
최근, 기술의 발전과 함께 더불어 빅데이터라는 개념이 생겼다.
다양한 형태의 데이터 중, 텍스트 데이터를 처리하는 방식에도 많은 기법이 등장했는데 현재 많이 사용하는 PLM도 텍스트 처리 기법 중 하나이다.
이전에 말했듯이, 다양한 text data가 생겨나고 이데 따라 분석 방법이 나오면서 topic modeling이라는 기술이 등장하였다
토픽 모델링이란, 각 단어들이 특정 토픽에 포함될 확률을 파악하여 문서의 주제를 파악하는 통계적 기법이다. (대표적으로 LDA와 LDA에서 파생된 모델, 그리고 행렬을 이용한 NMF방식이 있다)
즉, 쉽게 말해 크기가 큰 텍스트 데이터에서 insight(여기선 주제)를 발견하기 위해 사용하는 기법이다.
PTM(pre-trained topic modeling) 방식도 많이 쓰이지만, 불과 10년도 채 안 된 시점에 PLM(pre-trained language model)라는 개념이 등장했다.
language model은 대표적으로 GPT, BERT, XLNet 등이 있다.
오늘 알아보려 하는 건 PTM 혹은 PLM과 같은 방법에서 얻은 토픽의 coherence(일관성)을 측정하는 방법 중 하나인 NPMI에 대해 알아보고자 한다.
(일관성의 의미는 모델이 생성하는 토픽이 실제로 의미 있고 해석 가능성을 평가)
(이후 포스팅에서 topic diversity, topic quality 등 지표도 정리할 예정)
NPMI
--> NPMI normalized pointwise mutual information의 약자로, UCI (University of California, Irvine)에서 사용한 지표이다.
기존에 존재하는 PMI 지표를 [-1,1]의 범위로 정규화한 지표이다.
우선 PMI에 대해 알아보면, 아래와 같은 형식이다
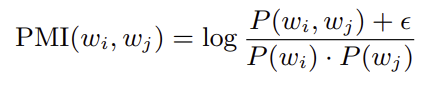
(분모 뒤에 추가로 붙인 항은 logarithm of zero 피하기 위해!)
x,y를 단어라고 했을 때,
p(x,y) -> x,y가 말뭉치에 같이 등장할 확률
p(x), p(y) -> 각 단어가 말뭉치 등장할 확률
만약, PMI(x,y)의 값이 높다면 x,y가 관련 O
PMI를 단어 등장 횟수로 다음과 같이 변형시킬 수 있다.
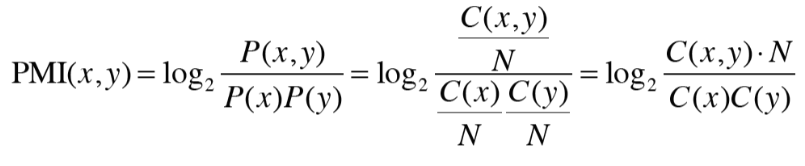
C(x) -> 말뭉치에서 단어 x가 등장하는 횟수
C(y) -> 말뭉치에서 단어 y가 등장하는 횟수
C(x,y) -> 단어 x,y가 말뭉치에서 동시에 등장할 횟수
--> PMI 역시 토픽 모델링의 결과 (토픽 or 클러스터)의 평가지표로 쓰임.
(토픽 내 모든 단어로 할 수도 있고, 토픽 내 단어의 개수가 너무 크다면 논문마다 다르게 선정한 상위 n개의 단어에 대해서만 계산할 수도 있다)
PMI를 알아봤으니 다시 NPMI에 대해 알아보자
NPMI는 PMI를 정규화한 형태이다
(정규화를 하는 이유는 PMI가 +/-무한대로 발산할 수 있기 때문에 정규화 진행)
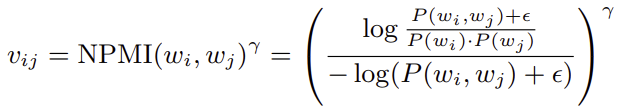
-log(p(w_i,w_j) + e)로 정규화하는 이유는, p(w_i,w_j)의 값은 최솟값이라는 가정을 하자.
log 함수이기 때문에 x축 대칭 (y = -y 대입)해주면 p(w_i,w_j) 확률이 가장 작을 때,
-log(p(w_i,w_j))의 값은 최대값이 되기에 어떤 값이 분자에 나오든 결과는 -1과 +1 범위를 벗어날 수 없다. (Exploring the Space of Topic Coherence Measures)
위 논문에선 단어 i와j의 NPMI를 사용하여 구하는데, UCI coherence를 정리
-> UCI coherence

예를들어 단어 구성이 (1:'game', 2:'sport', 3:'ball', 4:'team')과 같이 구성되어 있을 때, 아래와 같이 계산 된다
@@ (번호는 설명 위해 임의로 붙인 번호, 실제는 없음)
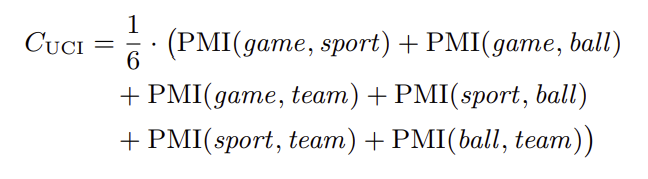
(쉽게 생각해서 이중 for문 구조와 같이 구함)
(1,2), (1,3), (1,4), (2,3), (2,4), (3,4)의 조합으로 구성 된다.
만약, 토픽(=클러스터)을 구했을 때 토픽 별로 상위 10개 단어를 사용한다고 하면, 총 45개의 단어 조합을 통해 UCI coherence를 산출할 수 있고, 결과를 토픽 산출의 성능 지표로 사용 가능하다.
이러한 방식으로 결과 토픽이 좋은 결과를 도출 했는 지 보정이 필요한 결과인 지 판단의 척도로 사용할 수 있다!
이외도 diversity, quality 나아가서는 토픽의 stability를 측정할 수 있는 여러 지표가 있고, 추후에 포스팅 하도록 하겠습니다!

Data Scientist & Data Analyst
유익한 정보 공유해주셔서 감사해요👍👍👍