
-
오늘은 LLM 텍스트 생성 과정의 속도를 높이기 위해 디코더의 Multi Head Attention 대신 사용하는
Multi-Query Attention(MQA)와Grouped-Query Attention(GQA)방법에 대해 알아보자! -
참고 논문
| Ainslie, Joshua, et al. "Gqa: Training generalized multi-query transformer models from multi-head checkpoints." arXiv preprint arXiv:2305.13245 (2023).
📚 우선 MHA의 단점은 뭘까?
- 멀티 헤드 어텐션은 여러 개 헤드를 사용하여 헤드마다 다른 관점 or 관계를 학습한다. 즉, query 개수만큼 함께 연산을 수행하는 key, value도 동일한 개수가 필요화다.
정확도는 높으나 많은 연산 필요
💡MHA 속도 향상 방법
1) Multi-Query Attention(MQA)
-
MQA는 어떻게 효율적인 연산을 수행할까?
-
기존 MHA는 헤드 개수(N개)만큼 query, key, value가 각각 N개씩 존재하지만,
-
MQA는 query만 N개이고 나머지 key, value는 1개씩만 생성한다.
-
- 이는 연산량 감소 뿐 아니라, 아래 두 방법을 사용하여
메모리 병목 현상을 해결, 속도를 향상 시킨다.
⭐
1. KV 캐시 감소
- LLM에서 생성 작업 시, 다음 단어를 예측할 떄 이전 단어들의 K, V를 매번 계싼하지 않기 위해 K, V를 저장하는 KV캐시를 사용
- MQA는 head가 32개인 모델을 기준으로, KV캐시가 메모리를 차지하는 비율을 로 감소
⭐
2. 메모리 대역폭 병목 해결
- GPU는
Memory-Bound
- 연산 속도가 빠르지만 메모리에서 데이터를 읽어오는 속도가 비교적 느린 단점
- 단일 K,V를 사용하는 MQA는 KV 캐시가 크게 줄어, 데이터를 읽어오는 시간이 단축되고 결과적으로 토큰 생성 속도가 향상된다.
즉, 직관적으로 MQA는 메모리 적게 쓰고 속도를 빠르게 하는 방법
2) Grouped-Query Attention(GQA)
-
GQA는 MQA의 quality degradation. 즉 성능이 하락하는 단점을 보완하기 위해 고안된 방법
-
주요 특징은
그룹화된 query-key-value으로, -
MHA의 장점인
여러 관점으로 관계를 파악하는 것과, MQA의 장점인연산량 감소 + 메모리 캐시 감소를 결합한 방법이다.
💡 MHA vs MQA vs GQA
- 각 방법의 특징은 아래 표와 같다.
| - | MHA | MQA | GQA |
|---|---|---|---|
| 메모리 효율 | 매우 낮음 | 가장 좋음 | 좋음 |
| 생성 속도 | 느림 | 가장 빠름 | 뺘름 |
| 관점 개수(=헤드) | 다양 | 단일 | 중간 |
- 또한 각 방법의 구조는 아래 그림과 같다.
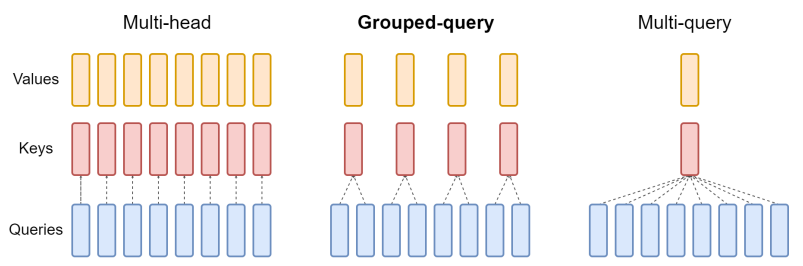 | Ainslie, Joshua, et al (2023)
| Ainslie, Joshua, et al (2023)
- 추론 속도, 성능 결과

- T5 XXL 모델 기준, MQA는 추론 속도는 가장 빠르나, MHA와 비교했을 때 비교적 성능 저하가 크고,
- GQA는 MHA 대비 비슷한 성능, 추론 속도는 MQA와 비슷한 결과를 보여,
추론 속도 + 성능을 고려했을 때 가장 좋은 방법임을 보였다.
💡추가 정리
- MQA와 GQA는
어느 단계에서 사용하느냐에 따라 구성하는 방법이 다르다.Scratch혹은Uptraining
Scratch
- 만약, LLM을 직접 구현하고 사전학습까지 시키기 위한 목적이고 MQA 또는 GQA를 사용한다면
Initialization을 사용하여 MQA의 경우 K, V 각 1개씩, GQA의 경우 그룹 수만캄 각각 생성해주면 된다.
Uptraining
-
이미 사전학습이 끝난 모델(gemma, Llama 등)을 추가로 학습시키는 경우,
-
각 모델 checkpoint를 사용하여 평균 풀링을 적용한 K, V 사용한다.- MQA 예시
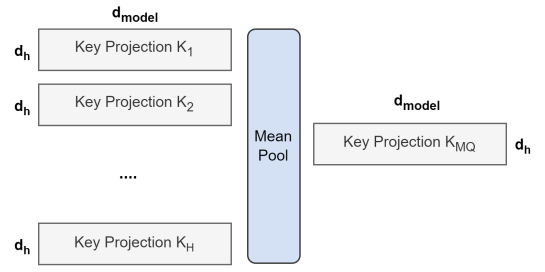
- MQA 예시
💡GQA 평균 풀링 예시
- 사전학습된 모델을 기준으로 Key와 Value에 GQA를 적용하는 과정에 대한 예시
- checkpoint: T5-XXL
d_model = 4096
num_heads = 64
num_groups = 8
heads_per_group = num_heads // num_groups
head_dim = d_model // num_heads
mha_key_weight = torch.rand(d_model, d_model)
gqa_key_weight = mha_key_weight.view(num_groups, heads_per_group, head_dim, d_model) # shape:[8,8,64,4096]
gqa_key_weight.mean(dim=1,keep_dim =True) #[8,1,64,4096]
- 위 예시 중 마지막
mean 적용이 MHA -> GQA의 핵심

Data Scientist & Data Analyst