
LLM(Large Language Model, 거대 언어 모델) 기술이 점점 고도화 되면서, 각 분야에 많이 적용하고 있다.
특히, 주로 텍스트를 다루기 때문에 Topic Refinement(토픽 모델의 결과 정제), Text Summarization(요약), Text Augmentation(증강) 등 NLP 여러 분야에서 활용된다.
오늘은 그 중에서 LLM을 사용하여 Text Augmentation을 사용한 논문의 일부를 정리하려고 한다.
논문명:
- Enhancing Short-Text Topic Modeling with LLM-Driven Context
Expansion and Prefix-Tuned VAEs
저자:
- Akash, P. S., & Chang, K. C. C. (2024)
문제점
- 지난 번 PBM을 다룬 포스팅에서도 Short Text 언급했음!
- 토픽을 추출할 때, 사용하는 모델의 성능도 중요하지만 분석 대상인 텍스트 내 정보가 부족하면 데이터 희소성(Data Sparsity) 문제가 발생한다.
- 텍스트가 짧으면 단어의 동시발생빈도가 현저히 낮게 되고, 이는 토픽 모델링이 좋지 않은 결과를 내는 단점
- 전통적인 토픽 모델의 경우 데이터 희소 문제가 발생하면 high quality topic을 얻기 힘듦
- 짧은 텍스트는 오히려 데이터 크기가 작은 것보다 더 주된 문제점!
그렇다면, 기존에는 어떤 방법을 사용했을까?
- 메타 데이터 활용
- 메타 데이터란, 데이터의 정보를 담고 있는 데이터(즉, 데이터를 설명하는 데이터)- 예를 들어 작성자 정보, 해시 태그, 외부 정보 등
- 메타 데이터를 활용하여 짧은 텍스트를 Longer pseudo-document로 생성
But, 메타데이터는 모든 데이터가 가지지 않기 때문에 항상 활용할 수 없는 단점이 존재!
위 문제를 해결하기 위해 텍스트 내부 구조 정보 또는 의미 정보를 사용한다.
예시 모델로는 BTM(Biterm Topic Model)이 있다.
- BTM
- 텍스트 내 단어 쌍의 공동출현 빈도를 고려
- ‘I love you’라는 문장이 있다면, (’i’, ‘love’), (’i’, ‘you’), (’love’, ‘you’) 3가지를 고려한다.
- corpus의 전체 biterm을 이용,
각 bi-term이 어느 토픽에서 발생할 가능성이 높은 지 추정(=확률 기반) - 그러나 Document-Topic Distribution을 제공하지 않아 별도 계산이 필요한 단점
- 다른 모델 (DMM 등)
- 다른 모델은 단 하나의 토픽으로 제한한다던지 부가적인 문제가 있음
- 단일-토픽 모델(single-topic-per-document) 특징으로 표현력 부족
Short Text로 인한 문제를 해결하기 위해 해당 논문에서는 사람의 토픽 탐지 과정을 이해하고자 하였다.
- 흔히 볼 수 있는 특징은
-
타이틀 or 캡션은 긴 텍스트의 요약을 담당하는 대표 유형이고 실제로 전체 내용의 힌트 역할
-
사람은 배경지식을 이용해서 텍스트의 토픽을 추론
(ex-문장 내 FIFA라는 단어가 있다면 ‘스포츠'라는 토픽을 추론)
그렇다면 LLM을 사용한 텍스트 증강은?

- GPT-3, , LLAMA2, T5과 같은 LLM은 텍스트 생성에서 좋은 결과 보임
- LLM이 생성한 결과를 보면 ‘스포츠’와 관련된 단어가 종종 포함되어 있음을 확인할 수 있다
- 텍스트 길이도 훨씬 길어져서 토픽 모델이 사용할 정보도 많아짐
Short Text 증강 측면에서 LLM이 가장 현실적인 대안이지만, 고려해야할 several challenge가 있다.
Challenge 01. Semantic Consistency
- 짧은 텍스트를 길게 만든다해도, 증강 전 텍스트 의미가 파괴되면 필요 없음
- 관련 없는 정보 또는 부정확한 정보에 대해 명시 없이 의미를 유지하기 어려움
- LLM은 특정 작업또는 특정 도메인에 언제나 파인튜닝 되지 않아서 semantic drift. 즉, 잘못된 결과를 이끌어 낼 수 있음
Challenge 02. latency of LLM
- 실시간 환경에 적용하기에는 LLM 호출 지연시간이 있어 텍스트 생성에 걸리는 시간이 소요되기 때문에 실용적이지 못함
To tackle challenges
-
LLM이 이전에 생성한 텍스트를 바로 input으로 사용하지 않고, 토픽 모델을 사용하여 생성한 텍스트(longer text By LLM)를 증강하는 방법을 사용
- 위 방법을 사용하여 텍스트 생성 과정에서 발생하는 의미 변화 최소화
- 기존 텍스트(short text)로부터 토픽을 Decoding(추출) 함으로써 이 토픽을 LLM의 Character(특성)으로 사용(즉, 길잡이 역할)
- LLM은 텍스트 생성 과정에서 latent conceptual space의 영향을 받음
- LDA와 같은 discrete topic을 사용하는 모델은 잠재 개념 공간을 바로 추론하기에 직관적이지 않음
대안으로 PVTM(Prefix-tuned Variational Topic Model)을 제안
-
PVTM → Language Model(LM)과 VAE(Variational AutoEncoder)를 결합하여 short text에서 토픽을 추론
-
LM은 단독 또는 토픽 모델과 결합하여 문서를 임배딩으로 표현하는 역할로 사용하며, 논문에서는 일부 변수만 파인튜닝(Frozen 방법)을 적용하여 연산량을 줄임
- LM ex) CTM, BERTopic, DeTime 등
-
VAE는 잠재 공간으로부터 샘플링하여 디코더를 거쳐 입력을 재구성하는(Decoding) 과정으로 학습
-
PVTM구조와 설명
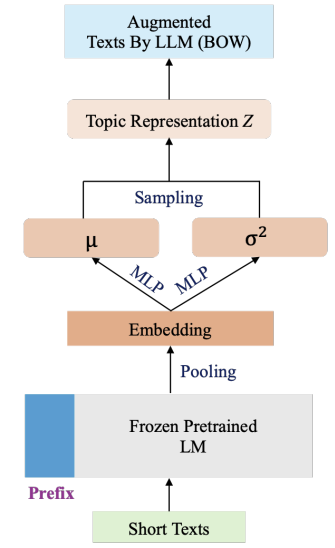
기존 짧은 텍스트(t)와 LLM으로 t를 증강시킨 텍스트(T)를 함께 corpus로 생성하여 vocab 생성
기존 텍스트에 Frozen Pretrained LM을 사용하여 임베딩 생성
MLP 사용, Topic Representation Z를 샘플링할 평균(mu)과 분산(sigma^2)를 갖는 가우시안 분포 생성
Topic Representation Z 샘플링
샘플링 된 Z를 Decoder 네크워크 통과시킨 재구성 결과와 증강시킨 텍스트의 BoW와 손실을 계산하여 모델 하습
Result
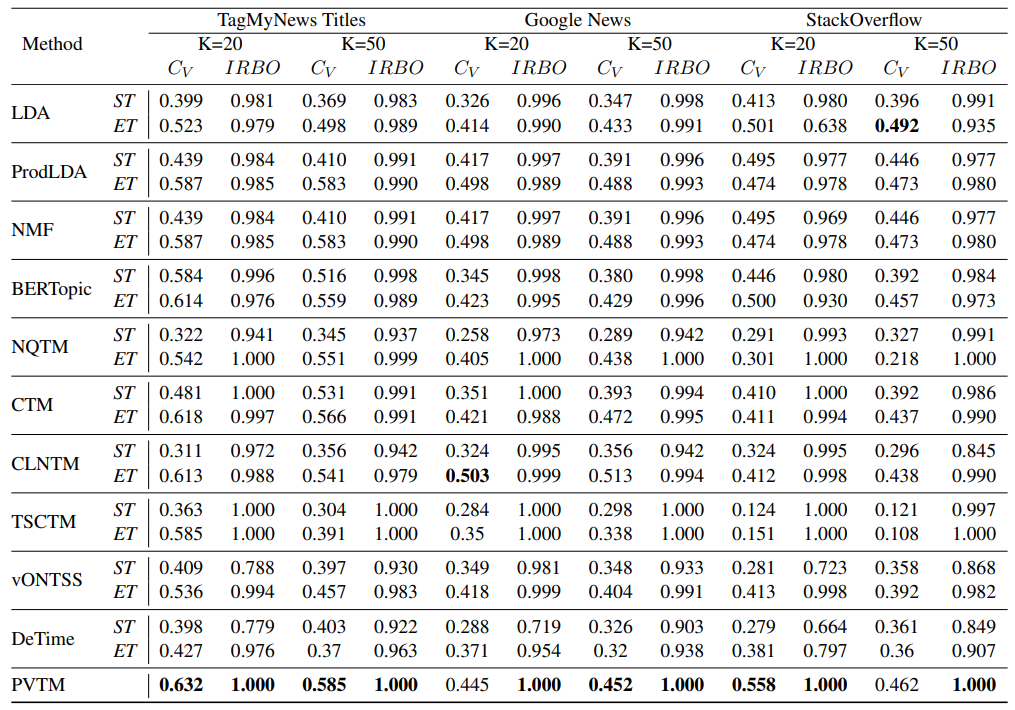
결과 01. 토픽 일관성, 다양성 결과
(ST : 기존 텍스트, ET : 증강된 텍스트)
결과 02. Text classification 정확도 결과
(SVM : Support Vector Machine, LR : Logistic Regressor)
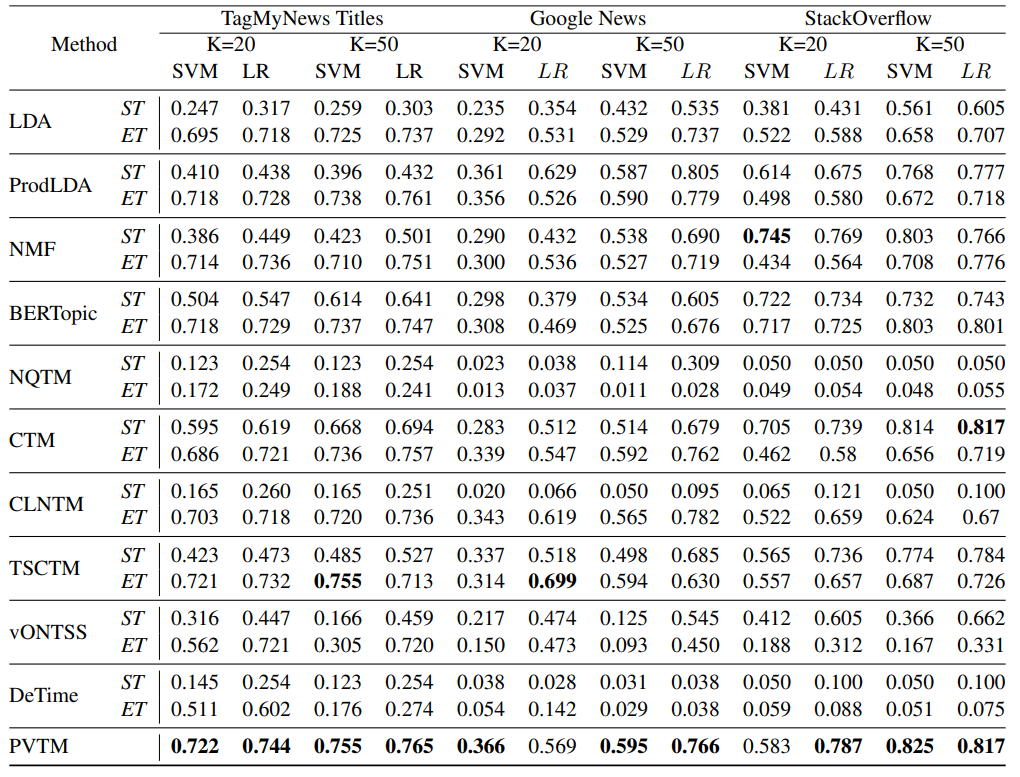
토픽 일관성, 다양성을 포함한 분류 성능에서도 기존 baseline 대비 PVTM에서 가장 좋은 성능
정리
- PVTM의 장점
-> 기존의 짧은 텍스트에서 발생하는 토픽 품질 저하문제 개선
-> VAE 입력에 BoW가 아닌 임베딩을 사용함으로써 의미 일관성 보존
-> Prefix tuning을 사용하여 리소스 효율적으로 감소
끝!
다음 포스팅에서는 PVTM에 사용한 prefix-tuning과 비슷한 방법인 prompt-tuning에 대해 정리하려고 한다!
