
-
오늘은 토크나이저 직접 훈련시켜보기!
-
텍스트를 전처리하는 파이프라인에서 토크나이저는 꽤 중요한 역할을 담당한다.
-
사실 요즘엔 여러 토크나이저가 체크포인트로 제공되어 직접 구현해서 사용하지는 않지만 그 과정을 아는 것과 모르는 것은 큰 차이가 있다고 생각하여 직접 구현하였다.
-
사용 Data
-> IMDB 데이터 중 target이 긍정(positive)인 데이터 500개, 부정(negative)인 데이터 500개를 사용하여 텍스트 데이터를 구성하였다. -
사용 모델
-> BERTWordPieceTokenizer
토크나이저 생성 과정
- 정수 형태로 매핑되어 있는 각 토큰을 디코딩 하면 아래와 같이 변환된다.
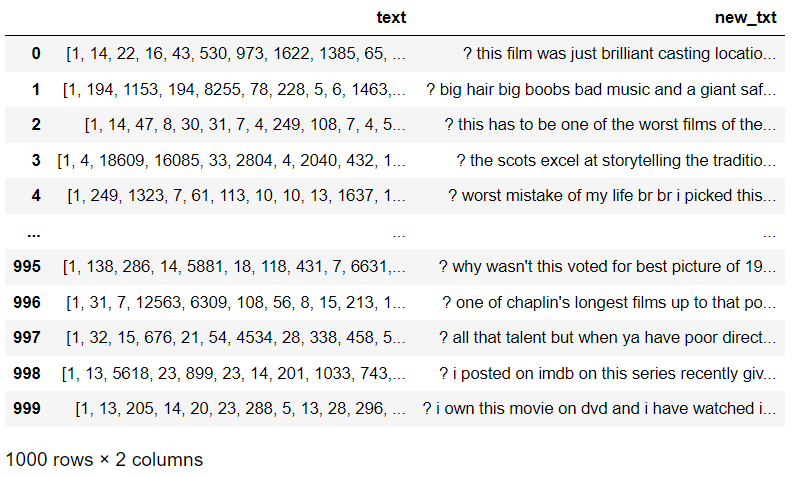
- 생성된 'new_txt'의 결과를 하나의 텍스트 파일로 저장하기 위해 빈 문자열 객체를 생성, 한 행(row)씩 이어서 생성

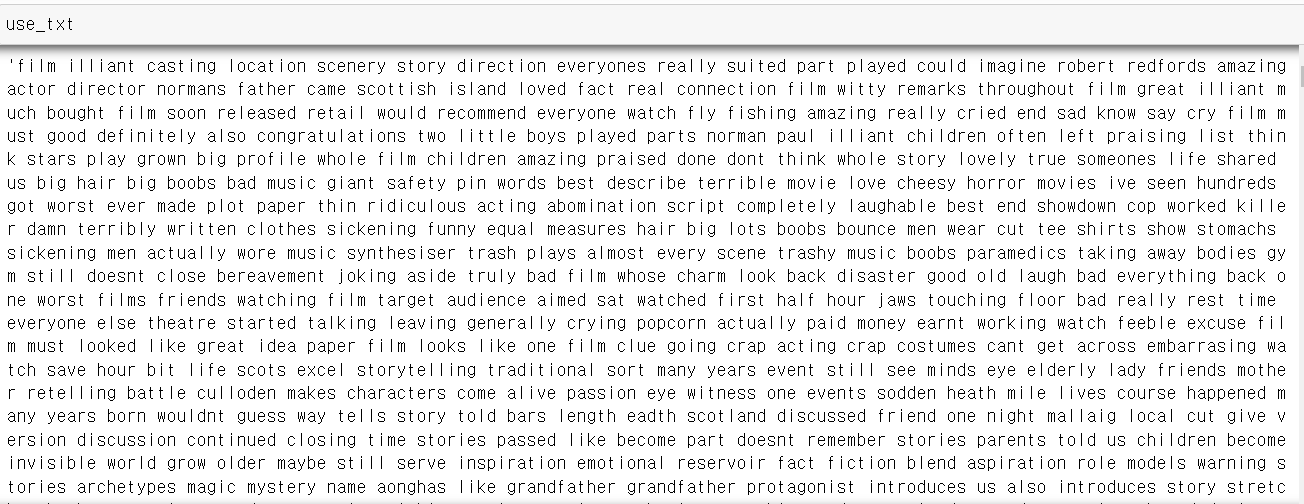
- 기본적인 불용어, 특수문자 제거된 텍스트로 vocab을 생성하기 위해 아래 전처리 코드를 사용
def txt_preprocess(text):
my_text = copy.copy(text.translate(translator))
my_text = my_text.replace('br', '') # HTML 태그 제거
my_text = my_text.replace('\\t', '') # 띄어 쓰기 제거
p = re.compile(r'<br\\s*/?>|[^A-Za-z]') # 알파벳 제외한 추가 문자 제거
my_text = p.sub(' ', my_text)
result = [word for word in my_text.split() if word not in stopwords]
last = ' '.join(result)
return last- 전처리 결과
- 토크나이저 훈련 위한 라이브러리와 객체 생성
from tokenizers import BertWordPieceTokenizer
tokenizer = BertWordPieceTokenizer(strip_accents=True, lowercase=True)
# lowercase는 소문자변환
# strip_accents는 발음 기호 제거에 대한 파라미터
- 이전에 생성한 텍스트 파일을 저장한 뒤 토크나이저 train을 수행한다.
with open('use.txt','w') as f:
f.write(use_txt) # 텍스트 파일 저장 ('use.txt'가 저장할 파일 이름)
data_file = 'use.txt'
vocab_size = 30000 # vocabulary 크기 지정
limit_alphabet = 1000 # 최대 글자 수 제한
min_frequency = 5 # 단어 등장 최소 빈도
tokenizer.train(
files = data_file,
vocab_size = vocab_size,
limit_alphabet = limit_alphabet,
min_frequency = min_frequency
)-
훈련된 토크나이저 확인, 저장 후 데이터프레임으로 불러 확인하기
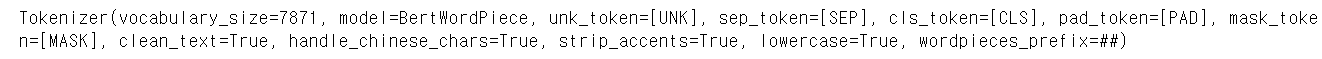
tokenizer.save_model('./') # 현재 경로에 vocab.txt 생성 df = pd.read_fwf('vocab.txt', header = None)
- 토크나이저 적용

위와 같이 잘 적용됨을 확인할 수 있다.
정리
- 토크나이저에 규칙을 적용한다던지, 기존에 UNK로 매핑되는 토큰을 다루어야 한다던지 특수한 상황이 아니라면 이미 제공되는 여러 토크나이저를 사용하는 게 훨씬 성능도 좋다.
- 하지만 앞서 언급했듯 생성 과정을 알고 사용하는 것과 모르고 사용하는 것은 큰 차이가 있다고 생각하여 간단하게 직접 구현해보았다.

Data Scientist & Data Analyst