- 학습 동기 :
실시간 처리를 위해 filebeat와 kafka를 연동하여 spark에 넘기는 작업을 수행하려고 한다.- 학습 목적 :
카프카를 설치하고 구동하기에 앞서, 카프카의 개념을 이해하고 정리하는것이 목적이다.
https://github.com/AndersonChoi/tacademy-kafka 이 분의 깃허브 내용과 강의자료 내용을 기반으로 글을 정리했다.
1. 카프카 기본 개념
1-1) Before
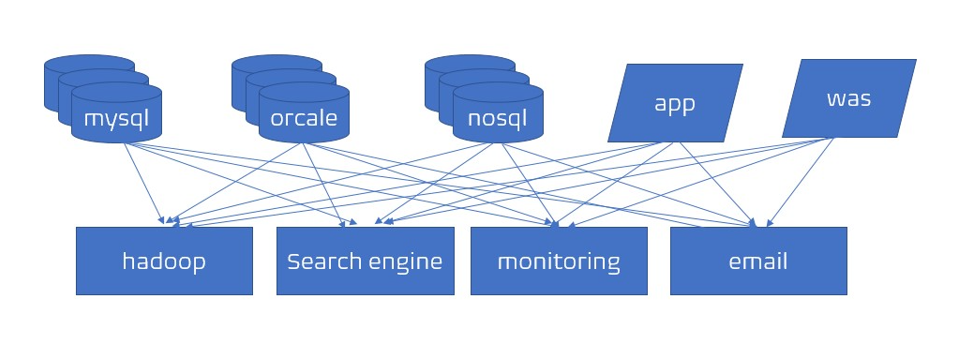
- 이전에는 소스 애플리케이션과 타겟 애플리케이션이 단방향으로 소통을 했다.
소스 애플리케이션과 타겟 애플리케이션이 많아지면서 위 그림과 같이 데이터 전송 라인이 매우 복잡해졌다. - 소스 애플리케이션 개수와 타겟 애플리케이션의 개수가 많아질수록 데이터 전송 라인이 많아졌고, 이로 인해
- 배포와 장애에 대응이 어려워짐
- 데이터 전송시 프로토콜 포맷의 파편화가 심해짐
- 데이터 포맷 내부 변경사항이 발생할 때 유지보수가 어려워짐
1-2) After
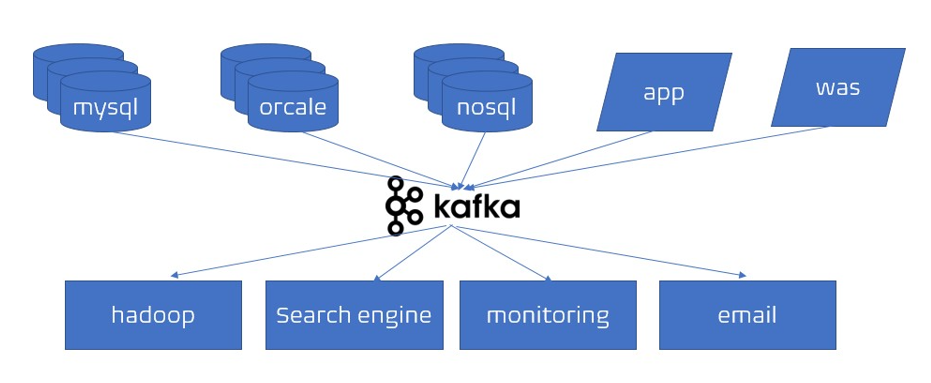
- 이전의 복잡한 문제들을 해결하기 위해 링크드인에서 자체적으로 '아파치 카프카'를 개발했다.
- 카프카는 소스 애플리케이션, 타겟 애플리케이션의 커플링을 약하게 하기 위해 나왔다. 카프카는 복잡한 전송라인을 단순하게 처리하기 위해
- 프로듀서와 컨슈머 분리
- 메시지 데이터를 여러 컨슈머에게 허용
- 높은 처리량 위한 메시지 최적화
- 데이터 증가에 따라 스케일 아웃을 가능하게 함
1-3) Kafka 강점
- 카프카는 유연한 큐 역할을 한다
- 고가용성
서버가 이슈가 생기거나 전원이 내려가는 상황에도 데이터를 손실없이 복구할 수 있다. - 낮은 지연, 높은 처리량
효과적으로 많은 데이터를 처리할 수 있다.
따라서 빅데이터 처리에서 카프카는 필수이다!
2. 카프카 기본 구조
2-1) 데이터 전송 방식
Source Application은 아파치 카프카에 데이터를 전송하고 타겟 애플리케이션은 카프카에서 데이터를 가져온다.

[Source Application] -> 데이터 -> [Kafka] -> 데이터-> [Target Application]
ex. 쇼핑몰 클릭 로그 로그 적재/처리 등
ex. 은행의 결제 로그
...
데이터 포맷의 제한이 거의 없음
(json, tsv, avro 등) 2-2) 토픽(Topic)이란?
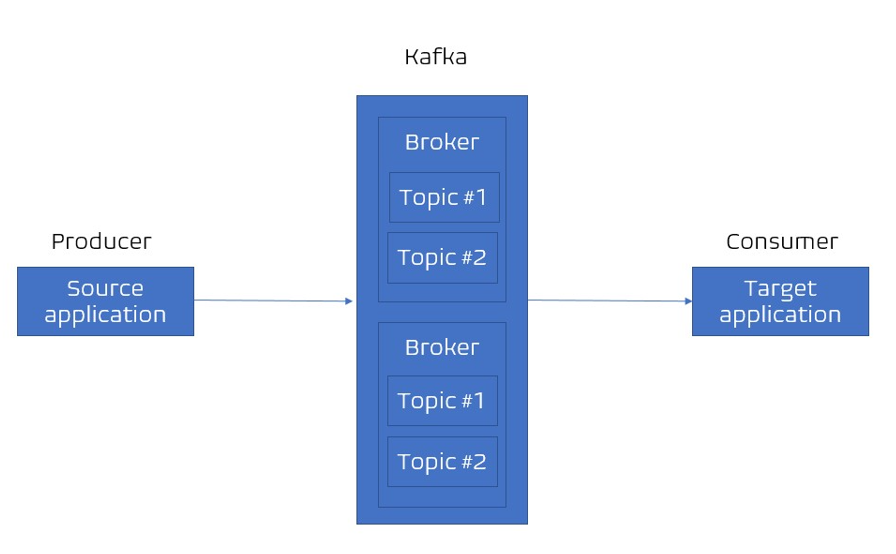
카프카는 AMQP 와는 다르게 동작한다. 이 글 참고
- 카프카에는 다양한 데이터가 들어갈 수 있는데 ( 클릭 로그, send sms, location log 등.. ), 이러한 데이터가 들어갈 수 있는 공간을 '토픽' 이라한다.
- 카프카에서는 토픽을 여러개 생성할 수 있으며, 토픽은 DB의 테이블, 파일 시스템의 폴더와 유사한 성질을 갖고있다.
- 토픽은 목적에 따라 이름을 가질 수 있다. 클릭 로그, send sms, Location log 등과 같이 데이터의 유형을 명확하게 명시하면 유지보수시에 편리하게 관리할 수 있다.
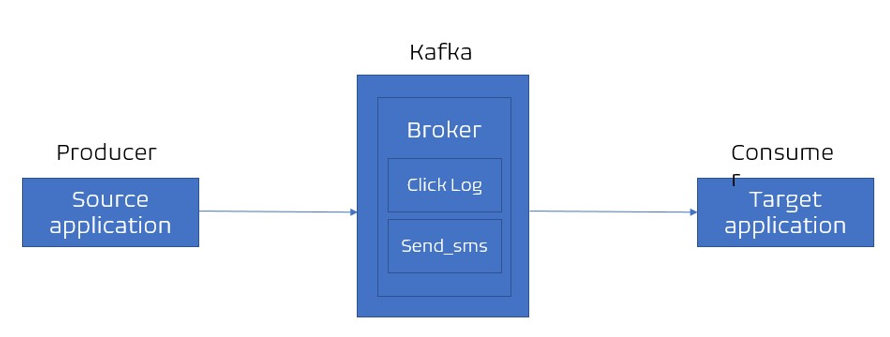
2-3) 파티션이란?
- 파티션이란 토픽을 구성하는 저장소이며 각 메시지가 저장되는 위치이다. 하나의 토픽은 여러개의 파티션으로 구성될 수 있다.
- 프로듀서와 컨슈머는 토픽을 기준으로 메시지를 주고받는다.
01. 파티션이 한 개인 경우

-
첫번째 파티션의 번호는 0번부터 시작한다. 하나의 파티션은 큐와 같이
선입선출방식으로 데이터가 파티션 끝에서부터 쌓이게 된다.
즉 카프카 컨슈머는 토픽의 첫번째 파티션에서 데이터를 가장 오래된 순서대로 가져가게 된다. -
더 이상 데이터가 들어오지 않으면 컨슈머는 또 다른 데이터가 들어올때까지 기다린다.
컨슈머가 토픽 내부의 파티션에서 데이터를 가져가더라도 데이터는 삭제되지 않는다.파티션에 컨슈머가 가져간 데이터는 왜 삭제하지 않고 남겨두는 것일까?
새로운 컨슈머가 붙었을 때 다시 0번부터 가져가서 사용할 수 있도록 하기 위함이다.
(컨슈머 그룹이 달라야하며, auto.offset.reset=earliest으로 지정해준다.)
이 과정으로 동일한 데이터에 대해 두 번 처리를 할 수 있다. => 카프카에서 아주 중요한 개념이다.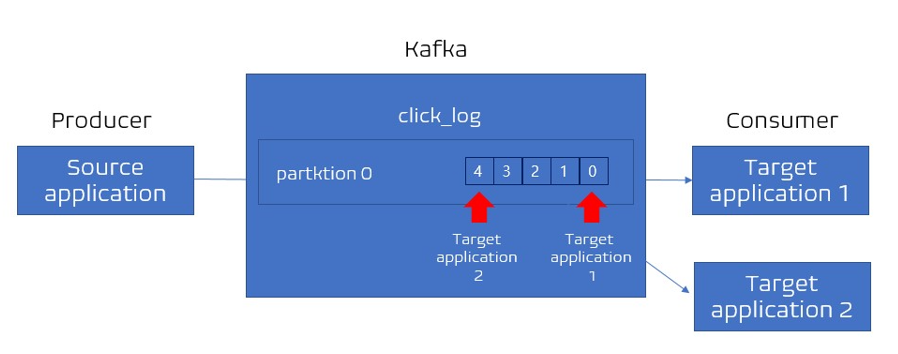
02. 파티션이 두 개 이상인 경우
파티션이 하나 더 늘어난 상태에서 메시지는 과연 어느 파티션에 들어가야할까?
- 프로듀서는 데이터를 보낼 때 Key 또는 라운드로빈 방식으로 파티션을 지정할 수 있다.
같은 Key를 갖는 파티션은 동일한 파티션에 저장이 되고, 키를 지정하지 않고(키가 null) 기본 파티셔너를 사용한다면 라운드로빈 (순서대로 시간단위로 메시지 할당)으로 할당이 된다.
03. 더 많은 파티션
-
파티션을 여러개로 늘리면 그 수 만큼 컨슈머의 개수를 늘려서 데이터 처리를 분산시킬 수 있다.
-
그러나 파티션을 늘리는 것은 늘 조심해야한다. 파티션을 늘리는것은 가능하지만, 다시 줄일수는 없다! (파티션을 줄이기 위해서는 토픽 자체를 제거해야함.) 파티션을 너무 많이 늘리면 파일 핸들러의 리소스 낭비가 있을 수 있으며, 늘어난 파티션 수 만큼 리플리케이션 수행이 느려져서 장애복구에 많은 시간이 소요될 수 있다.
-
데이터가 늘어나면 파티션의 데이터는 언제 삭제될까?
- 삭제되는 타이밍은 옵션에 따라 다르다.
- 레코드가 저장되는 최대 시간과 크기를 지정할 수 있다.
log.retention.ms를 통해 일정 기간(최대 record 보존 시간) ,log.retention.byte를 통해 일정 용량 데이터(최대 record 보존 크기(byte))를 저장하게 할 수 있고, 적절하게 데이터 삭제될 수 있도록 설정할 수 있다.
2-4) 프로듀서
데이터를 생산해서 카프카 브로커(카프카 애플리케이션이 설치된 서버/노드)의 토픽으로 보내는 역할을 한다.
Producer 역할
1) 토픽에 전송할 메시지를 생성할 수 있음
2) 특정 토픽으로 데이터를 publish 전송할 수 있음 => 카프카 전송 완성
3) 카프카 브로커로 데이터를 전송할 때 전송 성공 여부를 알 수 있고, 실패할경우 재시도 할 수 있음
+엄청난 양의 데이터를 대량/실시간으로 카프카에 적재할 때 프로듀서를 사용할 수 있다!
프로듀서 예제 코드 (출처)
public class SimpleProducer {
private static String TOPIC_NAME = "test";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
// 자바 프로퍼티 객체를 통해 프로듀서 설정 정의
// 부트스트랩 서버 설정 : localhost:9092(카프카)를 바라보도록 지정
// 카프카 브로커의 주소 : 2개 이상의 ip, port 설정을 권장
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// Key, Value String Serializer로 직렬화
// Key는 Message 보내면 토픽의 파티션 지정될 때 사용됨
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 설정한 properties로 Kafka Producer Instance 생성
KafkaProducer<String, String> producer = new KafkaProducer<>(configs);
// 10개의 데이터 전송
for (int index = 0; index < 10; index++) {
String data = "This is record " + index;
// 전송 객체 생성
// Kafka client에서 producer record 클래스를 제공
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, data);
try {
// producer record 전송
// 어느 토픽에 넣을 것인지, key와 value를 담을 것인지 선언할 수 있음
// Producer.send(new ProducerRecord<String, String>("click_log", "1", "data"));
producer.send(record);
System.out.println("Send to " + TOPIC_NAME + " | data : " + data);
Thread.sleep(1000);
} catch (Exception e) {
System.out.println(e);
}
}
}
}카프카로 데이터 보낼 수 있음 
2-5) Consumer
브로커 토픽 내부의 저장된 으로부터 데이터를 가져온다.
- 다른 메시징 시스템 => Consumer가 데이터를 가져가면 큐 내부 데이터가 사라짐
- 카프카에서는 Consumer가 데이터 가져가도 데이터가 사라지지 않음
- 카프카, 카프카 Consumer를 데이터 파이프라인으로 운영하는데 매우 핵심적인 역할을 함
Consumer 역할
- Topic 내부의 파티션에서 메시지 가져오기(Polling)
- 특정 데이터베이스에 저장하거나, 또 다른 파이프라인에 전달할 수 있음
- 카프카 Consumer는 기본적으로 토픽의 데이터를 가져온다.
- 프로듀서가 생성한 데이터는 토픽 내부의 파티션에 저장된다.
- Consumer는 파티션에 저장된 데이터를 가져온다.
- 데이터를 가져오는 것을 폴링(polling)이라고 한다.
- 파티션 Offset 위치 기록 (commit)
- offset 이란?
- 파티션에 들어간 데이터는 파티션 내에서 고유한 번호(offset)를 갖게 된다.
- 즉, offset은 파티션에 있는 데이터의 번호이다.
- offset 특징
- offset은 토픽별, 파티션별로 별개로 지정된다.
- offset은 consumer가 데이터를 어느 지점까지 읽었는지 확인하는 용도로 사용된다.
- consumer가 데이터를 가져갈 때 마다 offset을 commit 한다.
- offset의 정보는 consumer_offset 토픽에 저장 되며, 추후에 consumer가 불의의 사고로 실행이 중지되고 추후 재 실행할 때 데이터 처리의 복구 시점을 알려줄 수 있다.
- 즉, offset의 정보를 저장함으로써, consumer에 issue가 발생해도 데이터의 처리시점을 복구할 수 있는 고가용성의 특징을 갖게 된다.
3) Consumer 그룹을 통해 병렬 처리
- 파티션 개수에 따라 Consumer를 여러개 만들면 병렬 처리가 가능하기 때문에 더 빠른 속도로 데이터를 처리할 수 있다.
그렇다면 Consumer는 몇 개 까지 생성 가능할까??
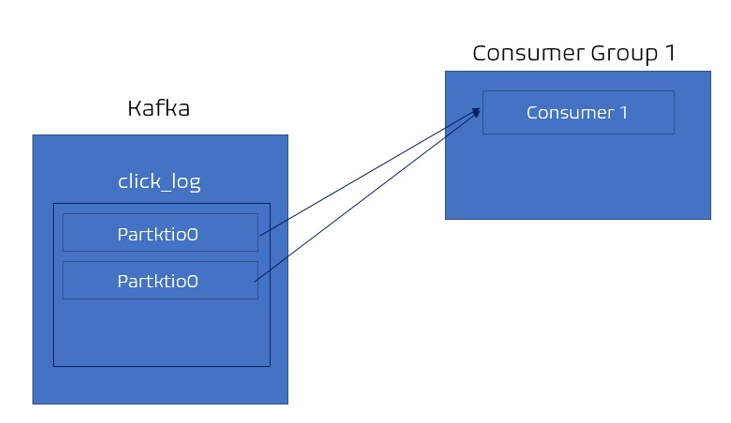
- consumer가 1개, 파티션이 2개인 경우 = 2개의 파티션에서 데이터를 가져간다
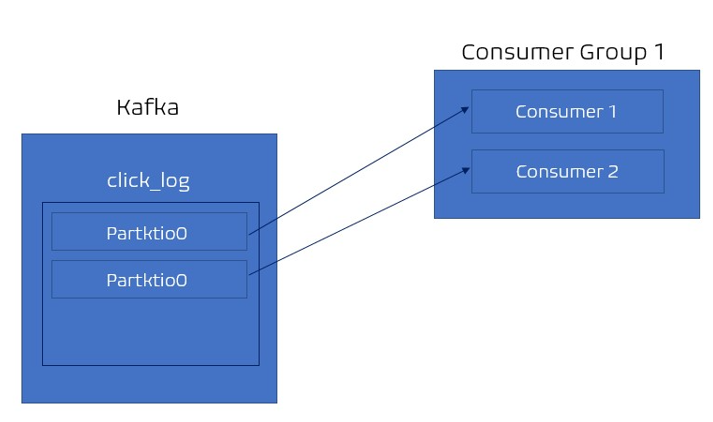
- 2개의 consumer, 파티션 2개인 경우 = 각 컨슈머가 각각의 파티션을 할당해 데이터를 가져가 처리한다.
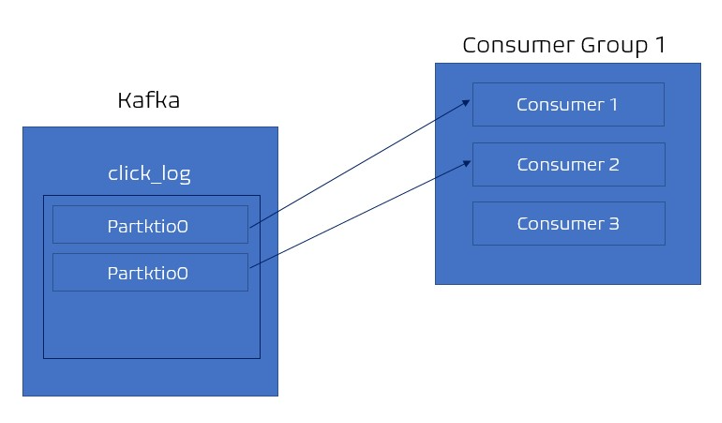
- 3개의 consumer, 파티션 2개인 경우 = 각 컨슈머에게 할당되었기 때문에 할당될 파티션이 없어 동작하지 않는다.
따라서 여러 파티션을 가진 토픽에 대해서 컨슈머를 병렬처리하고싶다면 consumer를 파티션개수보다 적은 개수로 실행시켜야한다
Consumer그룹이 다른 Consumer들은 어떻게 동작할까?
- 각기 다른 컨슈머 그룹에 속한 컨슈머들은 다른 컨슈머 그룹에 영향을 주지 않는다.
- 데이터 실시간 시각화 분석을 위해 es에 데이터를 저장하는 역할을 하는 컨슈머 그룹과 데이터 백업 용도로 하둡에 데이터 저장하는 컨슈머 그룹이 존재한다 가정
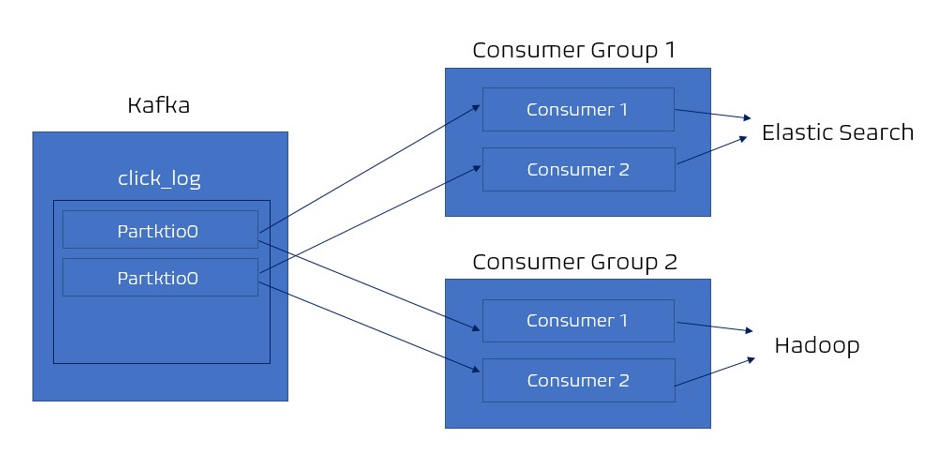
- es에 저장하는 컨슈머 그룹이 각 파티션에 특정 offset을 읽고 있어도
하둡에 저장하는 역할을 하는 컨슈머 그룹이 데이터 읽는데 영향 미치지 않는다.
_consumer offset 토픽에는 컨슈머 그룹별 토픽별로 offset을 나누어 저장
하나의 토픽으로 들어온 데이터는 다양한 역할을 하는 컨슈머들이 각자 원하는 데이터로 처리가 될 수 있다.
Consumer 예제 코드 (출처)
public class SimpleConsumer {
private static String TOPIC_NAME = "test";
// 그룹id 지정
// 그룹id == consumer 그룹 == consumer들의 묶음
private static String GROUP_ID = "testgroup";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
// producer와 동일
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// Kafka consumer class => consumer Instance 생성
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
// consumer의 subscribe method => 어떤 토픽 데이터를 가져올지 선언
consumer.subscribe(Arrays.asList(TOPIC_NAME));
/*
- 일부 파티션만 가져오고 싶다면 assign() 사용
TopicPartition partition0 = new TopicPartition(topicName,0);
TopicPartition partition1 = new TopicPartition(topicName,1);
consumer.assign(Arrays.asList(partition0,partition1);
*/
while (true) {
// 데이터를 실질적으로 가져오는 polling Loop
// poll method에서 설정한 시간동안 데이터 wait
// records 변수는 데이터 배치 : 레코드의 묶음 list임
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
// records 변수를 for루프에서 반복 처리 => 처리하는 데이터를 가져오게 함
for (ConsumerRecord<String, String> record : records) {
// 여기서는 단순 print
// 데이터를 하둡, 엘라스틱서치에 저장하는 로직을 넣을 수 있음
System.out.println(record.value());
}
}
}
}References
