
- 오늘은 최근 NeurIPS에 게재된 논문에서 제안한
SpecEdge(스펙엣지)에 대해 알아보려 한다.참고 논문:
- Park, J., Cho, S., & Han, D. (2025). SpecEdge: Scalable Edge-Assisted Serving Framework for Interactive LLMs
SpecEdge
SpecEdge, 왜 사용할까?
- LLM을 사용할 때 거의 대부분이 외부 서버를 이용한다.
- 이용 과정에서 발생하는 비용, 자원은 상당히 큼
SpecEdge는
- 외부 서버 GPU 뿐만 아니라,
사용자 개인의 GPU(Edge GPU)도 같이 사용하여 비용을 낮추는 기술
Speculative Decoding
-
speculative decoding는 생성(generation)에 사용하는 방법으로,
추측적 디코딩이라고 하며 아래 세 단계로 구성된다. -
생성 task는 연산량이 크기 때문에 사용
⭐ Speculative Decoding
1️⃣
Drafting Candidates
- 작은 모델(Draft Model
ex) sLLM)이 생성한 결과. 즉, 서버가 아닌 사용자 개인 GPU와 sLLM을 사용하여 토큰 생성(=초안)- 단,
어휘 체계가 동일한 모델을 사용
- ex) 메인 모델(server 용) : Llama-3.1-70B / 서브 모델(Edge 용) : Llama-3.1-1B
2️⃣
Verification
- 메인 모델이 서브 모델의 생성 결과를 채점하는 것과 같고 이 과정에서
병렬 연산(Parallel Processing)을 사용- 만약 10개 토큰을 생성하면 메인 모델을 10번 사용해야 하지만, 미리 생성한 초안을 입력하면 한 번의 연산으로 검증이 가능하다.
-> 연산 효율성 및 비용 감소3️⃣
reconciliation
- 검증 결과를 통해 틀린 예측을 수정하는데, 처음 틀린 시점 이후의 단어는 올바르게 예측했어도 수정
- 10개 단어 중, 1~4번 정답, 5번 : 틀림, 6~10번 정답일 때 5번만 수정하는 게 아니라
해당 시점 단어 이후의 예측 결과가 맞았더라고 전부 수정(즉, 6~10번 단어가 맞았더라도 전부 수정)- 💡 메인 모델(server)가 오답을 수정하면, 엣지 모델은 정답으로 바꾸고
KV 캐시 다시 계산
SpecEdge의 특이점
- SpecEdge 비용 감소, 효율성 향상의 장점이 있지만, 사용하기에 아래 두 문제가 발생한다.
잠재적 지연시간 증가(Potential latency Increase)- 전통적인 Speculative Decoding은 초안 생성 -> 검증 단계가 순차적(Sequential)으로 진행되면, 서버가 검증할 때 엣지는 아무 것도 안 하게 되어 지연시간이 발생
과도한 서비 미사용(Risk of server underutilization)- 반대로 서버는 검증만 하기 떄문에 엣지가 초안을 생성할 때 계속 대기 상태라 효율 떨어지는 위험 발생
Potential latency Increase (Solutions)
💡 Proactive Drafting
- SpecEdge는
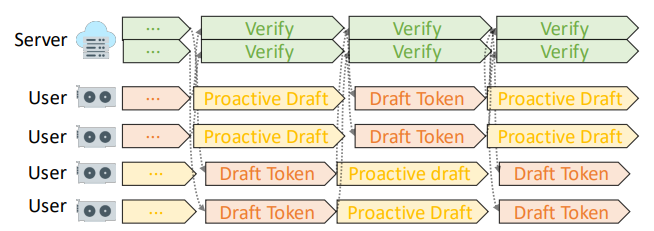
Proactive Drafting을 사용하여 초안 생성 / 검증과정의 지연 시간 발생 문제를 해결하며, 아래 피규어는proactive drafting의 과정을 시각화한다.
- 두 번째 단계에서
Expansion Head는 초기 초안의 다음 초안 시작 단어를 의미하는데, - 세 번째 단계에서 이
Expansion Head도 검증이 끝난 토큰으로 처리되어 있는 것을 볼 수 있다.- 이는
첫 번째 초안 + 1 시점의 단어로 이는 server 모델이 정보 제공의 목적으로 엣지 모델에게 두 번째 초안의 시작점을 알려주는 정보 제공의 역할을 한다.
- 이는
- 두 번째 단계에서
- 또한 서버 모델이 Verify시, Edge 모델이 쉬는 게 아닌 계속해서 검증에 맡긴 이후의 토큰 초안을 만드는 것을 말한다.
- 이 방법을 통해 지연 시간 증가 문제를 해결한다.
- 아래 그림은 Proactive drafting을 사용한 예시를 보인다.
- 또한 아래 그림은
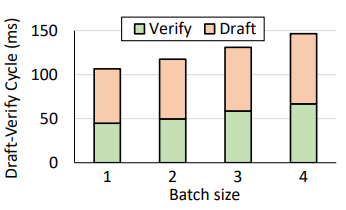
초안 생성(Draft)과정이 차지하는 비율을 보이며, 이를 Server모델이 아닌 Edge 모델이 수행함에 따라 시스템 효율성이 커지는 결과를 방증한다.
Risk of server underutilization (Solutions)
- 서버 미사용 문제는 server의 모델이 검증 과정에 집중하여 사용하다보니, edge 모델이 초안을 생성할 때 server 모델은 과도하게 미사용되는. 즉,
bubbles가 발생
🔦
bubbles란?
- 컴퓨터 아키텍쳐 또는 파이프라인에서 사용하는 용어로,
- 아무런 일을 하지 않아 빈 공간을 칭하는 단어이며
idle time이라고 하기도 함
- SpecEdge는 이러한 비효율성 문제를 해결하기 위해
interleaving방법을 사용하여, 여러 디바이스에서 초안이 완성되고 검증을 요청할 때마다 바로 검증을 진행하며, 동시에 여러 검증도 수행스케줄을 촘촘히 채우고 GPU 연산 능력 극대화
연속 배치(Continuous Batching)및연산 최적화- batch로 여러 사용자의 draft를 받아 검증할 때, 배치 내 데이터간 섞이지 않게
custom attention masking사용 - 또한 연산 효율성을 위해 배치내 가장 긴 시퀀스에 맞춰
KV 캐시 패딩사용
- batch로 여러 사용자의 draft를 받아 검증할 때, 배치 내 데이터간 섞이지 않게
SpecEdge 효과
- SpecEdge 사용 결과,
- 단일 서버 사용 환경과 비교했을 때 여러 Task에서 비용 효율성은
1.91배, 서버 처리량(server throughput)은2.22배향상됨을 보였으며, - Inter token latency. 즉, 다음 단어 출력까지의 지연시간이 평균
11.24% 감소한 결과를 보임
- 단일 서버 사용 환경과 비교했을 때 여러 Task에서 비용 효율성은
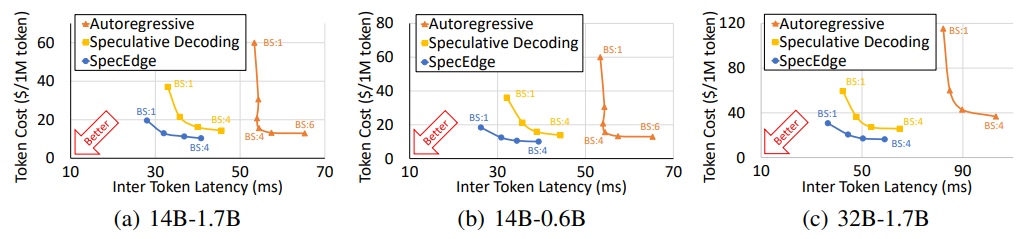
- 아래 그림은 Auto-Regressive, Speculative Decoding, SpecEdge를 비교했을 때
SpecEdge가 가장 효율적임을 보인다.

Data Scientist & Data Analyst