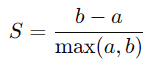
클러스터, 우리 말로 군집은 다양한 분야에서 사용되고 있다. 비슷한 데이터(유사한 데이터)를 하나의 클러스터에 묶음으로써 초기 데이터 형태에서 알 수 없던 insight를 얻을 수 있다는 장점이 있다.
클러스터링은 soft clustering이냐, hard clustering이냐에 따라 나뉘고 각 방식마다 알고리즘이 또 나눠진다.
하지만 오늘은 클러스터링 알고리즘이 아니라, 형성된 클러스터를 평가하는 평가지표 중 하나인 실루엣 계수에 대해 간단히 살펴보려고 한다.
※ 실루엣 계수(Silhouette Coefficient) ※
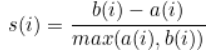 (i - Data Point)
(i - Data Point)
S(i): 실루엣 계수
b(i) : 클러스터 간 분리도
a(i) : 클러스터 내 응집도각 지표 계산 방법
- 각 지표 계산은 아래 그림을 예로 설명
ex)
 데이터 포인트 간 거리가 계산 되었을 때,
데이터 포인트 간 거리가 계산 되었을 때, a(i)
1.5+1.2+1.7+2.2) / 4 = 1.65 (거리의 평균)
(즉! 데이터 포인트 i가 속한 클러스터 X의 응집도를 의미)
b(i)
데이터 포인트 i와 cluster Y의 데이터 포인트들과 cluster Z의 데이터 포인트들과 거리를 산출했을 때, 평균 거리가 더 작은 값이 대입된다.
(즉! distance( i, Y) = 3.375 , distance( i, Z) = 6.25 이고,
b(i) = distance( i, Y) = 3.375가 된다.)
-
클러스터 내의 데이터가 얼마나 잘 모여있는 지 (응집도 - a(i) ),
클러스터 간 얼마나 분리되어 있는 지 (분리도, b(i) )를 확인하는 metrics -
실루엣 계수는 -1 ~ +1사이의 값으로 클러스터링 결과 성능을 평가
- S(i)가 1에 가까우면, 클러스터 내 잘 응집되어 있고, 클러스터 간 분리가 잘 되어있음을 의미
- S(i)가 0에 가까우면, 클러스터 내의 응집도도 좋지 않고 클러스터 간 분리도 잘 안 되어 있음을 의미
- S(i)가 -1에 가까우면, 클러스터 내의 데이터 포인트보다 다른 클러스터에 속한 데이터 포인트와 더 가까움을 의미
(이런 경우는 잘 못 됐거나 거의 없는 경우)
오늘 포스팅 끝!

Data Science