
- 오늘은 신경망을 구성할 때 학습 안정성을 높이기 위해 사용하는 정규화, 그 중에서도 가장 많이 사용하는
레이어 정규화와배치 정규화에 대해서 알아보자!
정규화
-
정규화란, 데이터의 피처 또는 데이터 샘플 간 스케일 차이로 인해 발생하는 불안정성을 방지하기 위해 적용하는 방법
- z-score 정규화, 최대-최소 정규화 등
-
일반적으로 신경망을 구성할 때는
배치 정규화와레이어 정규화를 사용 -
아래 그림은 두 정규화 방법을 시각적으로 보여준다.
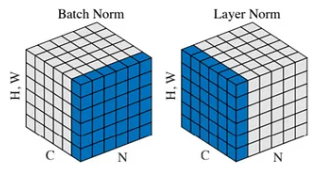 출처: https://medium.com/@zljdanceholic/groupnorm-then-batchnorm-instancenorm-layernorm-e2b2a1d350a0
출처: https://medium.com/@zljdanceholic/groupnorm-then-batchnorm-instancenorm-layernorm-e2b2a1d350a0
Layer Normalization(LN)
-
한 개 데이터 샘플에 대해 정규화를 적용
- 평균 0, 분산 1로 정규화
-
예를 들어, SBERT 모델을 사용하여 768차원의 문장 임배딩을 얻었다면 768개의 feature를 사용하여 하나의 샘플내에서 정규화를 적용한다.
-
또한, 하나의 샘플의 모든 피처를 사용하기 때문에
배치 크기에 독립적이다.- 배치 크기에 독립적인 특성은 배치 크기가 매우 작을 때도 안정적으로 동작
- 따라서 transformer처럼 깊은 신경망 구조(= 모델 크기 커짐 = 메모리 제약으로 배치 크기 제한)를 갖는 모델에서 자유로운 배치 크기,
내부 공변량 변화를 방지하기 위해 사용한다.
Batch Normalization(BN)
-
데이터를 배치 단위로 구성하여 학습 시, 이 과정에서 데이터의 분포를 유지하고 안정성 확보, 학습 속도 향상을 위해 사용
-
Dropout의 대안으로도 사용- 배치를 구성하는 데이터 샘플마다 평균, 분산이 달라지고, 이는 작은 노이즈를 주입하는 것과 유사한 효과
- 이 노이즈는 은닉 뉴런 간의 의존성을 약화시키는데, 이것이 드롭아웃의 효과와 유사
-
보통 활성화 함수 통과하기 이전에 사용
Vanishing gradient 방지
-
LN과 마찬가지로 내부 공변량 변화 방지로 학습 안정성 증가
-
더 높은 학습률을 적용할 수 있어, 학습 속도 향상 가능
단점
-
배치 크기에 의존적
- 배치 크기에 따라 불안정해질 수 있어, 학습 성능에 직접적인 영향
-
시퀀스를 다루는 모델(RNN, Transformer)에서 계산 축(axis)의 영향을 받음
- 각 time step마다 통계치가 무시될 수 있음
- ex) 피처가 주식의 '종가'인 경우
-
다른 샘플의 영향을 받기 때문에 각 샘플을 독립적으로 다뤄야 하는 생성 모델에서 아티팩트(Artifact) 유발 가능
BN, LN 특징 정리
| 특징 | Batch_Norm | Layer_Norm |
|---|---|---|
| 정규화 단위 | 배치 내 각 피처 | 샘플 내 모든 피처 |
| 배치 크기 | 배치 크기에 의존적 | 배치 크기에 독립적 |
| 적합 모델 | CNN, 큰 배치 | 시계열 모델, 작은 배치, 생성모델 |
- BN, LN 시각화
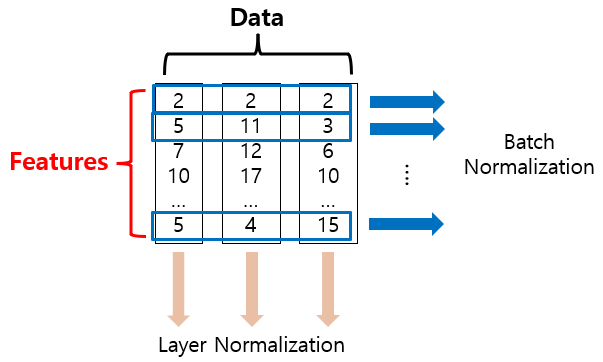
추가 반영 내용
-
BN은 테스트 시 학습 과정의 통계량을 사용(이동 평균/분산)
-
LN은 테스트 시에도 동일하게 데이터 별 통계량 사용
-
내부 공변량 변화- 뉴럴 네트워크 학습 과정에서 발생하는 불안정성의 주요 원인
- 학습 과정에서 레이어의 가중치가 바뀌면 다음 레이어에 입력되는 데이터의 분포가 지속적으로 변화하여 매 배치마다 새로운 분포를 학습해야하는 단점
정리
-
배치 크기나 모델 크기로 인한 메모리 제약을 고려해야 한다면 명확하게 어떤 방법이 효율적인지 명확하지만
-
제약이 없다면 반드시 데이터 특성을 파악한 후 사용해야 데이터 별 통계량이 무시되지 않으니 학습 안정성 or 성능 기준으로 파악해야할 필요가 있다.
