
오늘은 토픽 모델링 시, 프롬프트 엔지니어링을 사용하는 방법에 대해서 알아보려 한다.
토픽 모델링은 많은 텍스트 데이터에서 인사이트를 뽑아내는 역할을 한다.토픽 모델링 알고리즘으론 확률 기반의 LDA, 행렬분해 기반의 NMF 등 다양한 알고리즘이 사용되고 있다.
오늘은 그 중 BERTopic적용 이후 단계에 대해 조금 더 깊게 다뤄보려고 한다. (표현 모델, 프롬프트 엔지니어링)
우선 본문에 들어가기 앞서 간단히 BERTopic에 대해 정리하고 들어가자
BERTopic이란?
-
BERTopic은 이름 그대로 BERT기반의 임베딩을 이용하여 토픽을 찾아내는 기능을 한다. (물론 SBERT를 사용하지만, SBERT도 BERT기반으로 학습한 결과)
-
과정에 대해 간단하게 알아보자
-
우선 sentence-BERT를 사용하여 각 데이터(문서)를 동일한 차원의 벡터로 임베딩 생성
-
UMAP 알고리즘을 사용하여 생성한 임베딩 벡터 차원 축소
-
HDBSCAN (DBSCAN의 변형)을 사용하여 임베딩 벡터에 클러스터링 적용
-
class-based TF-IDF(일명 c TF-IDF)를 적용한다.
(쉽게 말해 기존의 TF-IDF를 하나의 클러스터(=토픽) 내에서 계산)
-
-
위 과정을 거치면 각 데이터가 어떤 토픽인 지 확인할 수 있음은 물론, 각 토픽을 대표하는 데이터(문서), 단어까지 알 수 있는 장점이 있다.
그렇다면... BERTopic을 통해 나온 결과를 어떻게 fine-tune 할 수 있을까?
결과적으로 representation model을 적용하고, 이후에 프롬프트 엔지니어링까지 적용할 수 있다.
Representation model
-
representation model은 보는 그대로 표현 모델이다. 즉, BERTopic의 토픽 결과를 다듬는 역할이라고 생각하면 된다.
-
트랜스포머 기반 모델, Spacy 기반 모델, MMR , KeyBERT 등등 여러 표현 모델을 사용할 수 있고 이 중 KeyBERT의 방법에 대해 알아보자
* KeyBERT
-
KeyBERT는 쉽게 말해 keywords,keyphrase를 만들어내는 bert 기반의 모델이다.
-
그림으로 대략적인 과정을 보자
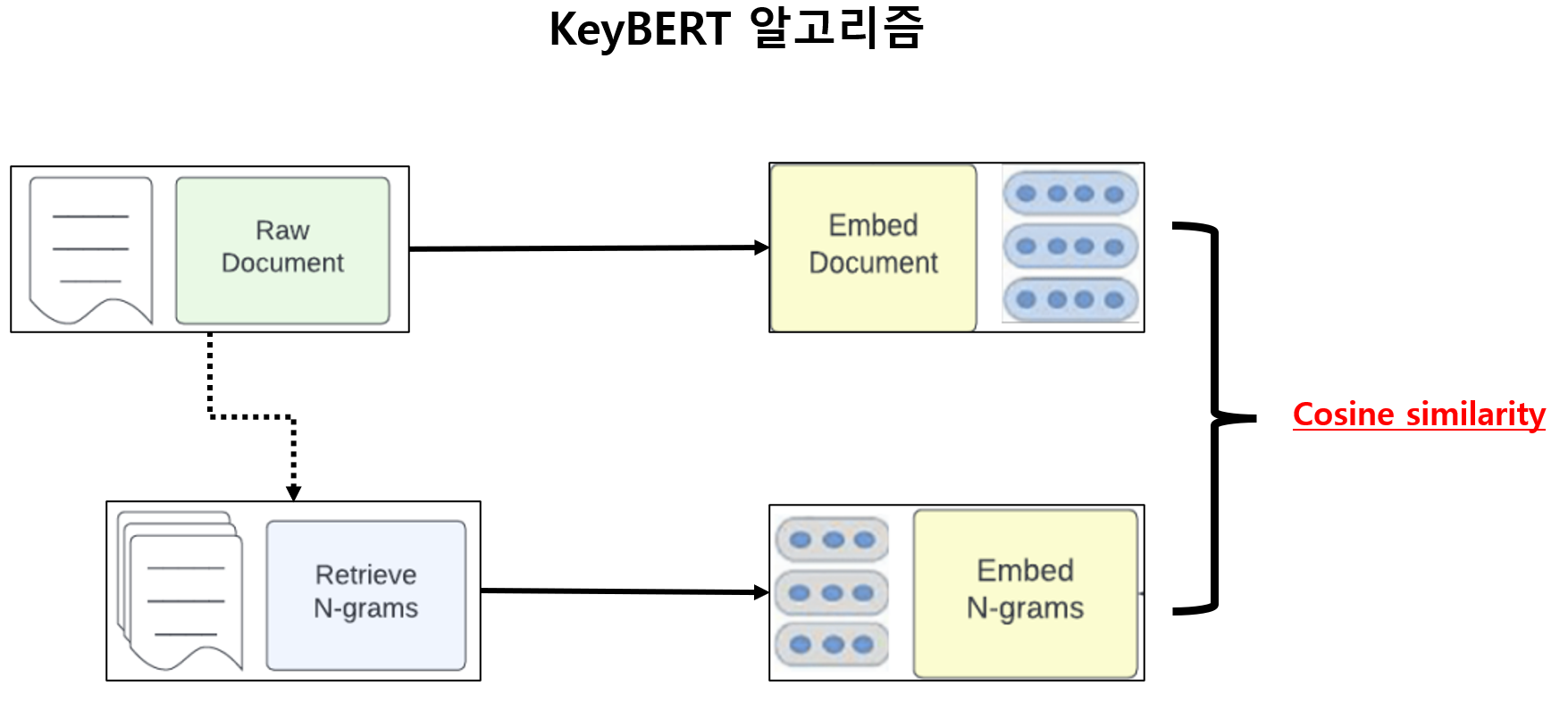
- document-level 임베딩 생성
- 문서를 n-gram을 사용하여 분할
- 생성된 n-gram을 임베딩으로 생성
- document의 임베딩과 n-gram의 임베딩을 유사도로 비교
- 유사도 기준 나열했을 때 상위 n개를 키워드/키프레이즈로 생성
- 아무런 전처리도 적용하지 않고, keyBERT를 표현 모델로 적용한 결과를 비교해보자 (오른쪽이 표현 모델로 KeyBERTInspired를 적용한 결과)
(단순 비교지만 표현 모댈 적용 결과가 더 의미 있는 걸 볼 수 있다.)
적절한 전처리를 동반하면 위 결과만으로도 충분히 좋은 분석이라고 할 수 있다.
하지만 오늘 알아보는 프롬프트 엔지니어링은 이 결과에 적용할 수 있다.
Prompt Engineering
-
프롬프트 엔지니어링이란?
어떤 모델에게 특정 task와 지시 사항을 부여하는 걸 말한다. 즉 원하는 작업을 요청, 원하는 결과를 얻는 일련의 task라고 보면 된다. -
큰 관점에서 프롬프트 엔지니어링은 아래 주의가 필요
(부가적인 설명은 따로 하지 않음)- 가능한 구체적이고 분명하게 프롬프트를 작성
- 복잡한 task인 경우, 질문을 세부적으로 나누어 점진적 진행 필요
- 할루시네이션 문제 주의
(프롬프트 엔지니어링은 별다른 개념은 없고 프롬프트를 어떻게 작성하는 지 가 키포인트!)
prompt engineering 적용
-
그렇다면 프롬프트에 넣을 데이터는 어떻게 구성할까?
input 데이터는 BERTopic + 표현 모델의 결과 중 Representative_Docs 사용
(이 데이터는 각 토픽을 대표하는 문서로, get_topic_info 메서드로 찾을 수 있다)데이터 전체를 사용하지 않고 굳이 토픽을 대표하는 데이터만 넣는 이유는 전체 데이터 사용 시 비용이 많이 발생하고, 생각보다 좋은 결과를 내지 못하는 점에서 비효율적이라고 할 수 있다.
-
프롬프트 작성 방법을 보도록 하자
(기본적인 system_message, use~, 등은 openai api에 자세하게 나와 있으니 참고 )
delimiter = '####'
system_message = "you are a helpful assistant. your task is to analyse my text data"
user_message = f'''
Below is a representative set of text data delimited with {delimiter}.
Please, identify the main topics mentioned in these comments.
Return a list of 3 topics.
Output is only a JSON list with the following format
[
{{"topic_name": "<topic1>", "topic_description": "<topic_description1>"}},
{{"topic_name": "<topic2>", "topic_description": "<topic_description2>"}},
{{"topic_name": "<topic3>", "topic_description": "<topic_description3>"}}
]
text_data:
{delimiter}
{delimiter.join(repr_docs)}
{delimiter}
'''
message = [
{'role':'system',
'content': system_message},
{'role':'user',
'content': f"{user_message}"},
]delimiter(구분자)를 통해 내가 넣을 데이터를 명시하는 게 중요하니 꼭 확인
이 코드는 '각 토픽의 대표문서를 넣을 건데 여기서 3개의 topic_name과 topic_description을 JSON 형태로 출력해줘' 이다.
- 프롬프트는 위와 같이 작성하고 이제 모델에 넣도록 하자
def get_model_response(messages,
model,
temperature = 0,
max_tokens = 1000):
# 특히 파라미터 중 temperature는 0~1사이 값으로 1에 가까울 수록 random한 결과가 나온다.만약 다양한 결과를 얻고 싶다면 큰 값으로, 고정된 결과를 얻고 싶다면 0으로 부여하면 된다.
response = openai.ChatCompletion.create(
model = model,
messages = messages,
temperature = temperature,
max_tokens = max_tokens
)
return response.choices[0].message['content']
topic_response = get_model_response(message,
model = 'gpt-3.5-turbo-16k',
temperature = 0,
max_tokens = 1000)
topic_list = json.loads(topic_response)
pd.DataFrame(topic_list)-
위 코드의 결과는 다음과 같이 볼 수 있다.
(예시를 위해 소량의 데이터로 진행한 결과이니 참고)

-
아후 모든 문서를 프롬프트에 넣고 각 토픽에 할당하면 모든 과정이 끝난다.
정리
-
프롬프트 엔지니어링을 토픽 모델링 결과에 적용하는 것은 해석이 쉽고 상세하게 조정이 가능하다는 장점이 있다. (단순하지만 토픽 모델링에서 이러한 장점은 아주 큰 장점이다)
-
하지만, 좋은 만큼 비용이 많이 들어간다는 단점이 있다.
gpt-3.5버전의 경우 비용이 상대적으로 덜 들어가지만 gpt-4의 경우,
약 전체 데이터가 3M개의 token이 있는 경우 90 USD가 필요하니 비용이 상당히 비싸다는 치명적인 단점이 있다.
끝으로, 공부 목적으로 쓴 글이다보니 틀린 부분이 있을 수 있습니다.
댓글로 알려주시면 감사하겠습니다 :)
