

이전에 위 링크에서 NLP 논문에 대한 리뷰를 하였다.
단하게 복기하면 기존 토픽 모델링에 많이 쓰이고 있는 LDA와 NMF (통칭 PTM) BERT 등장 이후 많이 사용하고 있는 PLM을 토픽 클러스터 별 coherence로 비교하는 논문
한 가지 특이한 점이 있다면 Distilbert기준 6개의 layer로 이루어져 있는데, 각 layer마다 다른 embedding vector를 생성할 수 있다는 점이다.
논문도 이 점에 기인하여 layer별 embedding vector를 생성하여 비교!
(BERT는 12개의 layer로 구성되어 있으니 참고!)
이제 간단히 살펴 봤으니 구현한 코드에 대해서 설명하고자 한다.
(오늘 포스팅에서는 layer별 임베딩 벡터 생성한 코드에 대해서만 설명)
논문에서 imdb와 20newsgroup 데이터셋을 모두 사용
해당 포스팅에선 imdb 데이터로만 진행(데이터 샘플링 해서 사용)
코드 구현
1. Embedding vector 생성 코드
1) 데이터 생성
from tensorflow.keras.datasets import imdb
(x_tr, y_tr), (x_tst, y_tst) = imdb.load_data()
df1=pd.DataFrame(x_tr)
df1.rename(columns={0:'text'},inplace=True)
df2=pd.DataFrame(x_tst)
df2.rename(columns={0:'text'},inplace=True)
new_imdb_df=pd.concat([df1,df2],axis=0,ignore_index=True)
- 코드를 실행하여 new_imdb_df를 확인!
(긍정 리뷰 25000개, 부정리뷰 25000개로 구성)

-
위와 같이 단어가 index 형태로 저장되어 있음을 알 수 있다.
-
이미 기존 텍스트가 word_to_idx 형태로 저장 되어 있기 때문에
이를 idx_to_word로 변환하는 작업을 거친다
2) index_to_word
word_to_index = imdb.get_word_index()
index_to_word = {}
for key, value in word_to_index.items():
index_to_word[value+3] = key
def trans_txt(data):
result = []
for index, token in enumerate(("<pad>", "<sos>", "<unk>")):
index_to_word[index] = token
result =' '.join([index_to_word[index] for index in data])
return result-
딕셔너리 형태로 index_to_word에서 index에 해당하는 word를 저장
-
특히 index_to_word[value+3]의 경우 +3을 해주는 건 pad, sos ,unk와 같은 특별 토큰을 넣기 위해!
-
특정 위치에 pad - 패딩 / sos - 문자의 시작 / unk - 알 수 없는 단어를 index_to_word에 추가한 뒤, result에 최종 단어를 저장한다.

잘 변환 된 것을 볼 수 있다.
3) layer 별 임베딩 벡터 생성 코드
import torch
import copy
import re
import nltk
import string
from transformers import DistilBertTokenizer, DistilBertModel,DistilBertConfig
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased',output_hidden_states =True)
translator = str.maketrans('', '', string.punctuation)
stopwords = nltk.corpus.stopwords.words('english')
def preprocess_n_layer(text,idx):
my_text = copy.copy(text.translate(translator))
my_text = my_text.replace('\n', '')
p = re.compile(r'<br\s*/?>|[^A-Za-z]')
my_text = p.sub(' ', my_text)
embeddings_list = []
tokens = tokenizer(my_text, truncation = True,
return_tensors= 'pt',
add_special_tokens = True,
max_length=512)
tokens_no_stopwords = [token for token in tokens['input_ids'][0]
if tokenizer.convert_ids_to_tokens(token.item()) not in stopwords]
논문에서 preprocessing 과정이 명확하게 나오진 않았고 간단한 불용어, 구두점 제거만 하였다고 해서 비슷하게 진행
(오늘 포스팅에선 긍정리뷰 50개, 부정리뷰 50개만 사용하여 적용)
-
우선 transformer에서 DistilBERT기반 모델과 토크나이저 import
-
모델과 토크나이저는 DistilBERT.pre_trained를 사용
(여기서 중요한 건 각 layer에서 뽑기 위해 ouput_hidden_state = True로 설정) -
translator와 stopwords를 생성하여 텍스트 데이터 내에 있는 구두점, 불용어를 제거할 수 있도록 미리 생성
-
정규식으로 불필요한 요소들 제거하고 대소문자 영어만 남김
-
미리 호출한 토크나이저를 활용하여
(토큰의) 최대 길이 = 512,
최대 길이보다 길면 나머지는 버리는 truncation = True -
return_tensor, add_special_token은 목적에 따라 다르게 할 수 있기 때문에 추가설명!
1) 위 토크나이저는 실행하면 토큰의 ID를 반환한다 여기서 반환 되는 토큰ID의 데이터 타입을 지정하는 역할 - 여기선 ptorch tensor
2) add_special_token은 [CLS], [SEP] 토큰을 뜻한다.
[CLS] - 문장의 전반적인 내용을 담고 있는 토큰 ( text classification에 사용)
[SEP] - 문장 끝에 오는 토큰(필요에 따라 사용하면 된다)
- 토크나이저 한 뒤, tokenizer.convert_ids_to_tokens(token.item())를 이용해 불용어와 같은 토큰이 있다면 제거!
ex)
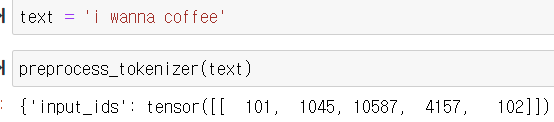
토큰ID 101 -CLS, 102- SEP를 의미 add_special_token =False 하면 101,102 없음
4) 각 layer별 결과 도출 (이전과 이어서 preprocess_n_layer 안에 구현된 코드)
with torch.no_grad():
outputs = model(input_ids=torch.LongTensor(tokens_no_stopwords).unsqueeze(0))
hidden_states = outputs.hidden_states
layer_embedding = hidden_states[idx]
embeddings_list.append(layer_embedding)
return embeddings_list-
graduent를 계산할 필요 없기 때문에 torch.no_grad()지정
-
입력 형태를 맞춰주기 위해 unsqueeze(0)로 dim = 0을 생성
-
원래 최종 layer의 embedding vector만 얻고 싶으면,
hidden_states = outputs.last_hidden_states를 지정하면 된다.
하지만 나는 per layer의 결과를 얻고 싶기에 위와 같이 코드 작성
2. 각 layer별 결과 생성
- 각 layer의 모든 결과는 마지막에! 코드는 layer6만
new_imdb_df['embed'] = 0
new_imdb_df['embed'] = imdb_df['new_txt'].apply(lambda x: preprocess_n_layer(x,5))
embedding_tensor = []
for i in range(len(new_imdb_df)):
tensor_2d = new_imdb_df['embed'][i][0].view(-1, 768)
embedding_vectors = tensor_2d.numpy()
embedding_tensor.append(embedding_vectors)
split_embeddings = [emb for emb in embedding_tensor]
stacked_embeddings = np.vstack(split_embeddings)
layer_6_df = pd.DataFrame(stacked_embeddings)- 이 코드는 결과를 데이터 프레임으로 embedding vector가 데이터프레임 형태로 저장하는 코드
결과 (layer6)

결과2 (layer1)

결과 3 (layer4)

- 13084 = 총 토큰의 개수
추가!
- layer6의 결과와 layer1, layer4의 결과가 좀 다른데
메모리 효율과 연산 시간을 위해 자리 수를 아래 코드 통해 소수점 3자리 까지만 표현
(논문의 coherence 결과도 소수점 3자리 까지여서 자름)
def num_round(df):
new_df = pd.DataFrame(np.round(df.values,3))
return new_df
-
메모리 비교
layer4(100txt).csv는 num_round 적용 안 한 df의 csv파일
layer4(100txt_2).csv는 num_round 적용한 df의 csv파일 -
첫 번째 파일은 112MB, 두 번째 파일은 64.3MB로 꽤나 줄었다는 걸 확인할 수 있다.
