분류기 (Classifier)
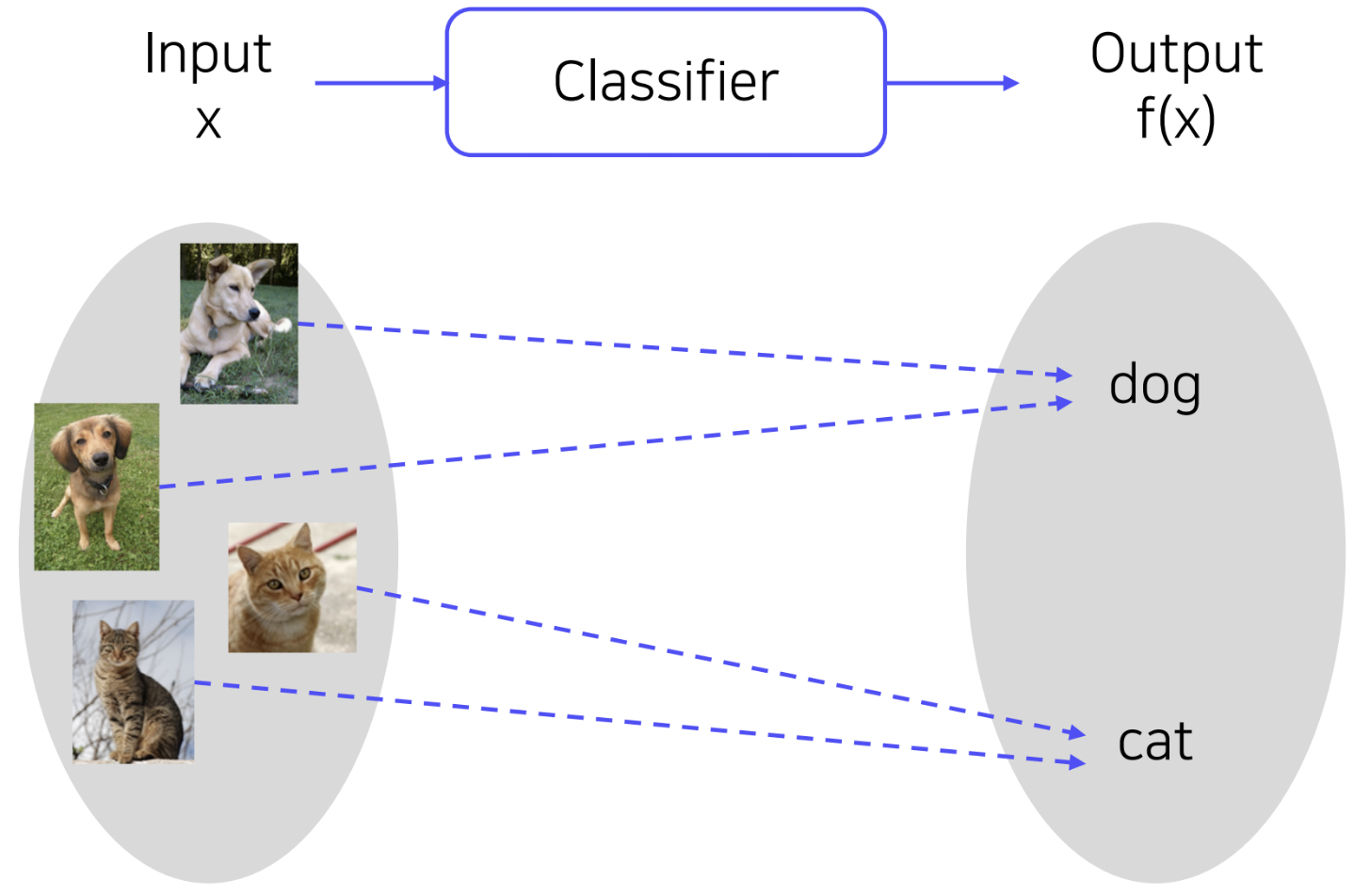
input - image, output - class
어떤 물체가 영상 속에 들어있는지 분류하는 mapping한다.
k Nearest Neighbors (k-NN)
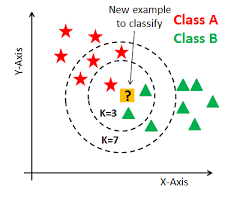
특정 데이터셋에 질의(query) 데이터가 들어오면 k개의 이웃 데이터가 가지고 있는 클래스 정보를 이용하여 질의 데이터를 분류한다!
이 세상의 모든 data를 가지고 있다고 가정하면 영상 분류 문제 -> 검색 문제로 바뀌게 됨!
하지만
data의 수가 많아질 수록 검색하는 데 걸리는 시간, 메모리의 용량이 기하급수적으로 커지게 되는 단점이 있기 때문에 방대한 데이터를 Neural Network로 압축한다.
Convolution Neural Network (CNN)
모든 pixel을 서로 다른 가중치로 내적하여 non-linear Activation Function을 수행하여 분류 score을 출력하는 간단한 모델, Fully Connected Neural Network가 존재한다.
하지만, 존재할 수 있는 문제로는
1. 레이어가 1층으로 단순해서, 평균적인 이미지가 아닌 경우에 판별하기 어려움
2. 하나의 모델만 학습한 경우 조금이라도 위치나 scale이 다른 영상이 input으로 들어갔을 때 다른 output을 도출할 수 있음
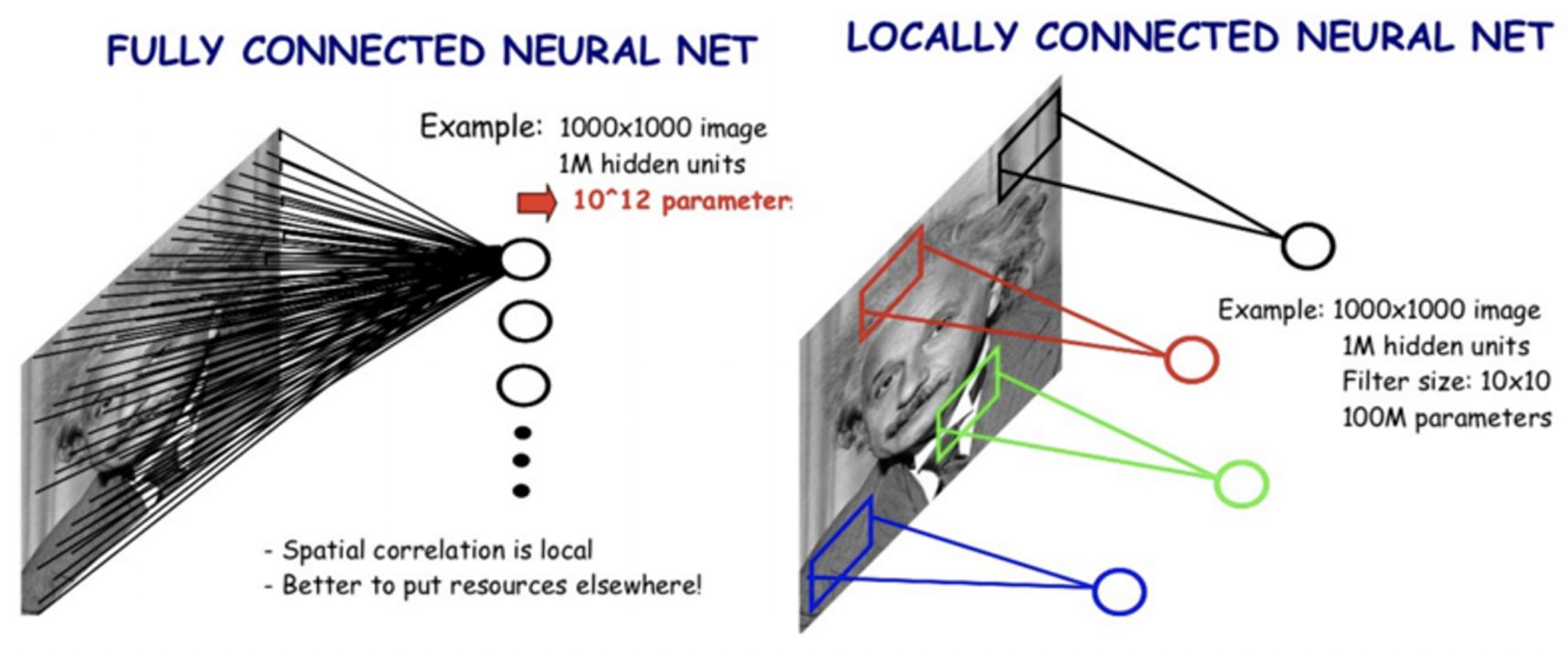
위의 문제를 해결하기 위해 Locally Connected Neural Network 모델이 개발되었다.
1개의 특징을 뽑기 위해 모든 pixel을 고려하는 FC layer와 다르게 LC layer의 경우 1개의 특징을 위해 영상의 공간을 고려하여 국부적인 영역에서 수행한다.
"
이렇게 되면 parameter를 재활용할 수 있기 때문에, 적은 parameter로 효과적인 특징 추출이 가능하고, overfitting 역시 방지할 수 있음!!
"
AlexNet
LeNet-5
Conv-Pool-Conv-Pool-FC-FC
주로 한 글자 단위를 인식하고, 1998년 당시 우편번호 인식에 큰 기여를 한 모델
AlexNet은 LeNet-5에 기반하여 개발되었다.
1. layer가 7개로 늘어나고, 사용된 parameter 역시 6천만개로 증가하였음
2. ImageNet을 통하여 학습 데이터의 수 역시 크게 증가함
3. non-linear Function에 ReLU가 사용되어 강력한 알고리즘
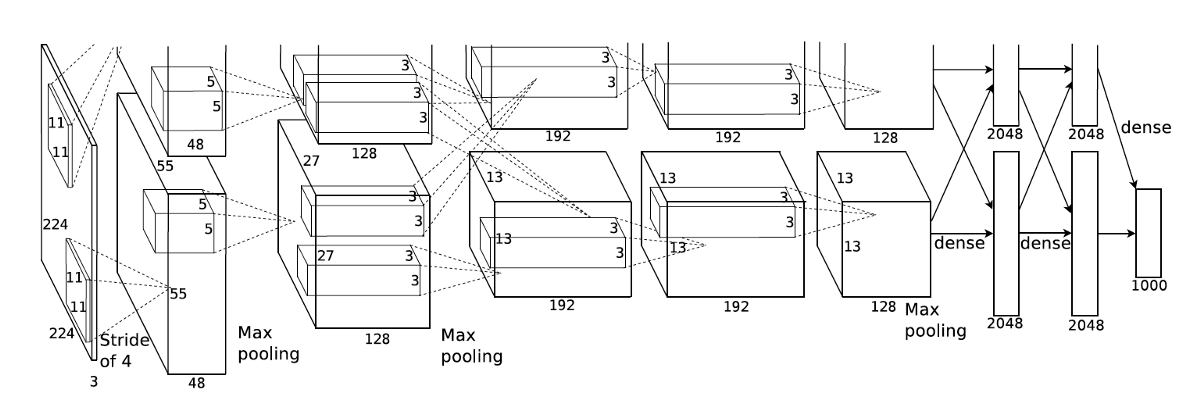
당시에는 gpu 메모리가 모자라서 네트워크를 절반씩 나누어 2개의 gpu를 사용하였다. 네트워크 모든 영역에서 cross communication이 일어나면 속도가 느려지기 때문에 일부 구간에서만 교차가 일어난다.
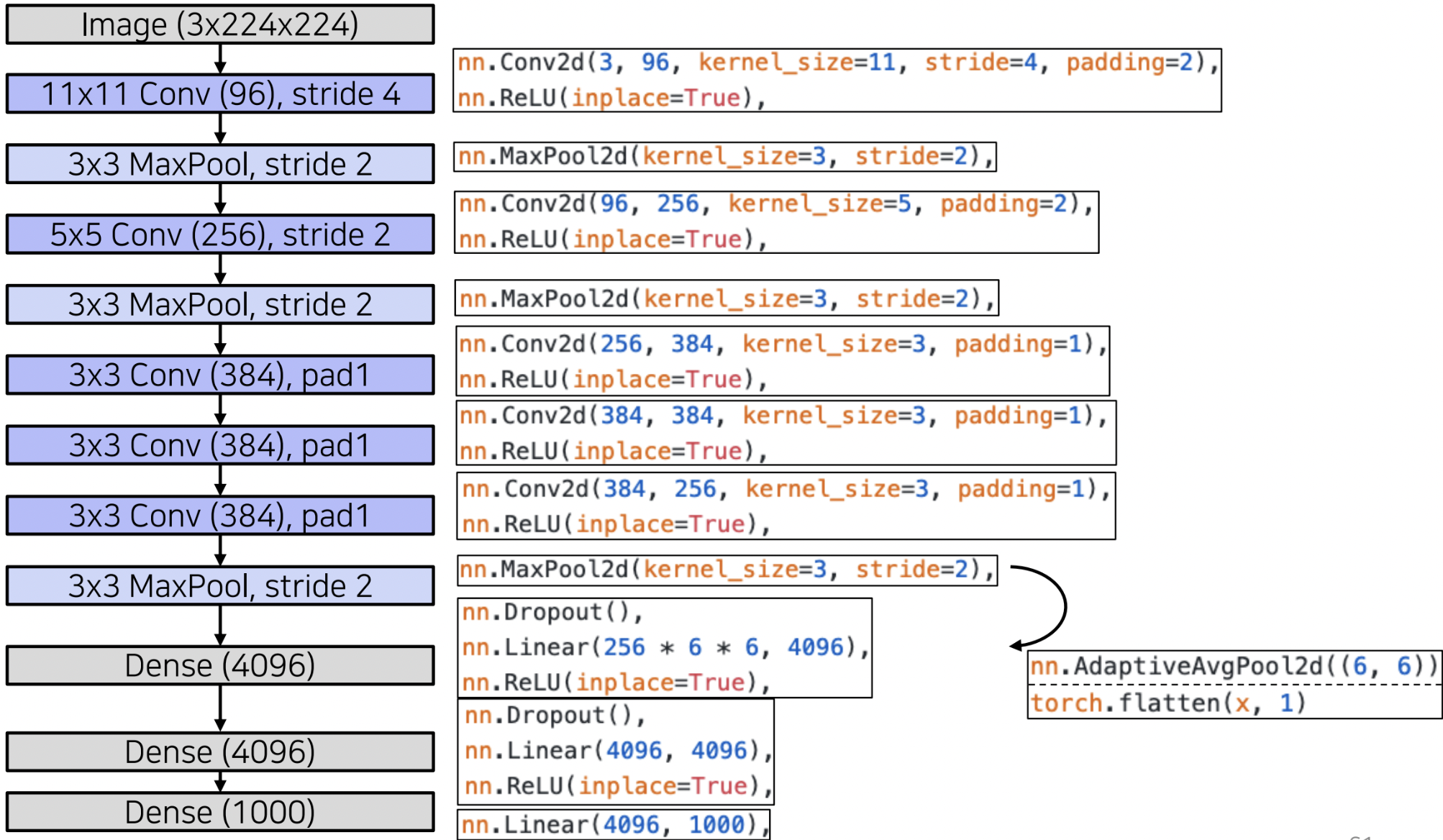
Maxpooling이 끝난 output은 tensor 형태로 공간정보 뿐만 아니라 채널 정보 역시 포함하고 있는데 이를 linear 형태로 바꿔주어야 한다. Average Pooling 혹은 Flattening 두 가지 방법이 존재한다.
출처 : 부스트코스
