은 거리를 갖도록 조정 (할머니, 할아버지는 베이비시터와 같은 거리인 것이 적절)
Sequance to Sequence Architectures
기본구조
seq2seq모델의 기본 구조는 Encoder-Decoder
- 인코더 네트워크(GRU 등)가 입력을 벡터로 전환
- 디코더 네트워크가 벡터를 출력시퀀스로 전환.
- 충분한 데이터가 주어지면 잘 동작
- 예시
- 이미지 캡셔닝 : cnn으로 이미지 인코딩, rnn으로 이미지 설명 문장(단어들) 출력
- NLP(기계번역, 텍스트요약)
가장 가능성있는 예측을 내놓는 것이 좋다. 랜덤한것보단.
- 언어모델은 문장의 확률을 추정한다. seq2seq모델은 입력이 있지만, 언어모델은 입력이 없다. 문장을 무작위로 생성할 수도 있다.
- 조건부 언어 모델은 다르다. (seq2seq. e.g., 기계번역)
- 인코딩 네트워크가 내놓은 벡터(문장의 확률)이 입력으로 주어진다.
- 여기에 대해 가장 가능성이 높은 디코딩 출력을 내놓는게 목표.
조건부 언어 모델의 예시 기계번역에서 가장 적합한 번역문장을 선택하는 방법은
- 번역(출력)문장 임의선택 하지 않기
- Greedy Search : 단어단어별로 가장 가능성이 높은것들만 선택
- 그러나 전체문장의 확률이 높아진다는 보장은 없음.
- Beam Search :
- 좋은 출력 내겠다고 해서 모든 가능한 출력 경우의수를 따져보는건 비현실적.
- 최적의 번역출력을 내기 위해 탐색알고리즘 활용. (근사적)
- Beam Search는 가능한 번역들 중 가장 좋은 번역을 효율적으로 찾는 알고리즘.
- 확률을 최대화하는 출력을 찾는 것을 성공하지는 못하지만 그런대로 괜찮다.
- 어쨌든 랜덤출력 내는 언어모델보다는 낫다.
Beam Search
기계번역, 음성인식 입력을 받아 가장 적합한 텍스트 출력을 선택하는데 사용
가능한 여러 출력을 놓고 비교해서 가장 가능성 높은 것 선택 (무작위 아님)
- 근사 알고리즘이라 BFS, DFS같은 완전탐색보다는 절 정확하지만 효율적
- 대신 당연히 최적해를 못찾을 가능성도 있음.
Beam Width :
- 하이퍼파라미터. 동시에 고려할 후보의 수
- 3이면 한 Step에 3개 놓고 비교
- 1이면 Greedy Search다.
- 클 수록 정확도가 증가하지만 메모리 사용량과 계산속도도 같이 나빠진다.
- 보통 10. 연구목적으로는 1000~3000쓰지만 드라마틱한 성능향상은 없음.
작동방식 :
- 입력 받아서 이를 기반으로 다음에 올 확률 높은 단어 개 중에서 하나 선택
- 처음에 들어오는 입력은 인코더 벡터고, 그 다음은 단어.
- 확률은 소프트맥스로 볼 수 있겠다.
Length Normalization
- Beam Search는 입력문장을 기반으로 확률을 계산하기 때문에, 짧은 문장이 입력으로 올 수록 유리함
- 단어가 많으면 확률의 곱은 더 작아진다.
- 해결1 : 확률에 로그 취하고 곱하기 대신 덧셈하기. 안정적인 수치계산.
- 긴 문장도 잘 평가
- 해결2 : 문장길이 보정
- 로그확률의 합을 문장길이 로 나누어 정규화
- 얼마로 나눌지는 하이퍼파라미터. (문장길이로 나누기, 문장길이^0.7로 나누기 ...)
- 결과적으로 긴 문장이 불리하지 않도록 조정
오류 분석
- 최적해를 못찾을 수도 있다. 그 때 바로잡아줘야된다.
- 잘못됐을 때 RNN모델 때문인지 Beam Search때문인지 구분해야 한다.
- RNN모델(인코더+디코더)는 확률 를 계산 (사람이 쓴 정도의 출력)
- Beam Search는 확률 를 계산 (알고리즘이 고른 출력)
- 그러니 와 를 비교해서 더 못한 쪽이 잘못이다.
Bleu Score
Bilingual Evaluation Understudy Score
기계번역 시스템의 성능을 자동으로 평가하는 방법. 실수평가 메트릭.
좋은점
- 자동평가됨
- 지표 하나라서 보기 좋음.
주요 아이디어는
- reference(참조 번역)과 얼마나 비슷한지 비교
- 비슷할수록 좋은 점수
- Precision 측정
- 기계번역 출력에서 등장하는 단어가 참조번역에서 얼마나 많이 나오냐?
- 수정된 Precision : 참조번역의 빈도를 상한으로 점수 줌
- 많이 나올수록 좋은 점수
- n-gram 분석
- n-gram은 연속된 단어의 묶음. 단어 순서를 고려함.
- unigram 한 단어, bigram 두 개 연속단어, trigram 세 개 연속단어
- n-gram이 참조번역에서 많이 등장할 수록 좋은 점수
- uni, bi, trigram 점수 평균내서 최종 점수로 씀
기계번역 말고 다른 자연어생성(e.g., 이미지캡셔닝)에서도 쓸 수 있다.
- speech recognition은 안됨 (얘는 정답이 딱 정해져있는거라서)
Attention Model
기존 인코더-디코더 RNN구조에 변화를 줘서 개선한 모델. 특히 긴 문장 처리 효과적.
기계번역 목적으로 개발했는데 다른 응용분야(e.g., 이미지캡셔닝)에도 활용.
사람이 번역하는 방식과 유사하게 동작. (문장 한번에 다 처리하는게 아니라 특정 부분에 집중)
인코더-디코더 구조의 한계는
- 입력 문장을 인코더가 싹다 읽어서 벡터로 만들고 나서야 디코더가 일함
- 긴 문장일 수록 전체 문장을 기억하고 동작하는게 어려워서 성능 저하.
- 이 점을 개선하기 위해 어텐션모델 도입
어텐션 모델 구조
- 입력문장 인코딩 : BRNN으로 인코딩. 각 단어 특징은 전후방 RNN출력 결합해서 산출.
- 출력문장 디코딩 : 단방향 RNN으로 번역문장 생성. 각 Time step에서 어텐션 가중치를 사용해 입력 문장을 참고.
Attention Weights :
- 번역문장 각 단어 생성할 때마다, 입력문장의 각 단어에 대한 중요도를 나타내는 가중치 계산.
- 출력낼 때 입력에서 어떤 부분에 주의해야 할 지 결정
- 단어 W로 시작하는 출력 낼 때 입력에서 W부분에 가중치 왕창 때림. 주변 단어들에 주의해서 출력 산출
- 직관적으로 : 번역 과정의 각 time step마다 입력의 부분을 선택적으로 참조.
- 특정 부분에 집중할 수 있으므로 전체문장을 통으로 기억하려고 애쓰는 기존 인코더-디코더보다 긴 문장입력에 잘 작동.
- 정확하게 값으로 표현. 소프트맥스 함수의 출력값. (가중치 알파의 합은 1)
- Amount of attention should pay to
Context vector :
- 출력 단어 생성할 때 마다, 해당 단어와 관련된 입력단어의 feature벡터를 attention weights로 가중합해서 계산된 벡터.
- 해당 시점에서 생성할 출력단어 결정할 때 사용.
문제 :
- 시간 오래걸림. 2차시간. (니까)
Speech Recognition
seq2seq모델이 발전하면서 음성인식 기술 크게 향상됨.
음성인식은 오디오클립X를 받아 텍스트전사Y를 자동 생성하는 기술.
- 오디오 클립은 시간에 따른 공기압력(주파수)의 변화
일반
음성인식 방식 변화
- 전통적인 방법 : 음소(Phonemes)기반으로 음성을 텍스트로 변환. 핸드엔지니어링.
- 딥러닝 : 그냥 음성파일 박아버림.
- 대규모 데이터 세트와 딥러닝알고리즘 조합으로 음성인식 발전
시스템 구조
- Attention모델 사용 가능.
- CTC 비용함수도 사용 (Connectionist Temporal Classification)
- 입출력 시퀀스 길이가 일치하지 않는 문제 해결. (중복문자 허용, 특수 공백문자 삽입)
- 긴 오디오 클립을 받아서 짦은 텍스트 출력 가능
Trigger Word Detection
특정 단어를 감지하면 장치를 활성화하는 시스템 (알렉사, 시리)
RNN으로 오디오데이터 처리, 특정 단어를 감지.
시스템 구조
- 오디오 클립 입력 : 스펙트로그램 계산. 주파수 강도를 feature로 사용
- 오디오 피쳐 처리 : RNN, GRU, SLTM 등 시퀀스 모델로 피쳐 처리
- 타겟 라벨 설정(출력) :
- RNN출력은 특정 Time step에서 0 또는 1
- 트리거 단어 감지 전에 0, 감지 후 1 출력
불균형 데이터 문제
- 대부분의 경우 0을 출력하므로 훈련데이터 불균형
- 트리거 단어 이후 여러 timestep에 걸쳐 1을 출력하게 만들면 불균형문제 완화가능.
Transfomers
- 기존 시퀀스 모델이 순차적으로 데이터를 처리하는데 반해 트랜스포머는 병렬처리 가능.
- NLP모델 성능 크게 향상시킨 모델
- 어텐션 매커니즘과 CNN스타일의 병렬처리 결합
- 복잡한 시퀀스 작업에 유리
주요 개념으로
- Self Attention
- Multi-Head Attention
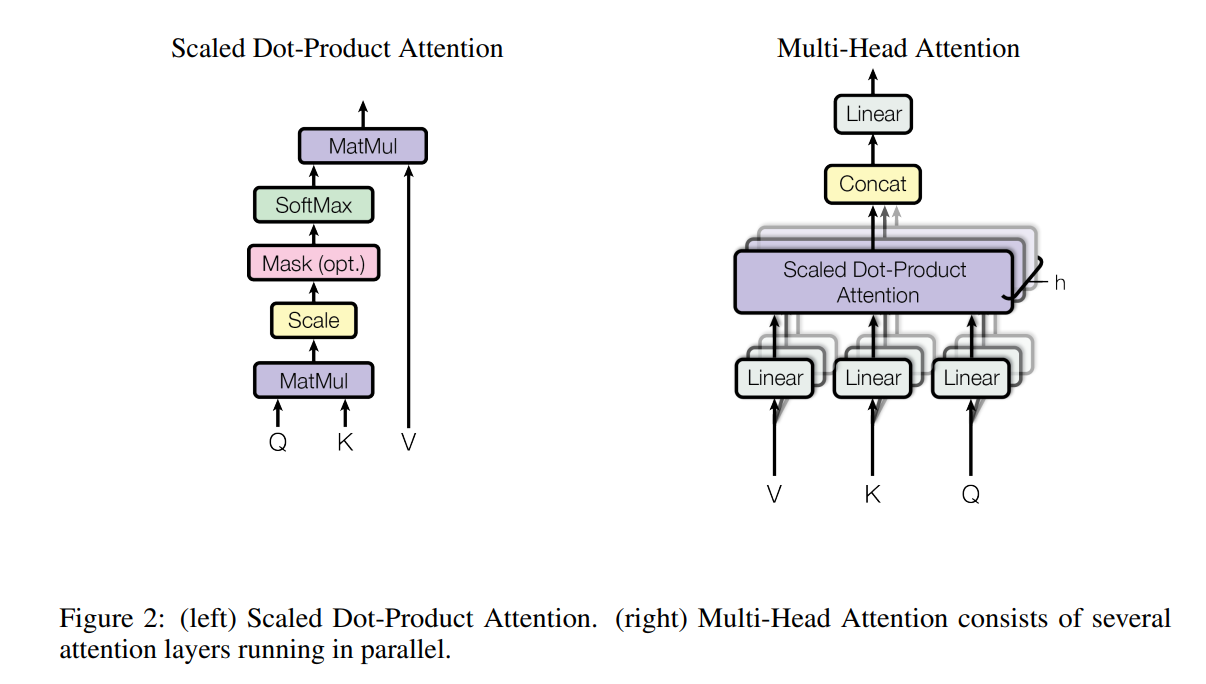
Self Attention
각 단어는 Query, Key, Value 세 백터로 변환
셀프 어텐션 계산
attention-based vector representation of a word
- : Query(Question) - 해당 단어에 대한 질문
- : Key -
문장의 단어끼리 계산
- 의 내적 = 단어 i에 대한 답을 단어 j가 얼마나 잘 주냐?
- 내적값에 곱하기
이걸 단어 i의 와 다른 모든 단어의 k, v에 대해 구해서 다 더함
- 이걸 모든 단어에 대해 구해서 다 더함
(Vectorized, Compressed) Scaled Dot-project Attention
- 분모에 제곱근 저거 뭐임? : 기울기 폭발하지 말라고 넣어줌
Multi-Head Attention
셀프어텐션은 단어마다 q, k, v를 가졌다.
멀티헤드 어텐션에서는 단어마다 를 갖는다
- 멀티헤드 어텐션은 Head가 여러개. 헤드는 feature와 비슷하다고 봐도 됨.
- : head의 개수
- 의 는 헤드 번호
셀프어텐션에서는 어텐션을 한 번 계산했는데, 멀티헤드 어텐션은 번 한다.
그냥 하던거 여러 번 하는거다. 개념적으로는 셀프어텐션의 loop와 같다(실제 계산은 병렬임).
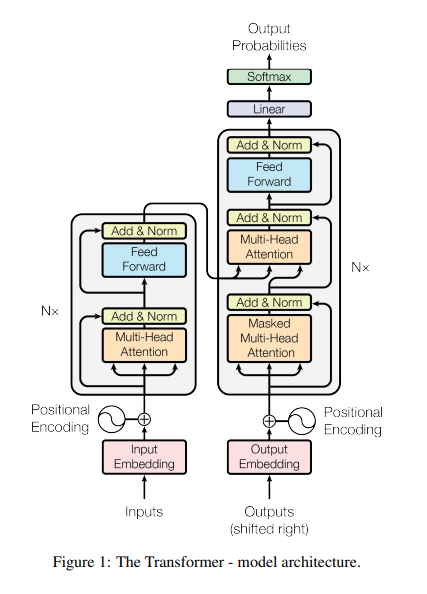
Tranformer Networks
구조
- 인코더
- 입력시퀀스 임베딩을 블록에 넣어줌
- Q, K, V 계산해서 멀티헤드 어텐션 값 구함
- 어텐션 값들을 Feed Forward Neural Network를 거쳐 블록의 출력을 냄
- 이걸 n번 반복 (보통 n=6)
- 디코더
- 인코더 출력으로 Q,K,V 계산해서 디코더 블록의 첫 번째 멀티헤드 어텐션 구함
- 첫 번째 멀티헤드 어텐션의 출력은 Q로서 다음 멀티헤드 어텐션 계산에 사용
- 다음 멀티헤드 어텐션 계산에 인코더 출력을 K, V로 사용
- 두 번째 멀티헤드 어텐션 값은 Feed Forward Neural Network를 거쳐 블록출력 산출
Positional Encoding
- 두 개 함수를 사용해 각 단어의 문장 내 위치 나타냄 (고유한 위치 인코딩 벡터 생성)
- 단어 의 위치인코딩벡터
- 구해서 블록에 넣기 전에 더해줌.
아래 피겨에서 멀티헤드 어텐션 레이어 뒤에 있는건 ResNet을 떠올리면 됨.