
- 오늘은 자연어 생성(NLG)에서 fine tuning 방법의 대안으로 사용하는 prefix tuning가 무엇인지? 그리고 어떻게 적용하는지?에 대해 알아보고자 한다.
참고 논문: Prefix-Tuning: Optimizing Continuous Prompts for Generation.
| Li et al(2021)
Prefix Tuning
-
등장 배경
-
자연어 생성(NLG)는 context가 중요하지만 항상 명확한 context를 알 수 없다.
-
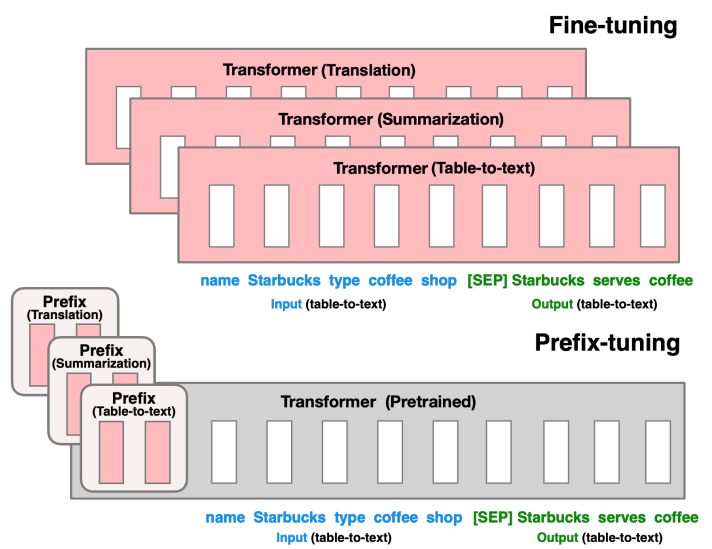
또한 대부분의 사전학습 LM은 위 그림처럼 Table-to-Text에서 "Summarize following table in one sentece"와 같은 지시사항을 대부분 해결하지 못함
-
이는 Data-driven Optimization을 사용해야하지만, 사실상 프롬프트를 일일히 변경하는discrete optimization은 미분 기반의 최적화가 불가능하여 현실적으로 적용 어려움
-
-
이런 문제를 해결하기 위해 prefix 방법 사용
-
fine tuning은 모델 파라미터 전체를 학습시키지만 LLM 같은 매우 큰 모델을 학습하기에는 시간, 비용 소모 측면에서 비효율적
-
따라서 모델의 파라미터는 고정(frozen)하고 일부 가중치만 학습하는 tuning 방법에 대해 정리!
(일부 가중치 = small continuous task-spedcific vector = prefix) -
Lightweight fine-tuning이라고도 함
-
prefix는 continuous vector이기 때문에 미분 기반 최적화가 가능하다는 점과 이를 통해 context를 부여할 수 있다는 점에서 장점
-
-
Fine tuning과 Prefix tuning
- P_θ 특징과 Reparameterize
-
prefix는 학습 가능한 파라미터(P_θ = P_idx x dim(h_i))
-
P_θ는 학습률과 초기화 방법에 매우 민감하여 다층 퍼셉트론(MLP) 사용하여
reparameterize적용 -
reparameterize 과정은 아래와 같다. (MLP는 k차원의 행렬을 dim 크기로 매핑 역할)
k = 512(for Text Generation) OR 800(for Summarization)
-
따라서,
P'_θ 랜덤 초기화 -> MLP -> P_θ이고 여기서 P_θ가 prefix로 사용된다.
-
Prefix_length
그렇다면, prefix의 길이는 어떻게 정할까?
- 논문에선 아래와 같이 언급하였다.
->Generation에서0.1%를 prefix로 사용했을 때 fine tuning과 비슷한 성능,
->Summarization의 경우2%를 prefix로 사용했을 때 fine tuning보다 약간 낮은 성능
-
Reparameterize에 사용할 P'의 length를 정하기 위해 각 task에 맞는 prefix 비율과 모델의 전체 파라미터 개수를 기반으로 계산한다.
(예시 모델 - GPT-2 medium)- GPT-2 (medium) Num_layer 24 Embedding_dimension 1024 Parameter_size 345M
- 계산 과정
- 분모의 2는 key와 value에만 prefix가 추가되기 때문에 부여한 값
- Transformer의 Q, K, V의 역할에 대해 살펴보면
Q(질문) : 현재 처리 중인 토큰이 "내가 문맥 중 어떤 정보와 관련 있는가?"를 묻는 역할K(키) : 문맥 속 다른 토큰들이 "질문에 얼마나 관련 있는가?"를 나타내는 꼬리표 역할V(값) : 답변으로 추출될 정보
- 따라서,
원래 질문의 의도 해치지 않기 위해 Query는 prefix 사용 X
-
Task별 Prefix 길이
- Text Generation Text summarization Best_ratio 0.1% 2% Predfix_length 7.019 -> 7140.38 -> 140
- generation task는 K와 V 앞에 (7,1024)의 prefix가 추가,
- summurization task는 K와 V 앞에 (140,1024) prefix가 추가되어 어텐션 연산을 수행
Prefix 구현 예시
- 기존 어텐션 과정(attentiob)과 prefix tuning 시 (prefix_attention)
input_embed = torch.rand(128, 1024)
query_weight = torch.randn(1024,1024)
key_weight = torch.randn(1024,1024)
value_weight = torch.randn(1024,1024)
Q = input_embed @ query_weight # OR torch.matmul(input_embed, query_weight)
K = input_embed @ key_weight
V = input_embed @ value_weight
def attention(Query, Key, Value):
att_score = (Query @ Key.T) / torch.sqrt(torch.tensor(1024, dtype=torch.float))
att_prob = torch.softmax(att_score, dim = 1) @ Value
return att_score, att_prob
vanila_attention_score, vanila_attention_prob = attention(Q, K, V)
print("====================구분====================")
prior_prefix = torch.rand(3,512) # length = 3, k = 512로 설정
prefix_mlp = nn.Sequential(
nn.Linear(512,512),
nn.Tanh(),
nn.Linear(512,1024)
)
reparam_prefix = prefix_mlp(prior_prefix)
Q = input_embed @ query_weight # Q는 그대로
pf_K = torch.cat([reparam_prefix, input_embed @ key_weight], dim = 0)
pf_V = torch.cat([reparam_prefix, input_embed @ value_weight], dim = 0)
def prefix_attention(Query, pf_Key, pf_Value):
pf_att_score = (Query @ pf_Key.T) / torch.sqrt(torch.tensor(1024, dtype=torch.float))
pf_att_prob = torch.softmax(pf_att_score, dim = 1) @ pf_Value
return pf_att_score, pf_att_prob
pf_attention_score, pf_attention_prob = prefix_attention(Q, pf_K, pf_V)
- 현재 예시 코드에서는 단일 트랜스포머 블록에 적용하는 과정만 보였다.
- 하지만 실제로 적용할 때는 전체 레이어의 트랜스포머 block에 대해 초기화 해야하므로, shape으로 초기화를 진행하고 이후 split 과정을 거쳐 각 block의 K과 V에 concat한다.
- 사실 위 예시와 같이 직접 구현하려면 꽤 복잡하겠지만 감사하게도 peft 라이브러리로 구현되어 있어, 원하는 튜닝 방법을 사용할 수 있으니, 아래 링크 참고하면 된다.
정리
- 장점
- Fine tuning의 경우 데이터에 맞게 확실한 업데이트가 가능하지만 위에 언급한대로 데이터 규모, 모델 파라미터 규모 측면에서 소모되는 시간과 리소스가 상당하다.
- 그에 반해 prefix tuning은 기존 모델의 파라미터를 고정하고 prefix vector만 업데이트하면 성능 측면에서도 fine tuning만큼 기대할 수 있고 시간, 자원 측면에서도 절감할 수 있어, 소모되는 비용은 줄이고 성능을 챙기는 일거양득의 방법이다.
- Fine tuning의 경우 데이터에 맞게 확실한 업데이트가 가능하지만 위에 언급한대로 데이터 규모, 모델 파라미터 규모 측면에서 소모되는 시간과 리소스가 상당하다.
- 의문점
- 논문에서 초기화 방법, 학습률에 따라 prefix 파마티터가 매우 민감하다고 하였는데 P'_θ를 어떻게 초기화 했고 어떤 학습률을 사용했는지 그리고 사용한 MLP 구조가 없다는 게 아쉬움
- 또한 적용 task에 따라 prefix 비율이 달라지는데, 최적의 prefix를 탐색할 범위가 없어, 결과적으로 최적의 비율을 탐색 과정이 과연 리소스 측면에서 fine tuning보다 효율적일까?를 생각해볼 수 있을 것 같다.
(그렇지만, 로컬 등 VRAM이 한정적인 환경이라면 Prefix tuning이 유용할 것 같다.)
- 논문에서 초기화 방법, 학습률에 따라 prefix 파마티터가 매우 민감하다고 하였는데 P'_θ를 어떻게 초기화 했고 어떤 학습률을 사용했는지 그리고 사용한 MLP 구조가 없다는 게 아쉬움
