
이번 취밋 프로젝트를 작업하면서 스케줄 기반으로 처리해야 하는 작업들이 점점 많아지면서 Quartz를 도입하게 되었다. 하지만 Quartz를 설명하기 전에, 먼저 배치 처리의 기본 개념과 Spring Batch가 제공하는 구조를 정리하는 것이 흐름상 더 자연스럽다고 판단했다. 이후에 Quartz를 활용해 어떻게 스케줄링을 구성했는지 이어서 설명할 예정이다.
Batch란?

배치(Batch) 처리란, 일정 시간 동안 데이터를 모아두었다가 한 번에 일괄 처리하는 방식이다.
일상생활에서는 택배가 물류센터에 일정량 모이면 지역별로 한 번에 분류 후 배송하는 과정, 은행의 매일·매월·매시간 이자 지급, 신용카드 결제 승인 후 야간에 일괄 정산하는 과정 등 여러 곳에서 배치 처리가 이루어진다.
웹 서비스에서도 마찬가지로, 알림 일괄 발송, 벡터 DB 임베딩, 로그 정리, 통계 집계처럼 사용자 요청과 분리되어 비동기 또는 배치 방식으로 처리해야 하는 작업들이 매우 많다.
이러한 작업들을 수행하기 위해 Quartz, Spring Batch, Scheduled Task 같은 기능을 활용해 배치 시스템을 사용해서 스케줄러 관리를 한다.
스케줄러란?
스케줄러는 특정 작업(Job)을 정해진 시간, 주기, 혹은 조건에 따라 자동으로 실행하도록 관리해주는 도구이다.
1) 정적(Job) 스케줄링
- 애플리케이션 실행 시점에 미리 설정된 시간/주기로 Job이 고정된다.
- 예: 매일 0시에 로그 정리, 매시간 임베딩 처리, 매주 월요일 통계 집계
- 코드 또는 설정 파일에서 주기를 고정해두는 방식 (@Scheduled 등)
2) 동적(Job) 스케줄링
- 실행 중에 새로운 Job을 추가하거나 기존 Job의 실행 시간을 변경할 수 있다.
- 예: 사용자 요청에 따라 특정 시간에 알림 예약, 관리자가 대시보드에서 스케줄 변경
- Quartz 같은 스케줄러가 대표적이며, Job/Trigger를 런타임에 유연하게 생성·관리할 수 있다.
Sptring Batch 내부 구조도
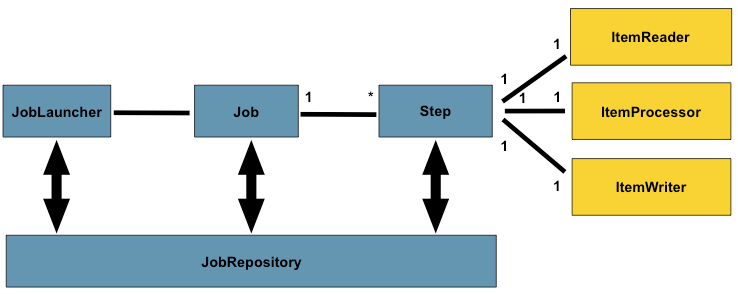
JobLauncher는 배치 작업(Job)을 실행시키는 역할을 한다.
Job은 하나 이상의 Step으로 구성된 배치 작업의 전체 단위를 의미한다.
Step은 Job 안에 포함된 세부 실행 단계이며, 이 안에서 읽기(Reader) → 처리(Processor) → 쓰기(Writer) 작업이 수행된다.
JobRepository는 Job과 Step의 실행 이력, 시작·종료 시간, 성공/실패 상태 등을 메타데이터 테이블에 저장하고 관리한다.
Spring Batch를 사용하려면, 실제 서비스에서 사용하는 비즈니스 DB와는 별도로 배치 작업의 실행 이력(Job/Step의 시작·종료 시간, 성공/실패 여부, 재시작 정보 등)을 관리하기 위한 전용 메타 데이터베이스가 필요하다.
MySQL 기준으로 아래 설정을 application.properties 또는 application.yml에 추가하면 애플리케이션 실행 시 Spring Batch가 메타 테이블들을 자동 생성한다. (보통 config에 @primary 어노테이션을 사용해 메타 데이터베이스로 지정)
spring.batch.jdbc.initialize-schema=always
spring.batch.jdbc.schema=classpath:org/springframework/batch/core/schema-mysql.sql자동 생성 테이블
BATCH_JOB_INSTANCE
BATCH_JOB_EXECUTION
BATCH_JOB_EXECUTION_PARAMS
BATCH_STEP_EXECUTION
BATCH_STEP_EXECUTION_CONTEXT
BATCH_JOB_EXECUTION_CONTEXT
이 테이블들은 배치 Job과 Step 실행의 전체 이력을 저장하며, 배치 작업 성공·실패 상태 관리, 실행 시간 추적, 재실행 지점 관리 등 Spring Batch의 핵심 기능을 담당한다.
배치 처리
- 테이블 <-> 테이블 간 데이터 이동(JPA 사용)

이동 할 테이블 엔티티
@Entity
@Getter
@Setter
public class BeforeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
}이동 한 데이터를 받을 엔티티
@Entity
@Getter
@Setter
public class AfterEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
}
그리고 before 테이블 안에 더미데이터를 추가해 진행했습니다.
@Bean
public Job firstJob() {
System.out.println("first job");
return new JobBuilder("firstJob", jobRepository)
.start(스텝들어갈자리)
.build();
}이제 Job을 하나 만들어주고 jobRepository를 builder에 같이 넣어서 자동으로 spring batch가 메타 데이터베이스에 시간이나 상태를 저장할 수 있게 해준다.
앞에서 말했듯이 Job에서 일기-처리-쓰기가 진행되는게 아니고 step에서 처리하게 되는데 이때 읽기 → 처리 → 쓰기 작업은 청크 단위로 진행되는데, 대량의 데이터를 얼만큼 끊어서 처리할지에 대한 값으로 적당한 값을 선정해야 한다.
(너무 작으면 I/O 처리가 많아지고 오버헤드 발생, 너무 크면 적재 및 자원 사용에 대한 비용과 실패시 부담이 커짐)
job start 메서드 내부에 넣어주면 된다.
@Bean
public Step firstStep() {
System.out.println("first step");
return new StepBuilder("firstStep", jobRepository)
.<BeforeEntity, AfterEntity> chunk(10, platformTransactionManager)
.reader(읽는메소드자리)
.processor(처리메소드자리)
.writer(쓰기메소드자리)
.build();
}Spring Batch – Read → Process → Write 구성
Read 단계에서는 RepositoryItemReader를 사용하여 JPA Repository 기반으로 데이터를 읽어온다. findAll을 사용하지만 Chunk 단위로 페이징되므로 pageSize와 정렬 조건을 지정해 불필요한 자원 낭비를 방지한다.
@Bean
public RepositoryItemReader<BeforeEntity> beforeReader() {
return new RepositoryItemReaderBuilder<BeforeEntity>()
.name("beforeReader")
.pageSize(10)
.methodName("findAll")
.repository(beforeRepository)
.sorts(Map.of("id", Sort.Direction.ASC))
.build();
}Process 단계는 읽어온 데이터를 가공하는 역할을 한다. 단순 매핑처럼 복잡한 로직이 없다면 생략도 가능하며, 아래처럼 간단하게 BeforeEntity를 AfterEntity로 변환할 수 있다.
@Bean
public ItemProcessor<BeforeEntity, AfterEntity> middleProcessor() {
return item -> {
AfterEntity afterEntity = new AfterEntity();
afterEntity.setUsername(item.getUsername());
return afterEntity;
};
}Write 단계에서는 RepositoryItemWriter를 사용하여 처리된 AfterEntity를 JPA Repository를 통해 실제 DB에 저장한다.
@Bean
public RepositoryItemWriter<AfterEntity> afterWriter() {
return new RepositoryItemWriterBuilder<AfterEntity>()
.repository(afterRepository)
.methodName("save")
.build();
}이처럼 Reader에서 데이터를 읽고, Processor에서 가공하며, Writer에서 저장하는 구조를 통해 Spring Batch의 Chunk 기반 처리 흐름을 구현할 수 있다.
Spring Batch에서는 JobLauncher를 사용하여 배치 작업(Job)을 실행할 수 있다. 일반적으로 배치는 스케줄러나 이벤트 기반으로 비동기 실행되지만, 컨트롤러에서 직접 Job을 호출하면 HTTP 요청 동안 동기적으로 배치를 실행할 수도 있다. 즉, 클라이언트가 API를 호출하면 Job이 즉시 실행되고, Job이 끝날 때까지 요청이 대기하게 된다.
아래 예시는 GET 요청으로 Job을 실행하는 방식이다. 요청 시 전달받은 value를 JobParameters로 넘기고, jobRegistry를 통해 실행할 Job을 얻은 뒤 jobLauncher.run()을 호출한다.
@GetMapping("/first")
public String firstApi(@RequestParam("value") String value) throws Exception {
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", value)
.toJobParameters();
jobLauncher.run(jobRegistry.getJob("firstJob"), jobParameters);
return "first job completed";
}이 방식은 테스트용, 즉시성 작업, 관리자 페이지에서 수동 실행이 필요한 경우 유용하지만, 요청이 Job 완료까지 블로킹되므로 긴 시간이 걸리는 배치에는 적합하지 않다. 운영 환경에서는 일반적으로 Quartz, @Scheduled, 또는 외부 배치 스케줄러를 사용해 비동기적으로 Job을 실행하는 구조를 선택한다.
스케줄러 설정
Spring Batch는 보통 스케줄러와 함께 사용하여 특정 시간마다 자동으로 Job을 실행하는 구조를 많이 사용한다. 이를 위해 먼저 애플리케이션 전체에서 스케줄러 기능을 활성화해야 하며, 이후 특정 Job을 주기적으로 실행하는 스케줄러 클래스를 작성하면 된다.
1. 스케줄러 활성화 설정
스프링 애플리케이션에서 스케줄러를 사용하기 위해서는 @EnableScheduling 어노테이션을 추가해야 한다.
@SpringBootApplication
@EnableScheduling
public class SpringBatchApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBatchApplication.class, args);
}
}이 설정을 통해 스프링이 스케줄러 관련 Bean들을 활성화하고, @Scheduled가 붙은 메서드를 주기적으로 실행할 수 있게 된다.
2. 스케줄러 Config 클래스 작성
아래 설정은 JobLauncher와 JobRegistry를 주입받아, Cron 표현식에 따라 배치 Job을 자동으로 실행하는 스케줄러 구성이다.
@Configuration
public class FirstSchedule {
private final JobLauncher jobLauncher;
private final JobRegistry jobRegistry;
public FirstSchedule(JobLauncher jobLauncher, JobRegistry jobRegistry) {
this.jobLauncher = jobLauncher;
this.jobRegistry = jobRegistry;
}
@Scheduled(cron = "10 * * * * *", zone = "Asia/Seoul")
public void runFirstJob() throws Exception {
System.out.println("first schedule start");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd-hh-mm-ss");
String date = dateFormat.format(new Date());
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", date)
.toJobParameters();
jobLauncher.run(jobRegistry.getJob("firstJob"), jobParameters);
}}
3. 동작 방식 설명
-
@Scheduled(cron = "10 * * * * *")
→ 매 분 10초마다 firstJob을 자동 실행한다. -
Job 실행 시마다 고유한 JobParameters(date)를 넣어주어
→ 동일 Job이 중복 실행되었다고 간주되지 않도록 관리한다. -
jobLauncher.run()
→ Spring Batch Job을 실제로 실행하는 메서드이다. -
jobRegistry.getJob("firstJob")
→ 등록된 Batch Job을 이름으로 찾아 실행한다.
Quartz Cron 표현식은 6자리 또는 7자리로 구성된다.
초 분 시 일 월 요일 (옵션: 연도)
예) "10 * * * * *"
→ 매 분마다 10초에 실행
아래는 자리별 의미이다:
| 자리 | 의미 | 예시 |
|---|---|---|
| 초(0–59) | 언제 실행할지 | 10 = 10초 |
| 분(0–59) | 몇 분에 실행할지 | * = 매 분 |
| 시(0–23) | 몇 시에 실행할지 | * = 매 시 |
| 일(1–31) | 며칠에 실행할지 | * = 매일 |
| 월(1–12) | 몇 월에 실행할지 | * = 매월 |
| 요일(0–6) | 무슨 요일에 실행할지 | * = 매일 |
| 연도(옵션) | 보통 생략 | 생략 가능 |
Quartz Cron 예시 모음
"0 0 0 * * *"→ 매일 0시 0분 0초"0 0/10 * * * *"→ 10분마다 한 번"0 0 3 * * MON"→ 매주 월요일 새벽 3시"30 * * * * *"→ 매 분 30초"0 0 4 1 * *"→ 매월 1일 새벽 4시
ref.
