Object Detection
- 입력 이미지 내의 객체가 무엇인지 판별하고 해당 객체를 Bounding Box로 감싸는 것
- Object Detection에서 좋은 알고리즘이란 검출률과 정확도를 동시에 고려해야 함
Precision과 Recall
- Precision(정밀도) : 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율
- Recall : 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율
- 모델의 분류와 정답
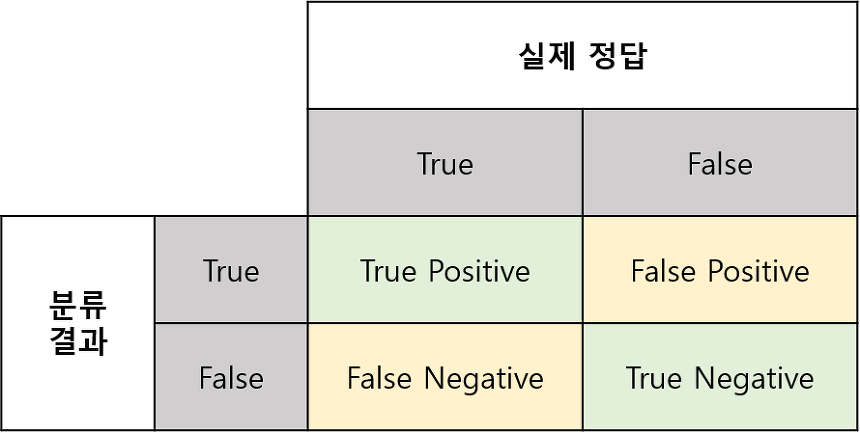
- True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)
- False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)
- False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)
- True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답)
- 일반적으로 Precision이 높아지면 Recall이 낮아지고, Recall이 높아지면 Precision이 낮아지는 반비례 관계이다. Precision과 Recall의 평균이 가장 높아지는 confidences 값을 찾아야 한다
mAP
- mAP(Mean Average Precision)는 각각의 클래스에 대한 Average Precision의 평균으로 Confidences 값의 변화에 따라서 변화하는 Precision과 Recall의 변화 그래프를 PR curve라 하며 가장 대중적으로 많이 사용되면 Object Detection의 평가지표이나 직관적인 수치가 없으므로 수치화하여 사용한다
R-CNN
- Input image, Extract region proposals (~2k)
- Hypothesize Bounding Boxes(Proposals)
- Image로 부터 Object가 존재할 적절한 위치에 Bounding Box Proposal(Selective Search)
- 2000 개의 Proposal이 생성됨
- Hypothesize Bounding Boxes(Proposals)
- Compute CNN features
- Resampling pixels / features for each boxes
- 모든 Proposal을 Crop 후 동일한 크기로 만듦(224 224 3)
- Resampling pixels / features for each boxes
- Classify regions, Bounding Box Regressor
- Classifier / Bounding Box Regressor
- 위의 영상을 Classifier와 Bounding Box Regressor로 처리
- Classifier / Bounding Box Regressor
- 하지만 모든 Proposal에 대해 CNN을 거쳐야 하므로 연산량이 매우 많은 단점이 존재
Fast R-CNN
- Fast R-CNN은 모든 Proposal이 네트워크를 거쳐야 하는 R-CNN의 병목(Bottleneck) 구조의 단점을 개선하고자 제안된 방식
- 가장 큰 차이점은 각, Proposal들이 CNN을 거치는것이 아니라 전체 이미지에 대해 CNN을 한 번 거친 후 출력된 특징 맵(Feature Map)단에서 객체 탐지를 수행
- 입력 이미지의 영역을 2000개로 나누어 2000개의 crop된 이미지를 resize하여 CNN에 들어가고, Crop된 region에 객체가 있는지 ConvNet이 판단
Faster RCNN
- 입력 이미지를 Crop하여 여러 번 ConvNet에 입력하면 연산량이 비효율적이므로 feature map에서 region proposal하여 한 번에 Object Detection을 수행
1 Stage vs 2 Stage
- 1 Stage : Regional Proposal와 Classification이 동시에 이루어짐
- Input Image -> Feature Extraction -> Feature Maps -> Output
- 2 Stage : Regional Proposal와 Classification이 순차적으로 이루어짐
- Input Image -> Selective Search, Region Proposal Network, etc -> Output
YOLO
- 입력 이미지를 SxS grid로 나누어 각 Bounding Boxes와 class가 있을 확률을 예측
- Fast, Faster RCNN보다 FPS는 높지만 성능(mAP)는 떨어짐. 또한 입력 이미지를 SxS grid로 나눔으로써 작은 객체를 상대적으로 못 찾음
Single Shot MultiBox Detector(SSD)
- SSD는 Faster RCNN과 YOLO가 결합된 형태로 단계적인 feature map에서 region proposal network없이 곧 바로 bouding box와 class를 예측
- Feature map 크기가 작으면 작을수록 큰 Object를 잘 잡고, Feature map의 크기가 크지만 작은 Object르 잘 찾음. 중복되는 객체는 Non Maximum Suppression(NMS)을 통하여 제거
Pascal VOC 데이터 셋
- 10000장의 이미지로 구성되어 있으며, Bounding Box GT와 Bounding Box 내부 클래스의 카테고리 정답이있음. 이미지의 양이 매우 적기 때문에 테스트용 데이터셋으로 많이 사용됨
최신트랜드
- 현재는 CNNs based architecture search로 찾아낸 EfficientDet(SSD계열)과 YOLO계열이 state-of-art를 달성하고 있다

공부 기록