
- 오늘은 LLM 응답 품질을 높이기 위한
RAG(Retrieval-Augmented Generation)를 알아보려한다.
RAG(Retrieval-Augmented Generation)
-
LLM은 똑똑하지만 동시에 한계도 존재한다.
- Hallucination
- Train-based knowledge
-
특히, Specific Domain이라면 LLM 응답 품질의 저하는 더욱 부각된다.
-
우리 말로 검색 증강 생성이라고 불리우는 RAG는 이러한 LLM 응답 퀄리티를 향상시키기 위한 방법이다.
-
먼저 RAG의 아키텍처는 아래와 같다.
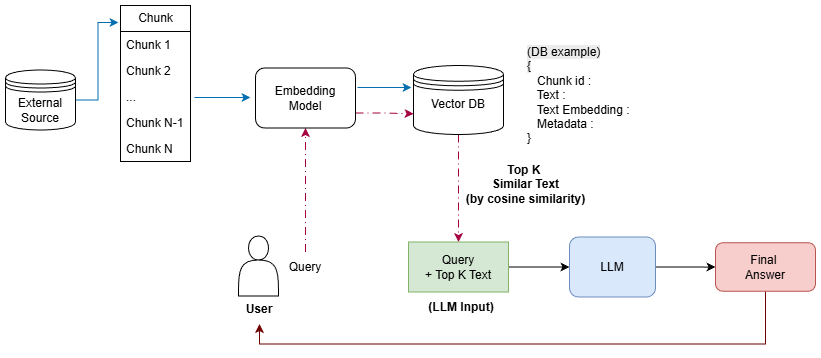
RAG, 왜 필요할까?
-
앞서 언급했듯, RAG는
검색을 사용하여 LLM 응답의 품질을 높인다. -
LLM은 학습시 사용한 데이터 기반의 지식을 갖고 있기 때문에 학습되지 않았거나, 최신 지식이라면 더더욱 응답 퀄리티가 저하되는 문제가 발생
-
그럼 더 많은 데이터로 Tuning하면 되지 않냐?는 의문이 들지만,- 소요 시간, 튜닝 데이터 정제, GPU 사용 등
리소스 측면에서 명확한 한계가 존재 - 또한
새로운 지식이 등장할 때마다 re-training 필요
- 소요 시간, 튜닝 데이터 정제, GPU 사용 등
-
반면에 RAG는 검색에 사용할 데이터를
임베딩으로만 생성하고 DB에 저장하면 필요할 때마다 사용할 수 있어, 리소스 측면에서 절약이 가능하고 새로운 지식이 등장해도 벡터 DB만 업데이트 하면 되기 때문에리소스 최소화 + 최신 지식 반영 가능이라는 장점이 있다.
RAG 구축 단계
-
그렇다면, 이제 RAG를 어떻게 구축해야 하는 지 알아보자!
-
RAG는 LLM이 검색할 수 있도록
인덱싱과런타임이라는 주요 단계로 분할할 수 있다.
인덱싱(indexing phase)
-
LLM이 정확한 응답을 할 수 있도록 지식을 준비하는 단계로,
-
아래 4단계로 구성된다.
1. 데이터 준비 및 전처리-> PDF나 문서의 텍스트를 정제하는 과정2. Chunk 단위 분할 (Chunking)🟢3. Chunk 별 임베딩 생성🟢4. 벡터 DB에 저장🟢
(🟢를 표시한 2~4단계는 좀 더 자세히 알아보자)
-
Chunking-
Chunking이란, 큰 데이터나 방대한 텍스트를
일정한 크기나의미적 단위의 작은 덩어리로 나누는 과정을 의미힌다. -
RAG에서 chunk를 나누는 이유는,
-
하나의 문서를 하나의 임베딩으로 변환할 때 오히려 여러 의미가 희석되기 때문에
-
각 임베딩에 명확한 의미를 부여하기 위해 사용= 검색 성능 높이기 위해
-
-
Embedding-
텍스트를 일련의 실수 벡터로 표현하는 방법으로, 고차원 공간에 매핑
-
임베딩 간 Cosine Similarity, Euclidian Distance 등 계산하여 유사도 측정
-
임베딩 생성 모델도 처리할 수 있는 최대 토큰 수가 지정 되어 있어,
chunk 단위로 임베딩 생성이 필요하다.-
추가적으로 이 과정에서
중복(overlap)이 필요하다. -
만약 중복 사용하지 않고 청크를 만든다면,
C_1, C_2, C_3의 정보는 의미가 단절된 형태를 보여 검색 성능이 크게 떨어지지만,
-
중복을 사용하면
토큰이 여러 청크에 공통으로 포함되어 청크 간 의미 단절 문제를 해결할 수 있다.
-
-
⭐️ 위 설명한 방법은 청크를 나누는 가장 기본적인 방법이며 청크를 나누는 방법도 다양하다.
⭐️ 여러 방법 중
문장 간 유사도를 기반으로 청크를 나누는 방법에 대해 알아보자.1️⃣ 먼저, 전체 텍스트를
.,?,!등을 기준, 문장으로 분할한 뒤]2️⃣ 문장 임베딩 모델을 사용하여 분할된 모든 문장의 임베딩을 생성
3️⃣ 문장 임베딩 간
Cosine similarity혹은Euclidian Distance를 측정하는데, 현재 문장을 기준, 바로 뒷문장 간에만 측정!4️⃣ 임계치(Threshold)를 정하여, 유사도가 임계치는 넘지 않는 지점을 기준으로 청크를 구분
5️⃣ 나뉜 청크를 임베딩으로 생성하여 Vector DB에 저장
ex) 문장 A~E까지 5개 문장이 있고, 임계치가 0.75일 때, 아래와 같이 청크가 구성된다.
A, B 간 유사도 0.9
B, C 간 유사도 0.8
C, D 간 유사도0.2
D, E 간 유사도 0.95
chunk_1 : 문장 A, B, Cchunk_2 : 문장 D, E
Vector DB 저장-
1~3단계를 마쳤다면 이제 검색할 때 참고할 DB를 만들어야 한다.
-
DB구성의 필요 요소는
id,embedding,content,metadata이다.-
id: 식별자 -
embedding: 텍스트 임베딩 -
content: 텍스트 -
metadata: 출처, 페이지 수, 업데이트 날짜 등
-
-
예시
{ "id" : "chunk_01 ~", "embedding" : [-0.123, 0.1782, 0.857, -0.561, ... , 0.982], "context" : "신체에 필요한 필수 영양소는 탄수화물, 단백질, 지방이며 매일 필수 섭취량은...", "metadata": { "source" : "~~~", "page" : N, "date": "2025-xx-xx" } }
-
- 검색에 활용할 임베딩 규모에 따라 적절한 DB를 선택하면 된다.
- 필자는
ChromaDB를 사용하였으며,- 대용량 DB 혹은 DB 구성 요소가 다르다면
pinecone,Qdrant,Weviate등 다른 DB 찾아보자!
- 대용량 DB 혹은 DB 구성 요소가 다르다면
- 필자는
런타임(Runtime phase)
-
런타임 단계는 질문이 들어올 떄마다 실시간으로 동작
-
런타임 단계는
검색(Retriever)과생성(Generation)으로 구성-
검색(Retriever)-
사용자의 질문(qeury)을 임베딩으로 생성
(인덱싱 단계의 임베딩 모델과 동일한 모델로!) -
query 임베딩과 Vector DB 내 임베딩과 유사도를 측정하여 상위 K개를 추출
- DB 임베딩과 효율적인 유사도 측정을 위해
근사 최근접 이웃(ANN)을 사용하여 유사한 임베딩 필터링
- DB 임베딩과 효율적인 유사도 측정을 위해
-
상위 K개 content를 응답 생성의 참고 자료로 활용
-
-
생성(Generation)- K개 content와 query를 조합한 최종 입력 프롬프트를 LLM에 입력하면 최종 응답을 생성한다!
-
