Pandas
import pandas as pd
from pandas import Series, DataFrame
import mathDataframe
1
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]} ## 딕셔너리
frame = pd.DataFrame(data) ## 딕셔너리를 Dataframe으로 변환
frame#결과:
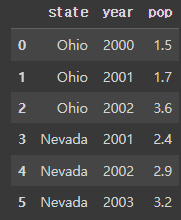
2
frame.head() ## 데이터프레임 샘플 확인 ## 괄호가 공백이면 기본 5개까지만 출력 ## 괄호안에 정수로 원하는 만큼의 샘플 출력 가능#결과:
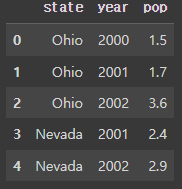
3
frame.tail() # 데이터프레임 샘플 확인 ## 괄호가 공백이면 뒤에서 기본 5개까지만 출력 ## 괄호안에 정수로 원하는 만큼의 샘플 출력 가능#결과:
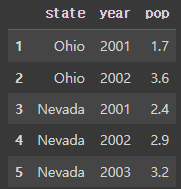
4
frame.describe() # 수치형 데이터에 대해 주요 통계치 출력#결과:
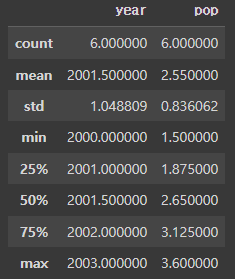
- count : 전체 샘플 수
- mean : 평균값
- std : 표준편차
- min : 최소값
- 25% : 하위 25%(1사분위수, Q1)
- 50% : 중간값(2사분위수, Q2 또는 median)
- 75% : 상위 25%(3사분위수, Q3)
- max : 최대값
5
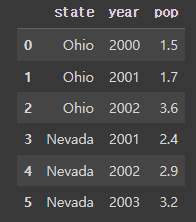
frame = frame.astype({'year': str}) # 수치형 데이터를 문자열 데이터로 타입 변경 (one-hot vector 생성을 위함)
frame#결과
6
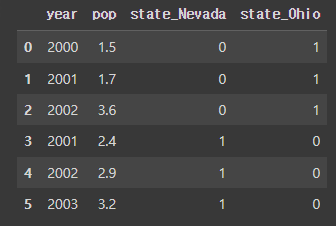
pd.get_dummies(frame) # 카테고리 문자열 데이터를 one-hot vector로 변환 # 0과 1로만 구분할 수 있게 해줌 -> 컴퓨터가 이해할 수 있게 함#결과:
7
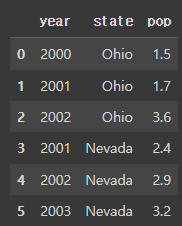
df = pd.DataFrame(data, columns=['year', 'state', 'pop']) ## data의 딕셔너리를 Dataframe으로 변환. 단, 열은 year state pop 순으로 생성
df
df.to_csv('data.csv') ## 파일에 저장 ## 다운받아서 엑셀로 열람#결과:
8
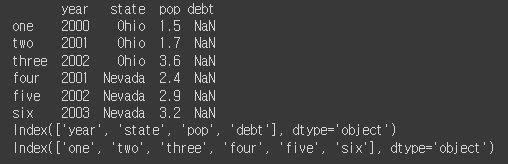
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four',
'five', 'six'])
print(frame2)
print(frame2.columns)
print(frame2.index)
# 리스트(list): 새로운 라벨 인덱싱하면 오류 발생
# 딕셔너리(dictionary): 새로운 라벨 인덱싱하면 새로운 라벨 생성
## Dataframe과 출력 형태가 다른 이유 : print와 그냥 출력의 차이#결과:
9
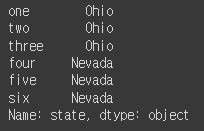
frame2['state'] # 데이터프레임의 'state' 열의 정보(index, values) 출력#결과:
10
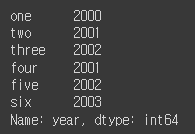
frame2.year # 데이터프레임의 'year' 열의 정보 출력의 다른 형태#결과:
11
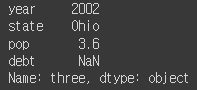
frame2.loc['three'] # loc: location 의미, [행, 열] 순으로 라벨 인덱싱할 때 사용#결과:
12
frame2.loc['three', 'state'] # 열을 추가하면 해당 정보 출력#결과: Ohio
13
frame2['debt'] = 16.5 ## 해당 열의 내용 전체를 초기화
print(frame2)
frame2['debt'] = range(6) ## 0부터 5까지 초기화
print(frame2)#결과:

14
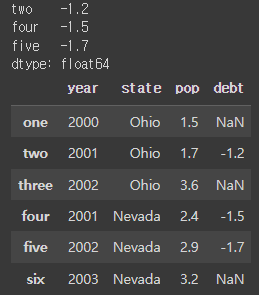
val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
print(val)
frame2['debt'] = val ## 특정 열을 초기화하여 업데이트할 수있음
frame2#결과:
15
frame2['eastern'] = frame2.state == 'Ohio'
"""
for index in frame2.index:
if frame2[index] == 'Ohio':
frame2['eastern'] = True
else:
frame2['eastern'] = False
"""
frame2#결과:
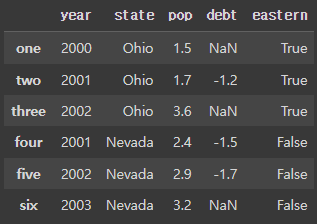
- 'eastern'이라는 새로운 열을 추가하는데, 이 열의 값은 'state'열의 값이 'Ohio'인지 아닌지에 따른 불린(boolean)값입니다. 즉, 'state'열에서 값이 'Ohio'인 경우 해당 행의 'eastern'열 값은 True가 되고 그렇지 않으면 False가 됩니다.
16
del frame2['eastern'] # 열단위로 지움
frame2.columns#결과:
Index(['year', 'state', 'pop', 'debt'], dtype='object')
17
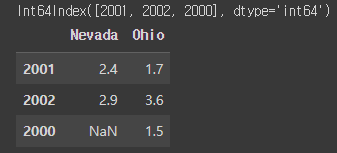
pop = {'Nevada': {2001: 2.4, 2002: 2.9},
'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
frame3 = pd.DataFrame(pop)
print(frame3.index)
frame3#결과:
18
frame3.T # 데이터프레임 transpose 시키기 ## 전치행렬 ## 대각선을 기준으로 반전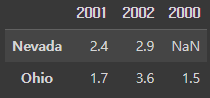
19
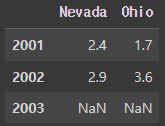
pd.DataFrame(pop, index=[2001, 2002, 2003])#결과:
20
pdata = {'Ohio': frame3['Ohio'][:-1],
'Nevada': frame3['Nevada'][:2]}
pd.DataFrame(pdata)#결과:
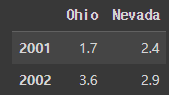
-
'Ohio': frame3['Ohio'][:-1] 부분은 Ohio 열의 마지막 요소를 제외한 모든 요소들을 선택하며 'Nevada': frame3['Nevada'][:2] 부분은 Nevada 열의 처음 두 요소만을 선택합니다.
-
따라서 pdata는 원래 DataFrame에서 일부 데이터만 추출하여 새로운 딕셔너리를 만드는 과정입니다.

공부 기록