나자바바 님의 하둡의 종류와 구성요소 강의를 보고 정리한 내용입니다.
YARN이란?
HADOOP 2.0에 추가된 개념이다.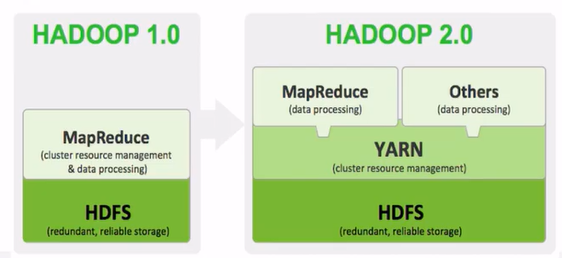
01. HADOOP 1.0 vs HADOOP 2.0
HADOOOP 1.0
- MapReduce에서 클러스터 리소스 관리함
- 여러개의 데이터 노드 - 여기에 데이터 블록들이 저장 -> 복제가 돼서 저장됨
- JOB을 실행시켰을 떄 블록을 읽어서 처리해야하는데
- N1, N2, N3, N4, N5
-> N1에서 해야할지 N3에서 해야할지 어떻게 판단하지?
= 리소스를 적게 실행하는 서버의 JOB을 실행시키는게 답 !
클러스터 리소스 관리
어떤 데이터 노드가 리소스 적게 차지하는지 상황을 알아야 함 => 이것을 클러스터 리소스 관리라고 말함노드수가 늘어날수록 맵리듀스가 데이터 처리하는 일 보다 리소스를 관리하는 일에 더 많은 자원을 소비
노드가 많을 경우 맵리듀스 성능이 떨어지게 됨

HADOOP 2.0
- YARN을 따로 분리
- MAPREDUCE가 YARN 기반으로 동작
- YARN 단순히 클러스터 리소스 관리만 따로 해줌
- MAPREDUCE가 데이터 처리에 리소스를 집중할 수 있음
- YARN을 이용해 리소스 + JOB 상태 관리
02. yarn 특징
그래서 YARN은 뭔가?
=> 클러스터 리소스를 관리하는 컴포넌트를 갖고 있는 패키지 매니저
- 특징
- job tracker의 두 가지 역할 분리
- resource 관리
- job 상태 관리
-> 기존 job tracker의 병목 제거
- 범용 클러스터 api
- MR 외에 다양한 애플리케이션 실행 O
- 애플리케이션마다 자원(CPU, 메모리)을 할당함.
- job tracker의 두 가지 역할 분리
03. hadoop 구조
3-1. hadoop 1.0 ver
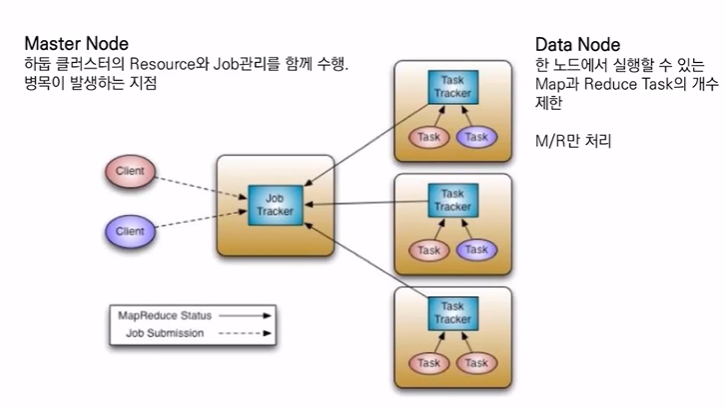
-
master node
하둡 클러스터의 resource와 job 관리를 함께 수행
병목이 발생하는 지점이 생김
(map reduce가 데이터 처리와 리소스 관리를 함께 했으므로) -
data node
클라이언트가 요청한 실제 작업들은 data node에서 처리됨
task가 실행됨 (task는 데몬으로 별도로 실행됨)
task tracker가 자신의 상태를 job tracker에게 알려줌
job tracker는 job을 실행시키는 master node에 존재
job tracker가 해야 할 일이 많아짐 => 병목현상 발생
3-2. hadoop 2.0 ver
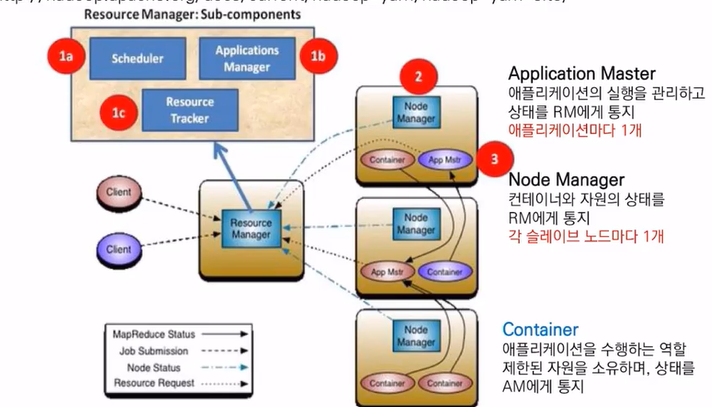
- 리소스 관리를 위한 컴포넌트 별도로 분리
- 리소스 매니저가 별도로 존재
- 리소스 매니저 컴포넌트 : 리소스 관리를 위한 컴포넌트들
- scheduler
- application manager
- resource tracker
-
클라이언트가 작업 => 데이터 노드에는 노드매니저 프로세스가 실행
-
노드매니저?
각 데이터 노드의 상태 를 리소스 매니저에게 알려줌 -
리소스 매니저?
- 데이터 노드의 상태를 보고 누가 리소스 많이/적게 차지하는지 알고있음 => 데이터 노드에게 job을 실행시키도록 함
- 데이터 노드에는 각 job마다 application master가 만들어짐
- application master는 데이터 노드 중 어느 한 곳에만 만들어 짐
- application master가 다른 데이터 노드의 데이터가 있는 블록에서 컨테이너가 실행 => 컨테이너가 제한된 자원을 소유해서 application 수행하는 역할
-
컨테이너
컨테이너는 자신의 map reduce가 얼마나 동작하고 있는지 상태를 application master에게 보내줌
3-3. 리소스 매니저의 역할이 중요!
리소스 매니저는 job을 받아서 그 전에 노드 매니저들로부터 받은 상태에 따라 어떤 노드매니저가 얼마나 많이/적게 사용하고있는지 알게 되는데,
application master가 요청한것에 따라서 이 블럭은 어디서 처리하는게 좋아 라고 알려주는 역할을 함 .
블럭이 있는 노드에서 컨테이너가 실행 => 컨테이너는 자신의 상태를 application master에게 다시 알려줌
리소스 매니저가 YARN 이라는 이름으로 만들어짐!
HADOOP 2.0대에 추가된 기능
04. MapReduce
정의
- MapReduce는 구글에서 분산 컴퓨팅을 지원하기 위한 목적으로 제작한 소프트웨어 프레임워크, HDFS에 저장된 파일을 이용함
구성
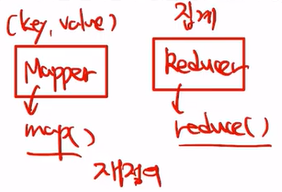
- 프레임워크는 map()과 reduce() 함수 기반으로 구성
- map() : (key, value) 쌍을 처리하여 또 다른 (key, value) 쌍을 생성하는 함수
- reduce() : 맵으로부터 생성된 (key, list(value))들을 병합(merge) => list(value)들을 생성하는 함수
목적
- 페타바이트 이상의 대용량 데이터를 신뢰할 수 없는 컴퓨터로 구성된 클러스터 환경에서 병렬 처리를 지원하기 위해서 개발
단점
- java 언어 습득
4-1. MapReduce 흐름
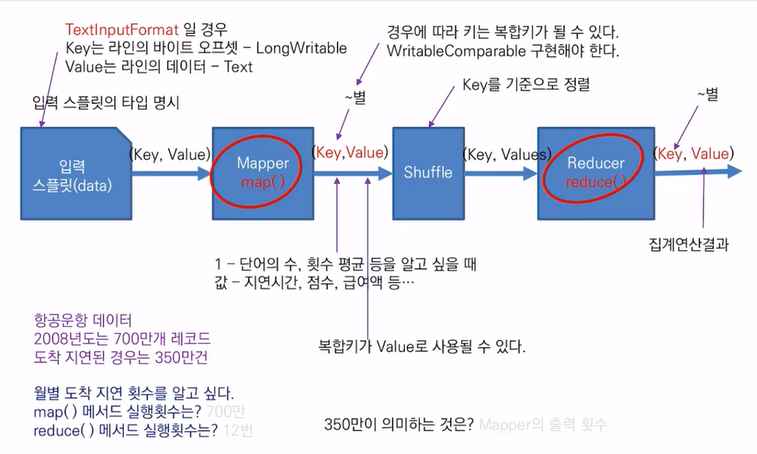
01. Mapper
- 데이터를 불러들임
데이터를 불러들일 때, 입력파일이 있는 PATH만 알려주면 MapReduce 프레임워크가 알아서 mapper에게 데이터 전달함
02. 입력 스플릿 => (key, value) => Mapper map()
단순 텍스트 파일이라면, (key value)를 mapper에게 전달
03. key : line의 byte offset (행번호x)
- why?
- 데이터들은 블록 단위로 쪼개져 있음 => 두번째 블록은 몇 번째 행인지 알려면 첫번째 블록의 행 수를 다 세어야함 => 병렬처리 해야해서 불가능
- line의 bite offset은 첫번째 블록의 크기 만큼 건너뛰면 됨 => 계산이 편리함
04. value : 라인의 데이터 (text)
- csv 파일의 형식으로 저장?
- , : 등 구분되어 저장됨
- 행 중에서 실제로 사용할 수 있는 열 들이 몇 개 안될것임
mapper의 역할은 한 행에서 분석에 사용될 열 들을 추출하는 역할
몇 번째 역할, 값은 무엇인지 알려줘야 함
sample
29개의 열
2008년도 데이터 => 700만개 레코드, 29열
월 별 비행기가 늦게 도착한 횟수를 알고싶다 350만건
mapper에서는 지연된 정보를 갖고있는 컬럼, 지연시간등의 정보만 추출하면 됨
월 정보, 도착 지연 시간 정보 두 가지만 알면 됨
두 가지를 내보내게 됨
횟수 or 평균 알고 싶으면 1을 반환하면 되는데
도착시간 알고싶으면 값을 반환하게 됨
도착 지연 횟수라면
key : 월 정보
value : 1
첫번째 행이 1월달 => 지연이 됐으면 1 안됐으면 0
mapper가 key ,value 정보 처리 =>
map reduce안에 있는 shuffle 서비스가 받게 됨
shuffle 서비스
- 섞어주는 역할
- key를 기준으로 정렬하는 것을 의미함
- key는 단일값이 되는데 value는 여러개가 만들어짐
- (key, [...])
- Suffle 서비스가 값을 묶어서 Reduce에 전달
Reduce
- key를 기준으로 값을 집계
- 도착 지연 횟수
- 월 정보, sum(1)
- 1월의 1값을 sum() => 1월달 도착 지연 횟수
700만개 레코드를 Mapper는 다 읽어야 함
650 MB => 하둡에 저장하면 6개 블록으로 저장됨 ==> 6개의 데이터노드가 동시에 처리를 하게 됨
전체적인 Map이라는 Method가 실행 되는것은 행의 수 만큼
실제 한개의 컴퓨터에서는 대략 120만개의 행만 처리
단일 시스템보다 병렬 시스템이 빠르게 됨
월 별 도착 지연 횟수
map() 에서의 실행 횟수 700만번 (-> 6대의 컴퓨터에서 나눠져서 실행)
reduce() 에서의 실행 횟수 12번(월 별 이니까)
도착 지연된 경우가 350만건 => 의미?
Mapper가 도착지연된 경우만 key value로 출력한다 =>
mapper(key, value) 를 출력하는 횟수 <요약>
-
MapReduce는 mapper, reduce로 구성
mapper는 입력 데이터에서 원하는 key 값을 출력한다
shuffle 서비스가 key 기바능로 정렬해서 reduce에게 전달해준다
reduce에서는 keyf를 기반으로해서 집계를 한다. -
map reduce로 머신러닝 하지 않는다
최소한의 집계정도 한다 -
spark-sql
select 구문 할 수 있음
hadoop의 데이터를 select로 조회할 수 있음
기존의 map-reduce를 쓰는 것 보다 다른 방법을 이용하는게 훨씬 더 생산성이 좋다
