하둡
1.[Hadoop] 개념 정리

검색엔진 Hadoop 탄생, 기술 PC -> Internet -> 검색[Indexing] -> Web -> [검색엔진] -> Mobile -> Cloud 하둡은 비정형 검색에서 시작했다. 더그 커팅 Lucene : 오픈소스 검색(Indexing) 라이브러리 검색
2.[hadoop] 하둡 종류와 구성요소
HADOOP 2.0에 추가된 개념이다.MapReduce에서 클러스터 리소스 관리함여러개의 데이터 노드 - 여기에 데이터 블록들이 저장 -> 복제가 돼서 저장됨 JOB을 실행시켰을 떄 블록을 읽어서 처리해야하는데N1, N2, N3, N4, N5 \-> N1에서 해야할지
3.[hadoop] 하둡 클러스터 구축을 위한 설정
4개의 리눅스를 가상화 (컴퓨터가 4개 필요)1개 namenode, 3개 datanode (primary)NameNode(master)fsimage, edits 저장 DataNode(slave1)blk, blk.meta 저장block을 저장하기 위한 설정들이 추가 Se
4.[Hadooop] HDFS 설치 1 - Windows

Java 버전 => jdk 1.8 + \- Hadoop v2 : jdk 1.7+ \- Hadoop v3 : jdk 1.8+ Hadoop 버전 \- Hadoop v2.7 \- Hadoop v3.2.2압축해제 -> bandizip, 7zip \- "\~~.tar
5.[Hadooop] HDFS 설치 2 - VirtualBox & Centos
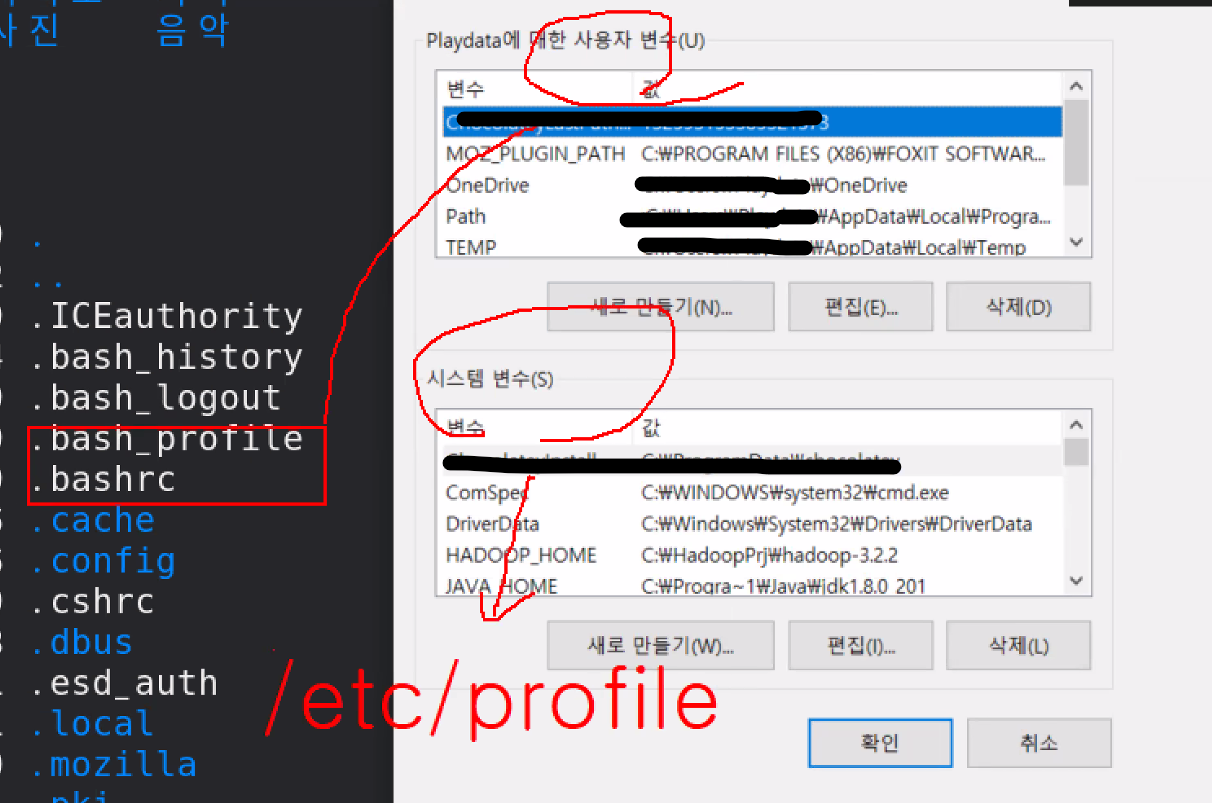
useradd hadooppasswd hadoop / hadoopJava 버전 => jdk 1.8 + Hadoop v3 : jdk 1.8 + Hadoop 버전 => Hadoop v3.2.2Hadoop v3.2.2 wget http://apache.mir
6.[Hadooop] HDFS 설치 3 - VM-완전분산모드
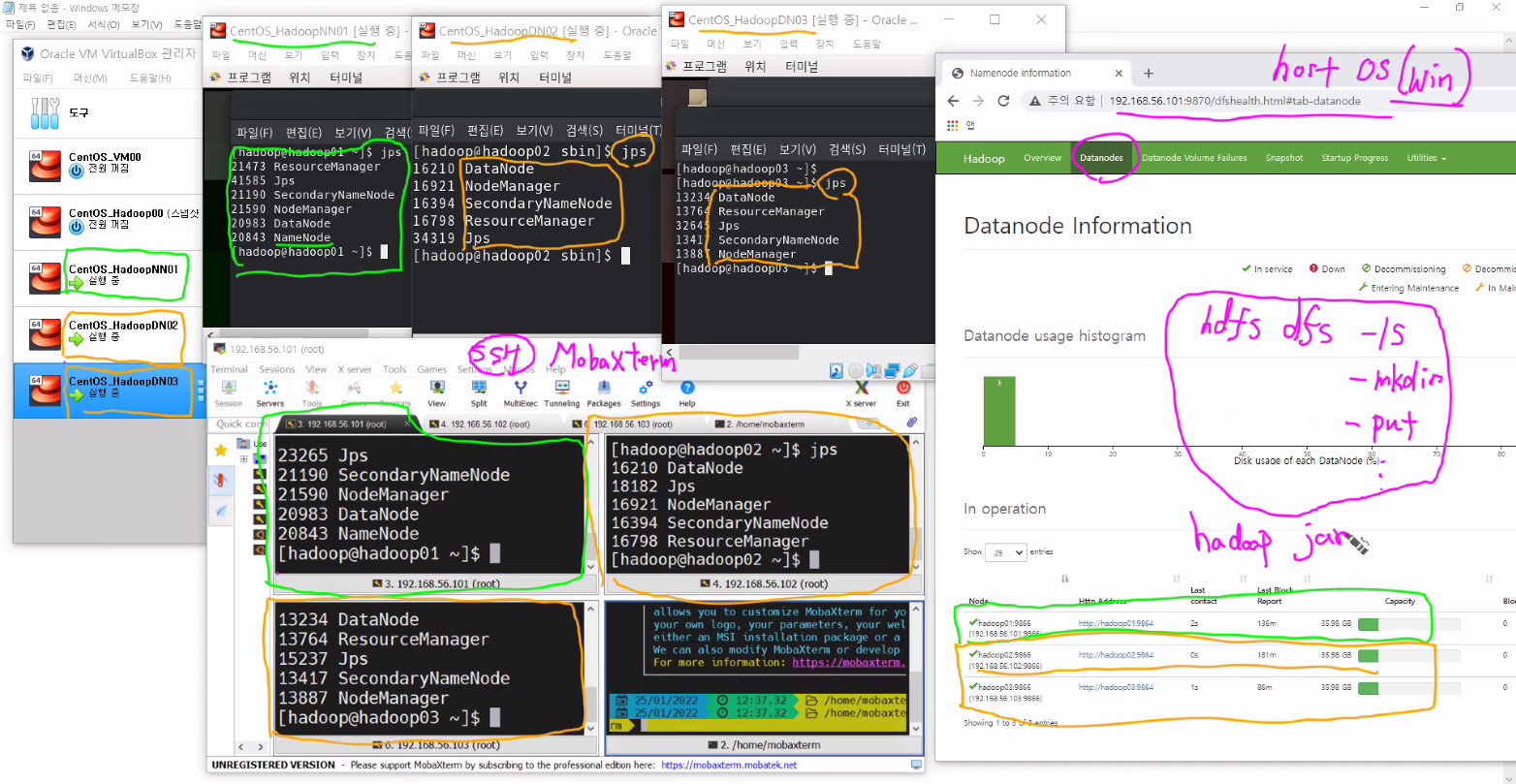
하둡이 서로 소통하기 위해서 공개키 갖고있어야 함 동떨어진 PC가 서로 소통하기 위해서는 신뢰할 수 있는 환경 => 공개키로 만든다고 생각공개키를 다 DATANODE에 COPY해놓아야 함
7.[Hadoop] wordcount 실습
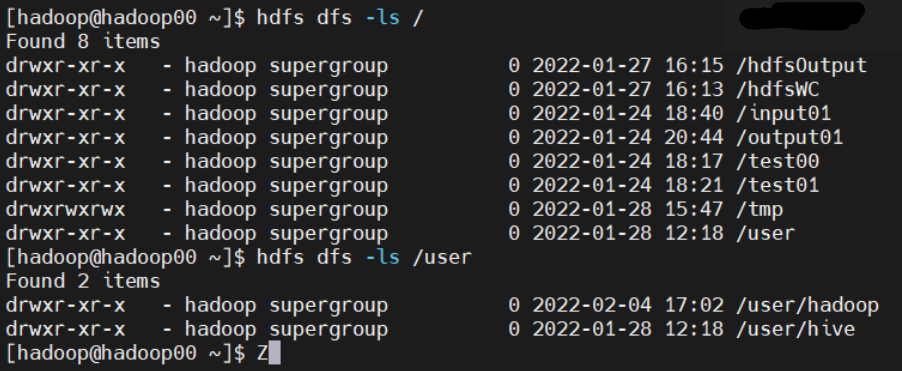
디렉토리 생성 /test00 touchz (0 bite 파일 생성) hdfs dfs -touchz /test01/test11.txtput README.txt hdfs dfs -put ./README.txt목적 : 하둡 맵리듀스의 이해 input01 폴더에 현재 경로에
8.[Hadoop] CentOS8 vsftpd 설치
dnf info vsftpd vsftpd 설치 : dnf install vsftpdvsftpd 시작 : systemctl start vsftpd vsftpd 상태 확인 : systemctl status vsftpdvsftpd/chroot_list 생성 설정touch c
9.[Hadoop] Hive 설치 및 시작 (MariaDB 기반)
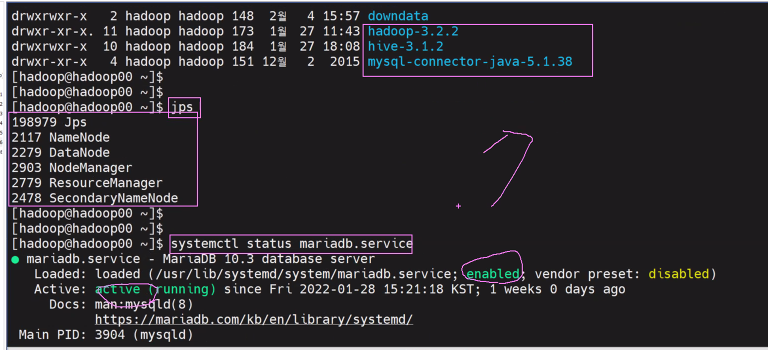
마리아db설치 실행 확인 mysql -u root -p https://devocean.sk.com/blog/techBoardDetail.do?ID=163549 mariadb 시작 서비스 시작 systemctl start mariadb.service MariaDB
10.[Hadoop] SQOOP 설치
이렇게 나오면 성공 sqoop eval --driver "com.mysql.jdbc.Driver" --connect "jdbc:mysql://localhost:3306" --query "select \* from fruits_db.fruits" --username "r
11.[Hadoop] flume 개념 및 설치
화면 구성 hadoop dfs 실행 start-dfs.shhadoop yarn 실행 start-yarn,sh설치 파일 경로 1) https://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html2) htt
12.[Hadoop] Spark 개념 및 설치
오픈 소스 클러스터 컴퓨팅 프레임워크https://spark.apache.org/1) multi language : Scala, Python, R, Java, SQL 2) cluster : 데이터 처리에 대한 cluster 3) 데이터 처리에 대한 얘기 =