Intra Prediction
- 이전 영상이나 이후 영상 등을 사용하지 않고 현재 영상에 대해서만 정보를 가지고 예측을 하는 방법
- 즉, 동일한 프레임 내에서 이미 알려진 정보를 사용하여 압축되지 않은 픽셀을 예측하는 비디오 압축 기술이다
- 이 기술은 다양한 방향(예: 수평, 수직, 대각선)으로 작동한다
- 인트라 프레임 내의 픽셀은 그 주변 픽셀에 기반하여 예측되며, 이로 인해 데이터가 효과적으로 압축되는 것이 가능하다
- 이러한 예측은 일반적으로 블록 단위로 이루어지며, 각 블록은 독립적으로 압축되고 복원된다
- 이 방법의 가장 큰 장점은 데이터 전송률을 크게 줄일 수 있다는 것이다. 이는 특히 대용량의 비디오 데이터를 실시간으로 전송해야 하는 상황에서 매우 유용하다
- 하지만 완벽한 복원을 보장하지는 않으며, 때때로 손실된 데이터로 인한 화질 저하가 발생할 수 있다
Intra Prediction mode
- Intra Prediction은 예측하려는 블록과 주변의 이미 부호화된 블록 사이의 방향성을 가지고 예측을 하는데 이 방향성을 mode로 정의해놓았다
- AVC/H.264에서는 9가지의 intra predictoin modes가 있다
- HEVC에서는 35가지의 intra predictoin modes가 있다
- VVC에서는 67(+20)가지의 intra predictoin modes가 있다
The Number of Intra Prediction Modes
- 33(HEVC) -> 65(+20) (VVC)로 추가 됨
- (+20)은 현재 블록이 직사각형인 경우에 사용되는 mode로, 추가로 20가지의 mode를 지원한다
- 65가지의 모드로 늘렸을 때의 bit rate가 1% 이상 좋아진다
- 0과 1은 각각 PLANAR와 DC모드이고, 2 ~ 66번까지 intra mode이다
- 81번 부터 83까지는 chroma를 위한 mode이다
Planar Mode
- 현재 샘플의 왼쪽 reference 샘플과 현재 블록의 TR(Top Right) 샘플을 가지고 와서 두 개의 샘플의 거리 값을 가지고 linear interpolation을 하여 R_1을 만든다
- 이번에는 세로방향으로 똑같이 진행한다. 현재 샘플의 위쪽 reference 샘플과 현재 블록의 LB(Left Bottom) 샘플을 가지고 와서 두 개의 샘플의 거리 값을 가지고 linear interpolation을 하여 R_2을 만든다
- 그 후 R_1과 R_2를 평균을 취하여 최종적인 예측값을 생성한다
- 위 작업을 모든 샘플에 적용해서 예측값을 만들어내는 것이 Planar Mode이다
- Planar Mode는 다른 Mode나 DC에 비해 훨씬 많이 선택된다
DC Mode
- 현재 블록의 값들이 대부분 비슷한 값일 때 예측이 잘 된다
- 현재 블록 모든 값들을 현재 블록의 상단에 위치한 참조 샘플과 좌측에 위치한 참조 샘플들에 대한 평균값으로 예측한다
- 예측하려는 블록이 정사각형인 경우 Shift 연산으로 간단하게 계산할 수 있지만, 예측하려는 블록이 직사각형인 경우에는 나눗셈을 이용하여 연산을 수행해야 한다
- 나눗셈을 사용하지 않기 위해 더 긴 쪽의 참조 샘플 길이를 기준으로 평균값을 계산하여 현재 블록에 DC 예측값으로 활용한다
- 예측하려는 블록이 직사각형인 경우에도 정사각형처럼 계산한 것과 더 긴 쪽의 참조 샘플로만 계산하는 경우의 차이가 거의 없어 VVC 표준으로 선택되었다
Horizontal, Vertical Mode
- Horizontal Mode
- 현재 예측하려는 블록의 왼쪽 참조 샘플로만 예측값으로 활용하는 방법이다
- Vertical Mode
- 현재 예측하려는 블록의 상단 참조 샘플로만 예측값으로 활용하는 방법이다
Directional (or Angular) Intra Mode
- VVC에서는 65가지의 방향성 모드를 지원한다
- 현재 예측하려는 샘플의 방향성을 따라 주변 참조 샘플을 향해 따라가보면 정수 인덱스에 딱 맞아 떨어지지 않는 경우가 있을 수 있다
- 이 때 정수로 반올림을 해버리면 손실이 발생할 수 있기에 손실을 줄이고자 기준점을 정해서 그 기준점을 바탕으로 예측한다
- 기준점은 참조 샘플의 주변 4개의 값에 가중치를 곱하고 필터링하여 생성한다
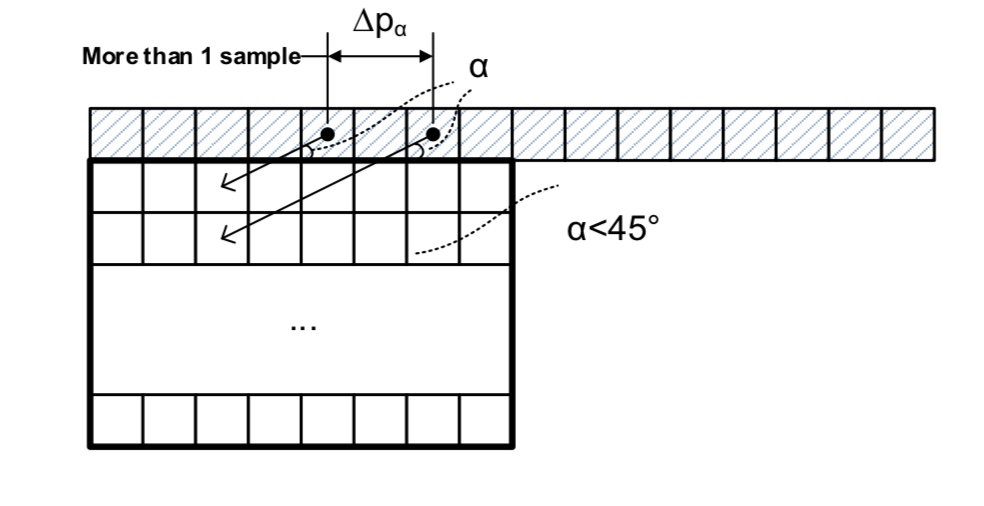
Wide-angle Intra Prediction
- 기존 방향성 모드에서는 45° 내에서의 방향성 모드만 지원했다
- 하지만 예측하려는 블록이 직사각형이라면 짧은 변보다는 긴 변과 가까운 쪽의 샘플을 참조하면 정확도가 더 높을 것이라고 생각하여 추가로 20가지의 방향성 모드를 추가했다
- 가로로 긴 직사각형인 경우 좌측 하단보다는 우측 상단의 샘플들을 활용해서 예측을 수행하고, 세로로 긴 직사각형의 경우에는 우측 상단보다는 좌측 하단의 샘플을 활용하여 예측을 한다
- Wide-angle Intra Prediction은 방향성이 기존보다 더 누워있거나 세워져 있기에 샘플은 인접해 있지만 예측 샘플을 보면 거리 차이가 생길 수 있다
- 거리 차이로 인한 부정확성이 생길 수 있기에 방향성의 각도가 너무 누워있거나 세워져 있는 경우 불연속성을 줄이기 위한 별도의 필터링 작업을 추가로 진행한다
Position Dependent Prediction Combination(PDPC)
- 67개의 Intra mode로 예측값을 생성한 후 적용되는 것이 PDPC이다
- 예측값을 만든 후 보정을 추가로 하는 작업이다
- 예측하고자 하는 값은 주변의 참조 샘플 값과 비슷하므로 주변의 참조 샘플의 점으로 보정한다
- Intra mode로 예측한 값과 주변 세 개의 샘플 값에 가중치를 곱하고 더함으로써 최종적인 예측값을 계산한다
- 곱해주는 가중치 값은 Intra mode, 예측값의 x, y 값에 따라 정해진다

Planar, DC Mode인 경우
- 주변 3 개의 샘플이 아닌 2 개의 샘플을 사용하여 보정한다
- 주변 샘플 2개와 예측값 P까지 총 3개의 샘플을 weighted sum 하여 보정하게 된다
VER, HOR Mode인 경우
- Horizontal mode인 경우
- 좌측 샘플은 값이 0이 된다(HOR mode이기 때문)
- 현재 화소의 상단의 샘플과 좌상단의 샘플을 사용하여 보정한다
- 좌상단과 상단의 샘플의 거리(Δ)를 추가로 더해준다
- Vertical mode인 경우
- 상단의 샘플은 값이 0이 된다(VER mode이기 때문)
- 현재 화소의 좌측의 샘플과 좌상단의 샘플을 사용하여 보정한다
- 좌상단과 좌측의 샘플의 거리(Δ)를 추가로 더해준다
Adjacent Diagonal Mode인 경우
- 대각선과 비슷한 Mode인 경우이다
- 예측값 P을 기준으로 예측 샘플과 그 반대 방향의 예측 샘플을 활용하여 weighted sum을 하여 보정한다
PDPC의 적용
- Planar와 DC Mode인 경우
- HOR, VER Mode인 경우
- Mode 10과 동일하거나 더 작은 Mode인 경우(우상단으로 향하는 방향 Mode)
- Mode 58과 동일하거나 더 큰 Mode인 경우(좌하단으로 향하는 방향 Mode)
- 방향 모드가 45°보다 작은 경우에 PDPC를 적용하지 않는 이유
- 각도상의 이유로 사용하려는 참조 샘플이 없게 된다
Intra Sub-Partitions (ISP)
- 67개의 예측 모드 외의 다른 모드이다
- 하나의 CU(Coding Unit)를 두 개 이상의 서브 파티션으로 나누고, 각각의 서브 파티션에 대해 독립적으로 인트라 프레임 예측을 수행하는 방식이다
- 4x8, 8x4 CU인 경우 각각 가로, 세로로 한 번씩 쪼개고, 나머지 경우에 대해서는 4개로 쪼개서 예측을 수행한다
- 블록을 쪼개서 예측을 진행하면 참조 샘플과 예측 샘플의 거리를 줄일 수 있어 좀 더 정확한 예측을 수행할 수 있다
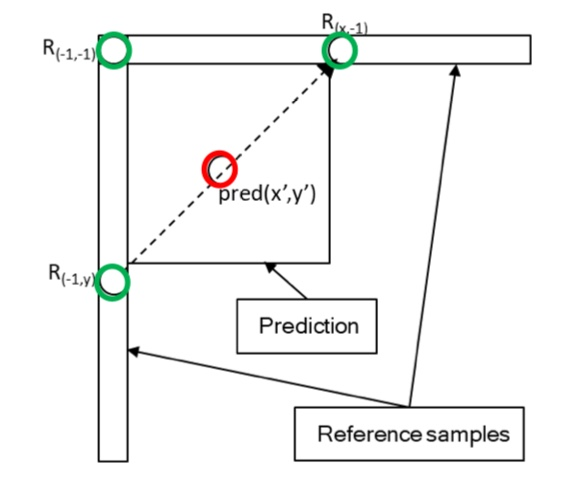
Multi-Reference Line (MRL)
- 기존의 인트라 프레임 예측 방식에서는 주로 현재 블록의 바로 위쪽 또는 왼쪽에 위치한 블록의 픽셀 값을 참조하여 예측을 수행했다
- 하지만 MRL을 사용하면, 이보다 더 넓은 범위의 블록을 참조하여 예측을 수행할 수 있다. 즉, 여러 개의 참조 라인을 사용하여 예측을 수행하는 방식이다
- 여러 개의 참조 라인 중 가장 좋은 참조 샘플을 선택하여 예측을 수행한다
- 하나의 블록에 대해 예측을 수행할 때 화소별로 다른 라인의 참조 샘플을 사용하는 것이 아닌 블록 전체의 화소는 같은 라인에 있는 참조 샘플을 상요하여 예측을 진행한다
Cross-Component Linear Model (CCLM)
- Chroma를 예측하는 방법이다
- 비디오 코딩에서는 Luma를 먼저 코딩하고 Chroma를 코딩한다. 그러면 Chroma를 코딩할 때 Luma의 복원된 화소값을 활용할 수 있게 된다
- Luma의 Texture 값과 Chroma의 Texture값이 유사할 수 있다
- Luma와 Chroma는 밝기냐 색이냐의 차이이기 때문에 Texture는 같을 수 있다
- 하지만 반대로 Luma 샘플과 Chroma 샘플은 일치하지 않을 수도 있다. 그래서 Luma 샘플에 Linear 모델로 α를 곱해주고, β를 더해줘서 Chroma 샘플로 예측을 수행한다
- α, β는 Luma의 복원된 주변 샘플값, Chroma의 주변 샘플값 이 두 개의 관계를 가지고 계산한다
- 주변 샘플값을 기준으로 상단과 좌측 참조 샘플을 활용하면 LT CCLM, 좌측 참조 샘플만 활용하면 L CCLM, 상단 참조 샘플만 활용하면 T CCLM이라고 한다
- L CCLM의 경우 좌측 참조 샘플의 길이를 두 배로 늘려서 사용한다
- T CCLM도 마찬가지로 상단의 참조 샘플의 길이를 두 배로 늘려서 사용한다
α, β 계산
- 처음 VVC 표준일 때는 주변 샘플 값을 모두 활용해서 정확도를 높였지만 계산이 너무 복잡해져 현재는 4 개의 샘플 pair만 가지고 α, β를 계산한다
- 4 개의 샘플 pair는 블록 사이즈에 따라서 위치가 미리 지정되어 있다
- Chroma는 Luma 보다 가로, 세로가 1/2 크기이기 때문에 Luma 참조 샘플 pair 위치가 정수가 아니다. 그래서 중간값을 만들어 내기 위해서 주변 샘플의 6개의 값을 바탕으로 만들어 낸다
- 4 개의 샘플에서 큰 값 2개와 작은 값 2개로 분류하여 큰 값 pair의 중간값, 작은 값 pair의 중간값을 만들어 낸다
- 만들어 낸 두 개의 값으로 linear 식을 만들어 내어 α, β를 계산한다
- 이제 Chroma 예측값을 계산하기 위해서 Chroma i,j 에서의 luma 값을 찾아야 한다
- Chroma의 하나의 화소가 Luma의 6 개의 화소와 맵핑되기 때문에 어떤 Luma의 화소를 가져올 것인가를 정해야 한다
- 두 가지 방법
- Chroma에 대응되는 Luma의 6 개의 화소를 필터링해서 weighted sum하여 값을 만들어내는 방법
- Chroma에 대응되는 Luma의 십자 모양으로 5 개의 점을 가지고 하나의 값을 만들어내는 방법
- sps_cclm_colocated_chroma_flag의 값에 따라 위 두 가지 방법 중에 선택된다
- sps_cclm_colocated_chroma_flag가 0이면 첫 번째 방법을 1d이면 두 번째 방법을 사용한다
Matrix-weighted Intra Prediction (MIP)
- Luma에 대해서 예측하는 방법이다
- 예측하려는 블록의 상단 화소 값과 좌측 값을 학습하여 후보들을 여러 개 가지고 있다가 적용하는 방법이다
- 즉, 상단 화소값과 좌측 화소값을 Matrix 연산을 통해서 현재 블록의 예측값을 만들어내는 방법이다
Predictoin Signal Generation of MIP
- 상단의 샘플값과 좌측의 샘플값 모두를 사용하면 계산이 복잡해지므로, 평균값을 취해서 상단 4개, 좌측 4개 값으로 줄인다
- 상단 4개, 좌측 4개 총 8개의 값을 벡터로 나타낸다. 이 벡터값에 A라는 Matrix를 곱해주고, b라는 offset을 더해줘서 16개의 값을 만들어 낸다
- 16개의 값을 순서대로 채워넣고 중간에 비어 있는 값들은 참조 샘플을 활용하여 채워넣는다. 다 채워넣으면 최종 예측값이 생성된다
- A Maxtrix는 미리 학습시켜 16개의 후보를 만들어 두고 상황에 따라 다르게 적용하여 예측값을 생성해낸다
- 4x4 블록인 경우 16개의 Matrix가 미리 정의되어 있다
- 4x8, 8x4, 8x8의 경우 8개의 Matrix가 미리 정의되어 있다
- 그 외의 경우 6개의 Matrix가 미리 정의되어 있다
- 블록의 크기에 따라 각각 16, 8, 6개의 Matrix가 정의되어 있지만 벡터를 만들 때 좌측 참조 샘플을 먼저 위치시켜 벡터를 만들지, 상단 참조 샘플을 먼저 위치시켜 벡터를 만들지에 따라 결과가 달라지므로 총 32, 16, 12개의 Mode를 지원하게 된다
MDIS and Interpolation filters
Mode Dependent Intra Smoothing (MDIS)
- 예측 모드에 따라 스무딩을 적용하는 방법을 제공하여, 예측의 정확성을 높이고 비디오 압축 효율을 향상시킨다
- MDIS에서 사용하는 스무딩 알고리즘은 예측 모드에 따라 달라진다
Interpolation Filter
- 누락된 데이터를 추정하거나 고해상도의 데이터를 생성하는 데 사용된다
- Angular Intra Mode인 경우 참조 샘플 위치값이 정수가 아닐 수도 있다
- 이 경우 임의의 정수값을 만들어내야 하는데 주변의 4개의 값을 이용하여 만들어내고 그 값을 예측값으로 사용한다
Cubic filter
- Interpolation Filter이다
- 픽셀 값을 보간하는 데 사용된다
- 픽셀 값 사이를 채우는(interpolation) 역할을 한다
Gaussian filter
- Interpolation Filter이다
- 가우시안 필터는 가우스 분포를 따르는 커널을 사용하는 입력을 필터링한다
- 이 커널은 중심에 가까운 픽셀에 높은 가중치를 부여하고, 멀리 떨어진 픽셀에는 낮은 가중치를 부여하여, 중심에 가까운 픽셀의 영향력을 더 크게 한다
Smoothing Filter
- Intra prediction에서 주변 참조 샘플을 활용하는데 이 참조 샘플은 복원되어 있는 값이다. 복원된 값은 복원과정에서 양자화, 역양자화 등의 과정을 거치게 되는데 이 과정에서 화소끼리의 값차이가 발생한다. 이를 해결하기위해 smoothing filter를 사용한다
- VVC 표준 Smoothing filter는 3 tap filter을 사용한다
- 3 tap filter는 참조 샘플 3개를 smoothing 시켜서 적용한다
- 3 tap filter의 참조 샘플의 가중치는 [ 1/4, 2/4,1/4 ]이다
- 3 tap filter로 smoothing한 참조 샘플을 예측값으로 사용하면 예측의 정확도가 올라간다
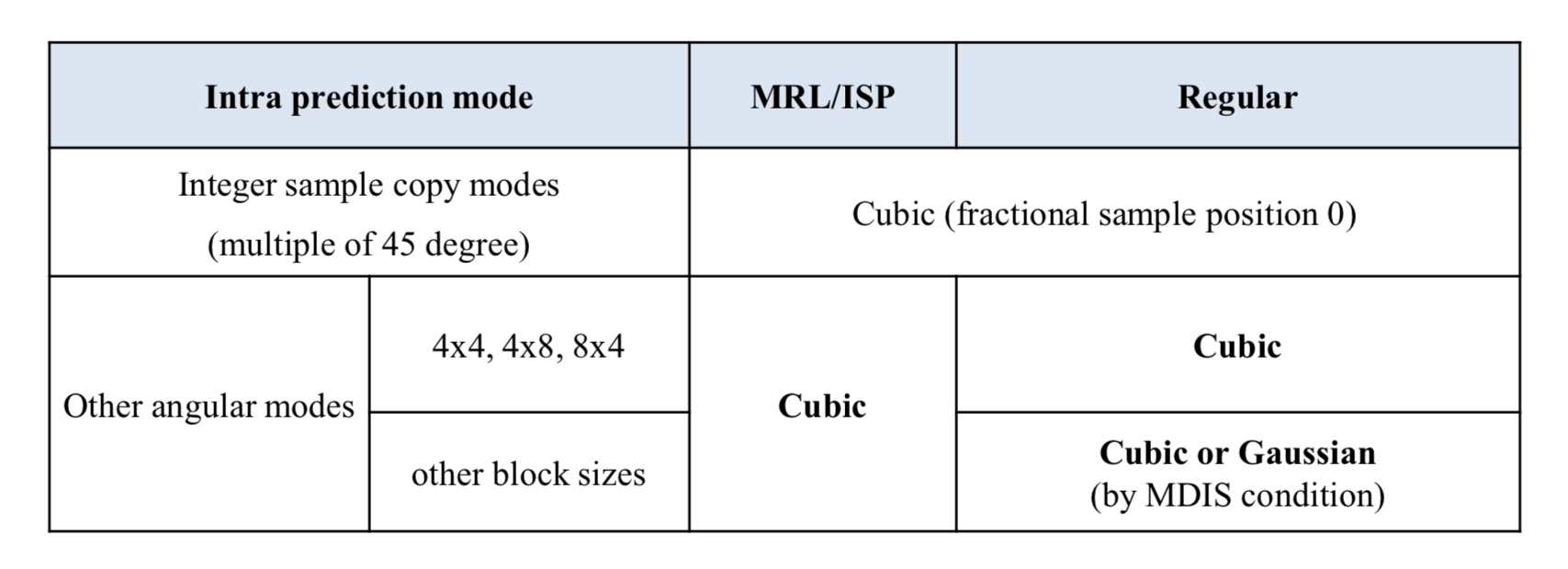
Filter 선택 및 사용
- Intra Prediction Mode에 따라 그룹을 3개로 나눈다
- Group A는 vertical, horizontal mode이며 필터링을 거치지 않는다
- Group B는 예측 방향성이 45° 내외 및 배수에 해당하는 모드와 Planar Mode가 속한다. ( -14, -12, -10, -6, 2, 34, 66, 72, 76, 78, 80)
- Goup B는 smoothing filter를 적용하고 interpolation filte는 적용하지 않는다
- Gourp C는 interpolation filter를 적용한다
Interpolation Filter for Chroma
- Chroma는 주변의 2개의 샘플에 대해서만 interpolation으로 중간값을 만들어내고 그 값을 예측에 사용한다
Most Probable Modes (MPMs)
- 주변 블록들의 모드를 분석하여 현재 블록의 인트라 예측 모드를 빠르게 결정하기 위한 방법이다
- 디코더에게 예측하는 데 사용한 Mode를 효율적으로 보내주기 위해 가장 많이 발생한 Mode 6개를 List로 만들게 되고 그 Mode들 중 하나를 사용했다고 디코더에게 알려준다
- 6 개의 리스트 중 MPMs에 있는지 없는지, 있다면 인덱스는 몇 번인지 총 2 개의 정보를 디코더에게 보내준다. 만약 MPMs에 없다면 MPMs에 없다는 정보 하나와 나머지 모드 (67 - 6) 중 어느 모드를 사용했는지 총 2개의 정보를 보내준다
- Planar 모드는 가장 많이 발생하기에 default로 flag를 통해 Planar 모드인지 아닌지를 알려준다
- 그 외 나머지 5개는 현재 블록의 상단 블록과 좌측 블록의 화면내 부호화 모드에 대한 번호를 바탕으로 계산하여 정한다
Intra Mode Coding for Chroma
- Chroma 예측 모드는 기본적으로 Planar, VER, HOR, DC 모드 밖에 없다
- 위 4가지 모드에 추가적으로 1개의 모드를 더 허용하는데 이 모드는 Luma가 사용했던 모드를 사용할 수 있다
- Luma가 사용했던 모드를 DM 모드라고 한다
- 또한 추가적으로 LT_CCLM, L_CCLM, T_CCLM 모드를 사용한다
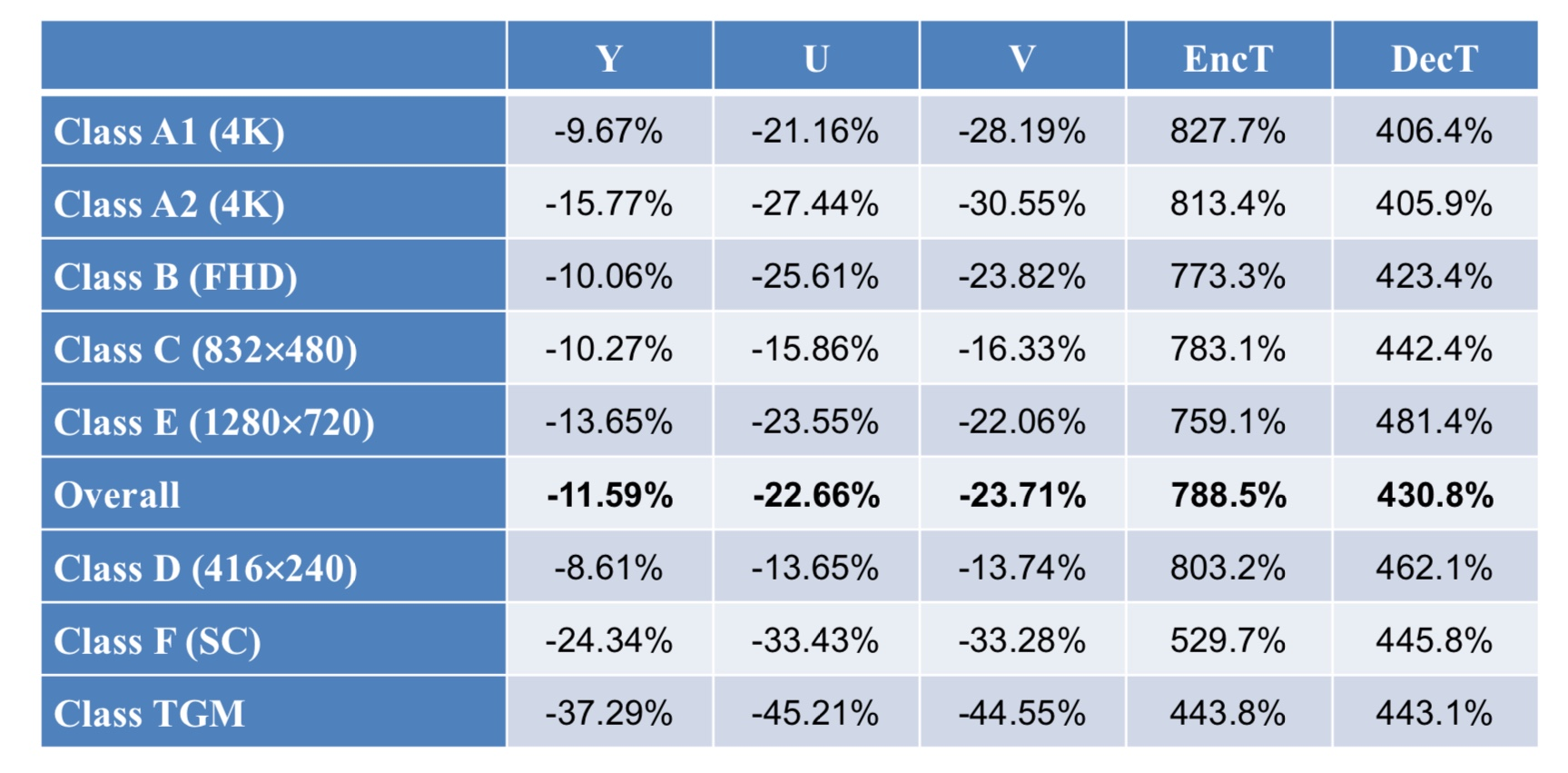
Enhanced Compression Model (ECM)
- 아직까지 표준으로 만들어진 것이 아니다
- VVC 보다 좀 더 부호화 효율이 좋은 방법들에 관한 내용들이다
- VVC에 비교하여 ECM은 약 12% 더 우수한 것으로 나온다
- 하지만 복잡도는 Encoder는 약 788.5%, Decoder는 약 430.8% 더 복잡하다
Luma Predictoin Tool
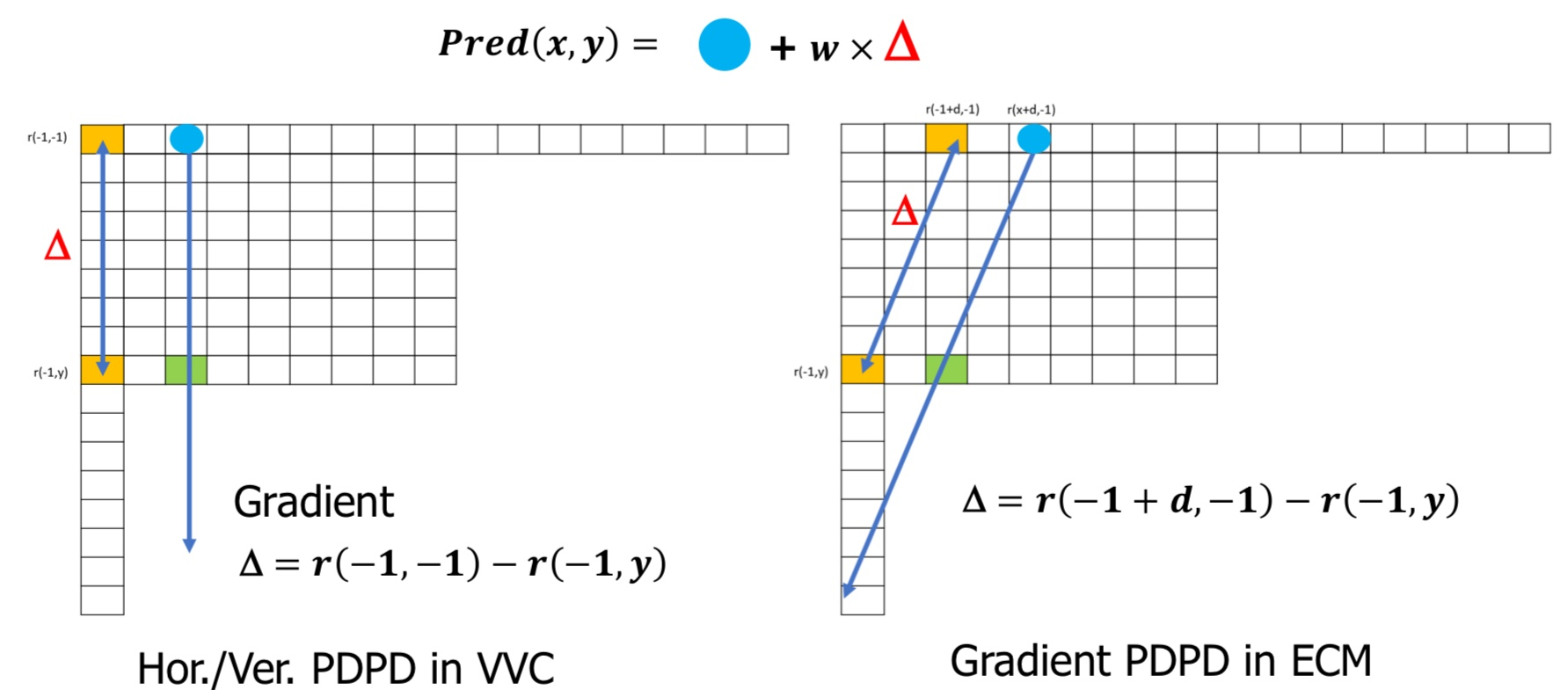
Gradient PDPC
- PDPC는 원래의 예측신호와 예측하려는 화소를 기준으로 반대편의 예측신호 둘 다 이용하여 예측을 수행하는 방법이다
- 하지만 각도가 너무 크다보면 반대편의 예측 샘플이 없어 사용할 수 없기에 기존 PDPC는 Mode가 58번 보다 크거나 10번 보다 작은 경우에만 적용했다
- 하지만 ECM에서는 Gradient PDPC로 이 문제를 해결했다
- 각도가 너무 커서 반대편에 샘플값이 없는 경우에는 양방향으로 샘플값이 있고 동일한 예측 방향인 샘플을 찾아서 원래의 예측값과의 차이 d만큼 평행이동해서 Δ값을 계산한다
- 그 후 Δ값에 가중치 값을 곱해서 원래 예측값에 더해줘서 최종적인 예측 샘플을 계산하게 된다
Interpolation Filter in ECM
- Cubic filter
- 기존 4 tap filter에서 6 tap filter로 변경되었다
- Gaussian filter
- 크기가 큰 경우(W >= 32, H >= 32)에 6 tap filter를 적용한다
Extended Intra Reference Samples
- 좌측 샘플을 상단 샘플로 올려서 하나의 차원 샘플로 만들어줄 때 기존 VVC에서는 정수가 아닌 샘플을 위로 올린다고 했을 때 가까운 정수값을 그냥 올렸다
- 하지만 가까운 정수값으로 올리면 부정확해진다
- ECM에서는 4개의 값을 필터링해서 중간값을 생성하여 위로 올린다
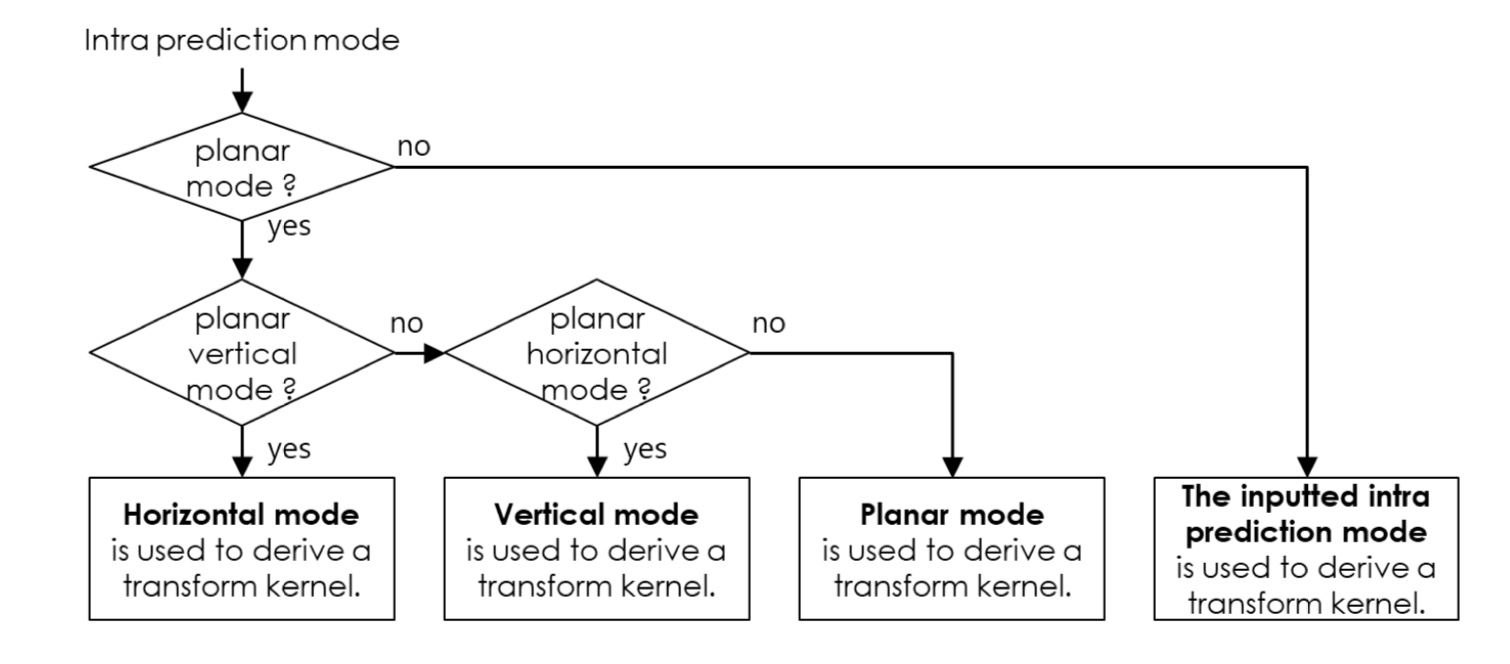
Directional Planar Mode
- 기존 VVC의 Planar Mode는 horzontal와 vertical의 평균을 사용했다
- ECM은 기존 Planar Mode에 Horizontal mode만 사용하는 Planar horizontal mode와 Vertical mode만 사용하는 Planar Vertical mode도 추가로 지원한다
- 세 Planar Mode 중에서 골라서 사용하게 된다
Decoder side intra mode derivation (DIMD)
- 주변의 Template을 사용해서 부호화 모드를 decoder에게 직접 전송하지 않고 부호화 모드를 추론한다는 점이 VVC와의 가장 큰 차이점이다
- Decoder에서 부호화 모드를 직접 수신받지 않고 decoder 자체에서 현재 블록에서 부호화 모드가 무엇인지 알아내는 방법 중 하나이다
- 현재 블록을 주변 샘플이 아닌 더 넓은 범위를 가진 Template를 사용해서 가장 적당한 부호화 모드를 예측한다
- Vertical Shovel Operator와 Horizontal Shovel Operator를 사용해서 Template를 적용하면 G_ver(세로 방향 화소값 차이의 크기)과 G_hor(가로 방향 화소값 차이의 크기)이 나오게 된다
- G_ver과 G_hor을 가지고 각도 θ를 계산할 수 있다
- θ는 가로 방향으로 차이가 얼만큼 크냐, 세로 방향으로 차이가 얼만큼 크냐를 알려준다
- 여러개의 θ가 나오게 되는데 가장 많이 발생한 θ를 2개 혹은 5개를 골라내서 θ에 대응하는 Intra Mode를 사용하여 예측을 수행한다
Fusion for Template-based Intra Mode Derivation (TIMD)
- 현재 블록을 기준으로 상단과 좌측 template를 사용한다
- template을 기존의 intra 예측처럼 template 주변 참조 샘플로 예측을 수행한다. 이 예측값과 기존 template의 실제 값차이를 SATD로 계산한다. 이 때 가장 예측이 잘 된 2가지 경우를 가지고 현재 블록 예측을 수행한다
- 즉, TIMD는 template와 template의 reference의 차이값을 가지고 현재 부호화 블록을 예측한다
Intra Template Matcing (IntraTMP)
- 현재 블록을 기준으로 상단과 좌측을 template로 사용한다
- template를 현재까지 부호화한 블록에서 가장 비슷한 template를 찾는다
- 가장 비슷한 template를 찾으면 그 template의 블록을 바탕으로 현재 블록을 예측한다
- 가장 비슷한 하나의 template을 사용할 수도 있고, 두 개의 template를 섞어서 사용할 수도 있다
- 또한 정수 위치의 template를 사용할 수도 있다
- 비슷한 template라고 해도 밝기값에서 차이가 발생할 수 있기에 Linear filter model로 보정 작업도 해줄 수 있다
Combination of CIIP with TIMD and TM merge
- VVC의 CIIP (Complex Intra Prediction)
- Inter와 Intra Planar를 섞어서 예측 신호를 만들어 내는 방법이다
- ECM의 CIIP (Complex Intra Prediction)
- VVC의 CIIP에 추가로 CIIP-TM merge 신호와 TIMD로 찾은 모드의 Intra 예측 신호를 섞어서 예측 신호를 만들어 내는 방법이다
Spatial Geometric Partitioning Mode (SGPM)
- 기존 VVC의 GPM
- 블록을 비대칭적으로 분할(대각선으로 분할)하여 한 쪽은 Intra, 다른 쪽은 Inter 혹은 둘 다 Inter 모드를 사용하여 예측한다
- SGPM
- 기존에서 둘 다 Inter 모드를 사용하는 방식도 추가된 것이다
- 블록을 어떻게 쪼갤지, 쪼갠 블록에서 한 쪽은 어떤 모드를 사용했고, 다른 한 쪽은 어떤 모드를 사용했는지 총 3가지의 정보를 list로 만들어둔다. SGPM candidate list라고 한다
- 총 16개의 list를 만들어 둔다
Extended Multiple Reference LIne (MRL) list
- 기존 VVC의 MRL
- 0, 1, 3의 멀티플 라인을 사용하여 예측의 정확도를 높였다
- ECM의 MRL
- 3개가 추가된 { 0, 1, 3, 5, 7, 12}를 사용할 수 있다
Template-based multiple reference line intra prediction
- TIMD와 유사하게 Reference line 5개를 사용한다
- { 1, 3, 5, 7, 12}
- MPM의 10개 intra과 5개의 Reference line을 조합하여 50가지의 경우의 수를 만들어낼 수 있다
- 50가지의 경우의 수를 이용해 Template를 예측하여 가장 정확도가 높은 20가지를 경우를 추린 후 저장한다
- 20가지 중에서 어떤 경우를 사용했는지를 보내서 예측을 수행한다
Multi-model LM (MMLM)
- VVC의 CCLM
- 주변 샘플을 작은 값의 그룹과 큰 값의 그룹을 나누어 각각의 중간 값을 만들어서 두 중간 값으로 직선의 방정식을 만들었다
- MMLM
- 주변 샘플을 작은 값의 그룹과 큰 값의 그룹을 나누는 것까지는 기존과 같다
- 작은 값 그룹과 큰 값 그룹 각각에서 직선의 방정식을 만들어 내서 α, β 값을 계산한다
Convolutoinal cross-component intra prediction model (CCCM)
- VVC의 CCLM
- chroma의 주변 샘플과 Luma의 주변 샘플과의 관계성을 가지고 α, β 값을 계산한다
- CCCM
- 아래 식처럼 7개의 값으로 chroma의 주변 샘플과 Luma의 주변 샘플과의 상관관계를 더 정확히 찾아내서 , β 값을 계산한다

Primary and secondary MPM
- VVC의 MPM은 6개의 entries를 가지지만 ECM의 MPM은 22개의 entries를 가지게 된다
- ECM MPM 중 6개는 기존 VVC MPM과 같은 방법으로 찾아내고 나머지 16개는 DIMD로 만들어내게 된다
- 즉, Primary MPM list 6개와 Secondary MPM list 16개를 활용하여 사용한다
출처 및 참조
- MPEG뉴미디어포럼/한국방송∙미디어공학회 2023 Summer School
- 최해철, VM Laboratory, 한밭대학교

공부 기록