Pandas, Numpy
import pandas as pd
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt #시각화를 도와주는 라이브러리
from random import sample
import string1
#랜덤 상수를 통한 임시 요소 List 생성
letters = string.ascii_lowercase # string 라이브러리에서 소문자들 사용
print(letters)
letter_samples = sample(letters, 20) ## 지정된 개수만큼의 항목을 무작위로 선택하여 새 리스트를 반환
print(letter_samples)
num_samples = sample(range(1300),20) #range() : 나열
print(num_samples)#결과:
abcdefghijklmnopqrstuvwxyz
['g', 'a', 'q', 'o', 'b', 'k', 'v', 'f', 'r', 'p', 'd', 'y', 's', 'e', 'w', 't', 'm', 'z', 'j', 'l'][817, 1109, 28, 1155, 23, 271, 974, 185, 1038, 289, 1146, 552, 1058, 39, 544, 656, 589, 101, 924, 172]
2
#생성한 List를 토대로 Dict 자료 생성
data = {}
for letter, num in zip(letter_samples, num_samples): ## zip함수로 묶기
data[letter] = [num]
data
# list = [] #리스트
# dict = {"key":"value"} #딕셔너리
##가로가 아니라 세로로 출력되는 이유 : 파이썬에서 딕셔너리를 출력할 때 기본적으로 한 줄에 하나의 key-value 쌍을 출력하기 때문#결과:
{'g': [817],
'a': [1109],
'q': [28],
'o': [1155],
'b': [23],
'k': [271],
'v': [974],
'f': [185],
'r': [1038],
'p': [289],
'd': [1146],
'y': [552],
's': [1058],
'e': [39],
'w': [544],
't': [656],
'm': [589],
'z': [101],
'j': [924],
'l': [172]}
3
# dict자료를 DataFrame으로 변경
df = pd.DataFrame.from_dict(data=data, orient='index', columns=['number']) ## orient를 'index'로 설정하면 딕셔너리의 키가 DataFrame의 인덱스로 사용된다 ## 'columns'로 설정하면, 딕셔너리의 키가 열 이름으로 사용된다
df ## 'orient' 파라미터가 'index'로 설정되어 있으므로, 딕셔너리의 각 키(letter)가 DataFrame의 인덱스로 설정되고, 해당하는 값(num)은 'number'라는 이름을 가진 열에 할당됩니다.#결과:

4
plt.title("Plot") #그래프 제목
plt.plot(df.index, df['number'],) #꺾은선 그래프 디폴트 ## 마지막 쉼표 : 추가적인 인자를 제공할 수 있음을 나타낸다 ## x와 y 좌표값을 인자로 받아서 2차원 그래프를 생성한다
plt.show()#결과:
5
plt.bar(df.index, df['number']) #바 그래프
plt.title("Bar Plot")
plt.xlabel("number") #x축 이름
plt.ylabel("letter") #y축 이름
plt.show()
6
colors = ['y', 'dodgerblue', 'C2', '#e35f62']
plt.bar(df.index, df['number'], color=colors)
plt.title("Color")
plt.xlabel("number")
plt.ylabel("letter")
plt.show()#결과:
- 'y' : 기본적인 색깔 문자열 (yellow)
- 'dodgerblue' : HTML/CSS 스타일의 색깔 이름
- 'C2' : matplotlib에서 정해진 기본 세트 중 3번째 색 (cycle: C0 ~ C9)
- '#e35f62' : HEX 형식으로 표현된 RGB 값
7
for width in [0.4, 0.6, 0.8, 1.0] :
plt.bar(df.index, df['number'], width=width)
plt.title(str(width))
plt.show()#결과:
8
plt.title("Stem Plot")
plt.stem(df.index, df['number'], '-.') ## Stem plot은 각 데이터 포인트를 선과 점으로 표시하는 그래프로, 이산 확률 함수나 자기상관 등을 시각화할 때 유용하다
plt.show()#결과:
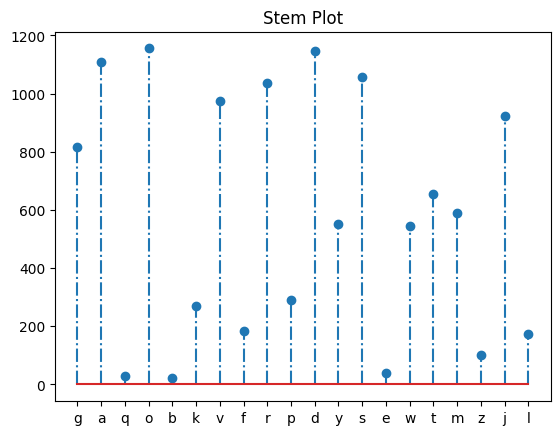
9
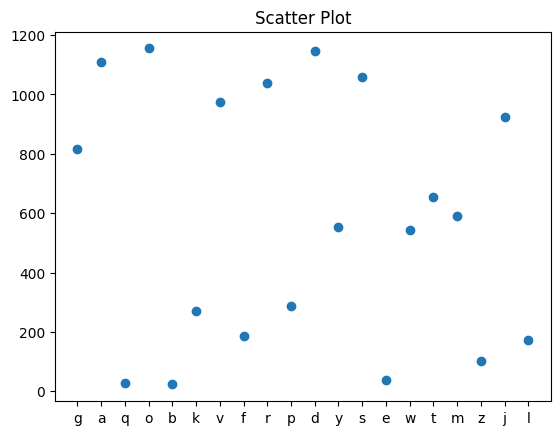
plt.title("Scatter Plot") # 해당 위치만 점으로 표현
plt.scatter(df.index, df['number'],)
plt.show()#결과:
10
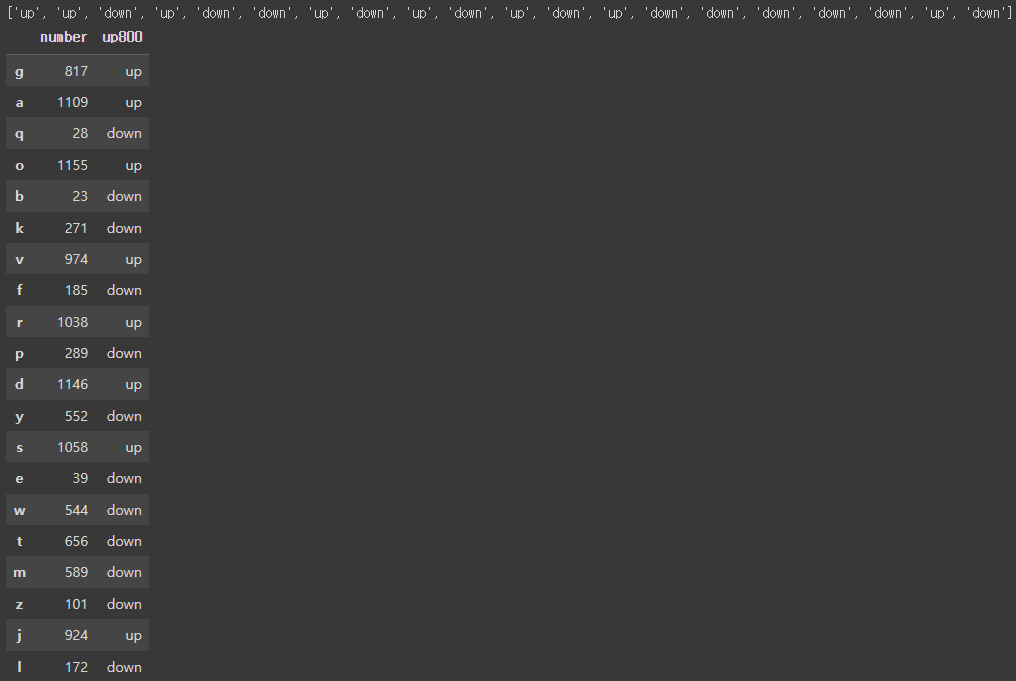
def up_and_down(thres, num_list):
up_and_down =['up' if number > thres else 'down' for number in num_list] #리스트 컴프리헨슨
print(up_and_down)
return up_and_down
df.insert(1, 'up800', up_and_down(800, df['number']))
df#결과:
11
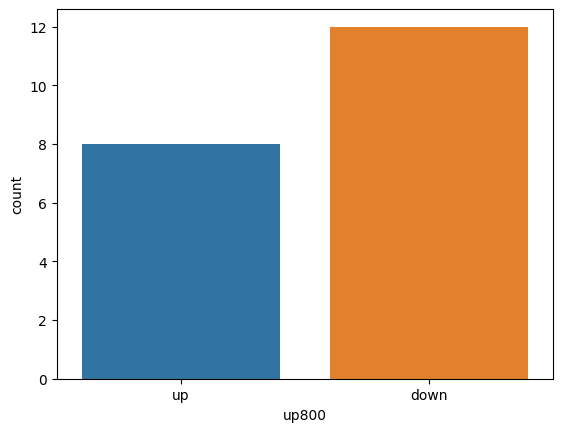
import seaborn as sns #그래프 종류가 더 많음
sns.countplot(x = df['up800']) #카운트 플롯은 범주형 열의 각 범주에 대한 빈도수를 막대그래프로 나타낸다#결과:
12
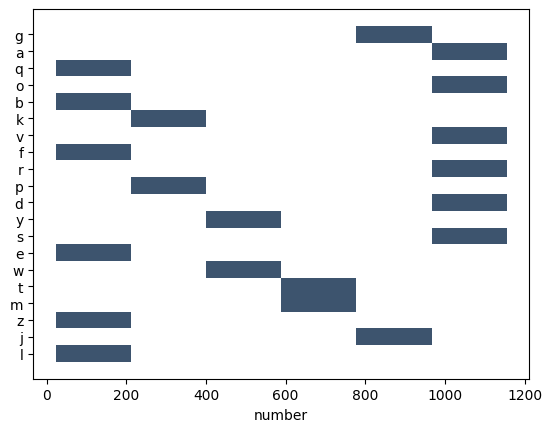
sns.histplot(x=df['number'], y=df.index) #히스토그램 ##히스토그램은 변수의 분포를 시각화하는 데 사용되며, 데이터를 일정한 간격의 구간으로 나누고 각 구간에 속하는 데이터의 수(빈도)를 막대로 표시한다#결과:

공부 기록