LDA와 같은 모델을 PTM, BERT,DistilBERT와 같은 모델을 사용한 방식은 PLM이라 명칭
(사용한 데이터셋은 IMDB, 20newsgroups dataset사용)
논문명
--> Topics in Contextualised Attention Embeddings.
(PLM은 어떻게 벡터만으로 latent topic을 찾아내고 그 토픽을 구하는 word들이 어떻게 자동으로 형성이 되는 지에 대한 궁금증으로부터 기존 PTM과 성능 비교)
BERT와 DistilBERT의 임베딩 벡터를 token별로 구하여서
1. 클러스터별 coherence를 구하고
2. GMM 알고리즘을 이용하여 클러스터링을 통해 NTMs( LDA 또는 NMF)와 클러스터 별로 token이 얼마나 overlap되는 지 수치로 나타냄
1. PLM의 대표 유형인 BERT는 embedding_vector를 생성할 수 있는데, 최대 길이 (max_length)가 지정되어 있고 max_length를 넘어서면 넘어선 내용들은 누락(omitted)되는 단점이 존재. 하지만, BoW(bags of words)를 사용하는 기존의 토픽 모델링 보단 coherence에서 더 좋은 수치를 보임
(논문에서 사용한 데이터셋에서)
2. BERT는 총 12개의 layer, DistilBERT는 총 6개의 layer로 구성 (각 layer 별로 embedding_vector를 따로 추출하여 coherence를 계산)
(그림 1-1 , 1-2, 1-3 참고)
2-(1).
2번 섹션에서 언급한 각 layer마다 다른 embedding_vector를 얻을 수 있다고 언급했는데
Topic Modeling with Contextualized Word Representation Clusters
(해당 부분은 위 논문에서 확인 가능) 어느 layer의 결과 벡터를 사용하냐에 따라 metrics에 유의한 영향를 끼쳤다는 결과 도출
그림 1-1 (LDA, NMF의 coherence 결과)
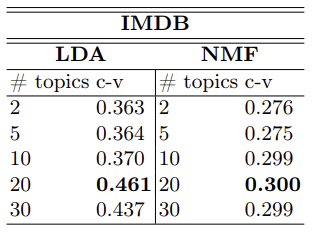
그림 1-2 (BERT의 각 layer별 임베딩 벡터 사용 결과)
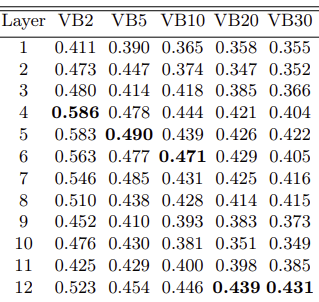
그림 1-3 (DistilBERT의 각 layer별 임베딩 벡터 사용 결과)
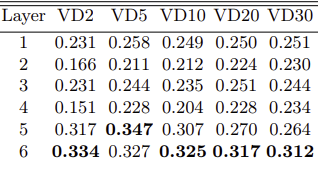
* PLM의 layer별 c-v가 기존 PTM보다 대부분 좋음을 알 수 있음
다른 layer를 사용한 이유는 아래와 같은 문제 발생하기 때문
anisotropy 문제
anisotropy 문제는 embedding_vector로 input에 대해 표현을 할 때,
위 그림 2와 같이 vembedding_vector가고르게 표현되지 못하고
embedding_space에 협소하게 표현되어 새로운 데이터가 입력 됐을 때,
의미를 잘 표현하지 못하는 문제를 의미
해결 방법으로는
1.
SimCSE: Simple Contrastive Learning of Sentence Embeddings!language model input
위 논문에서 언급한 contrastive learning을 통해 isotropy하게 만드는 것
(contrastive learning은 다음에 다룰 예쩡입니다)
2.
최종 final layer의 이전 layer에서 embedding_vector를 갖고 옵니다.
Topic Modeling with Contextualized Word Representation Clusters
위 논문에서 BERT, GPT-2, RoBERTa 세 모델을 사용하여 다른 토픽 수와 이전 layer
또는 2개 이전의 layer에 따라 표현된 embedding_vector를 사용하여 결과를 비교 (그림 3)
아래와 같은 결과를 보임
->
(RoBerta를 제외한 BERT, GPT-2 (final layer, 그 이전 또는 더 이전 layer 이용)의
word level embedding은 LDA와 같은 토픽 모델링의 결과와 비슷 or 더 좋은 결과)
(L[-1] = fianl_layer, L[-2] = 이전 layer, L[-3] = 2개 이전 layer)그림 2
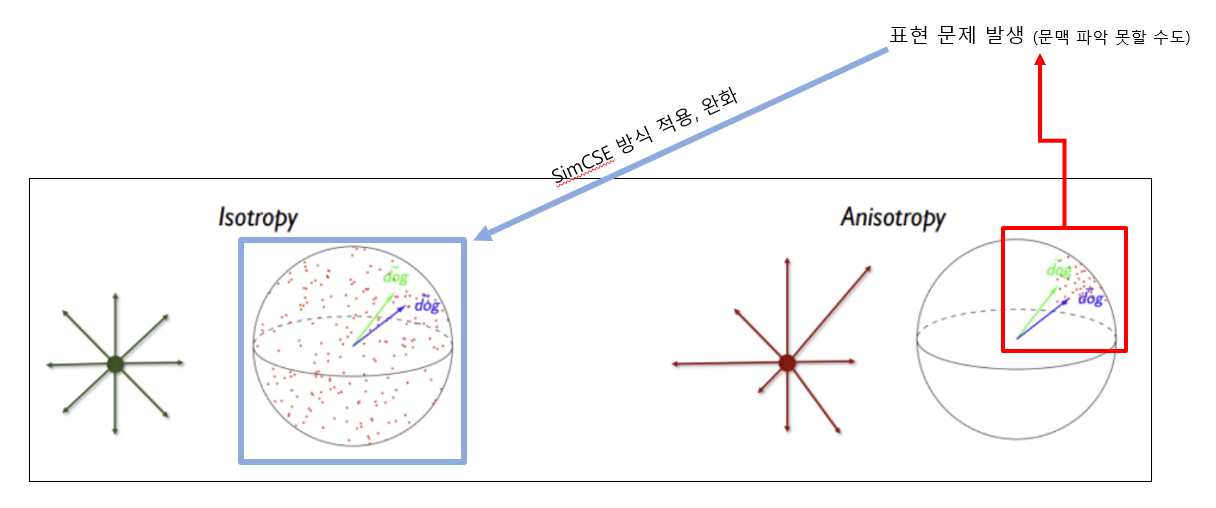
그림 3
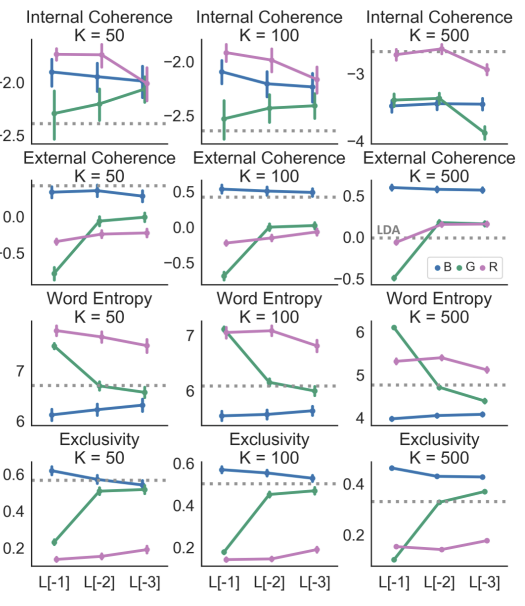
(L[-1] = fianl_layer, L[-2] = 이전 layer, L[-3] = 2개 이전 layer)
3. LDA와의 클러스터별 word overlap비교
그림 4
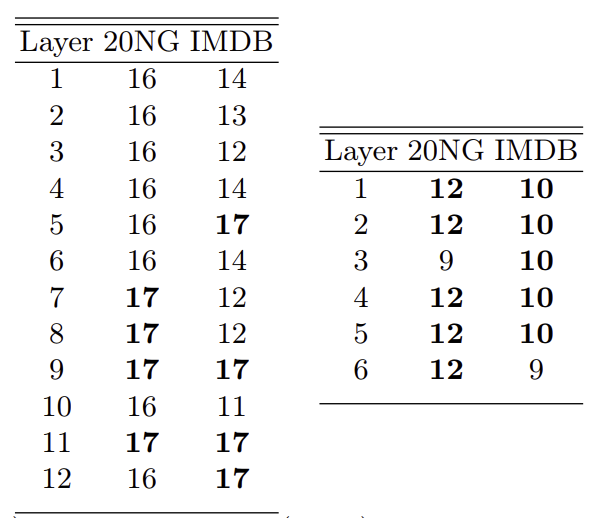
하나의 cluster 당 top 20개의 words를 LDA와 비교하여
BERT(왼쪽), DistilBERT(오른쪽)의 overlap 결과를 보임

Data Science
오 좋은 내용 감사합니다 😄👍