
- 오늘은 지난 Prefix Tuning에 이어, Prompt Tuning에 대해 알아보고자 한다.
- 참고 논문:
The Power of Scale for Parameter-Efficient Prompt Tuning
| Lester, B., Al-Rfou, R., & Constant, N. (2021)
Prompt Tuning
먼저, prompt tuning은 왜 필요할까?
-
기존에는 LLM을 사용하여 원하는 task에 맞춰 사용하기 위해 Prompt based adapation를 사용! 이는 LLM의 파라미터를 직접 업데이트 하지않고, 지시할 프롬프트를 조작하여 특정 downstream task에 적용시키는 방법 (ex - prompt design 또는 priming)
-
하지만, 오류 개선을 위해 사람이 개입해야 돼서 자동화, 확장성이 떨어지고, 모델에 입력할 수 있는 최대 토큰 개수가 제한되어 한계가 존재
(물론 최근 LLM은 매우 긴 토큰도 처리 가능하지만 어쨌든 길이 제한이 존재한다는 건 한계점!) -
프롬프트를 최적화하는 과정은 토른 선택 과정이 필요하여 직접 찾거나, 미분 불가능한 탐색. 즉, 탐색 알고리즘을 사용
-
즉, 이런 Hard Prompt는 설계도 여렵고 시간이 소요되는 단점이 존재
그래서 Prompt Tuning이란?
-
prompt tuning이란, PEFT(Parameter-Efficient Fine-Tuning) 중 하나로, Prefix tuning이 트랜스포머 블럭의 K와 V에 연결하는 벡터라면,
Prompt tuning은 input embedding에 연결하는 학습가능한 벡터이다. -
아래 그림은 파인튜닝 vs 프롬프트 튜닝의 차이를 보인다.
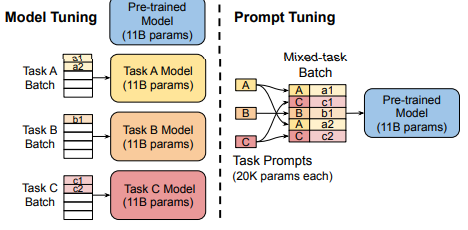
-
prompt tuning은
고정된 special token을 사용하는 것과 같고학습과정에서 이를 업데이트
생성 방법
1. 무작위 초기화(Random Initialization)
-> Uniform, Xavier 등 무작위 초기화
2. 어휘 초기화(Vocabulary initialization)
-> vocabulary 내 단어를 무작위로 선택하여 사용 (length에 맞게)
3. 클래스 초기화(Class initialization)
-> vocabulary 내 단어를 무작위로 선택 + 클래스 정보
-> 즉, 해당 문장의 클래스를 힌트로 제공하는 역할
비교 결과
- 아래 그림은 GPT에 prompt design을 사용한 결과와, 나머지는 T5를 fine tuning(T5, T5), prompt tuning(T5)을 사용한 결과이다.
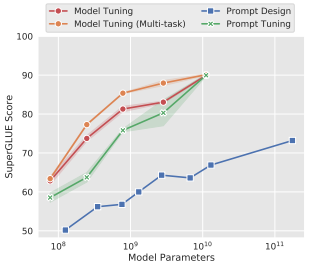
-> 모델의 크기가 커질수록, prompt tuning을 사용한 방법이 fine tuning을 사용한 방법과의 성능 격차가 줄고,
-> 기존 prompt design을 적용한 성능 대비 prompt tuning의 성능이 압도적으로 좋은 것으로 보아, 효율성과 성능 측면에서 모두 뛰어남을 보임
- 또한 prompt length와 초기화 방법에 따른 성능 차이는 아래와 같다.
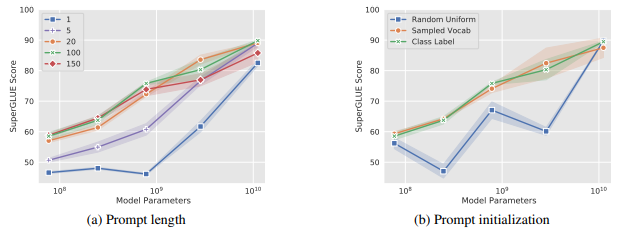
-> prompt length는 클수록 성능이 좋았고 (a)
-> 앞서 언급한 초기화 방법 중 랜덤 초기화를 적용한 결과는 성능이 모델 규모에 따라 들쑥날쑥하였고, vocab 기반 초기화, class 기반 초기화는 비슷한 성능을 보였다.(b)
정리
-
최근에는 모델 성능을 잘 내는것도 중요하지만
경량화에 초점을 맞춘 방법이 많이 나오고 있다. -
prompt tuning은 prefix와 달리 더욱 시간소모도 적고, MLP를 통한 reparameterize가 없다는 점에서 훨씬 간단하지만 데이터와 task에 의존적일 것 같아 리소스가 보다 제한적일 때 사용할만한 방법이라고 생각한다.
-
기존에 사용하는 PEFT를 사용한 방법을 결합하여 사용하면 보다 좋은 성능을 기대할 수 있을 것 같아, 적용 후 결과를 비교해도 좋을 것 같다.
