
- seq2seq라고도 불리는 sequence to sequence 모델은 기존 RNN을 활용하여 만든 모델이다.
- 특히 자연어처리에서 많이 쓰였고 이 모델의 영향을 받아 변형 모델이 생기도 아직도 사용한다.
- 오늘은 이러한 seq2seq의 구조에 대해서 알아보고자 한다.
Sequence to Sequence
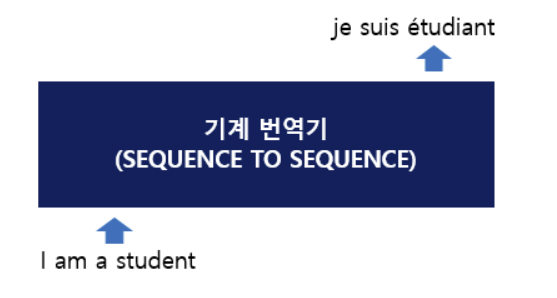
- 위 그림에서 볼 수 있듯이 seq2seq 아키텍처 내부 구조에 의해 입력된 'I am a student'는 'je suis etudiant'라는 문장으로 번역된 것을 볼 수 있다.
그렇다면 seq2seq 내부 구조를 살펴보자
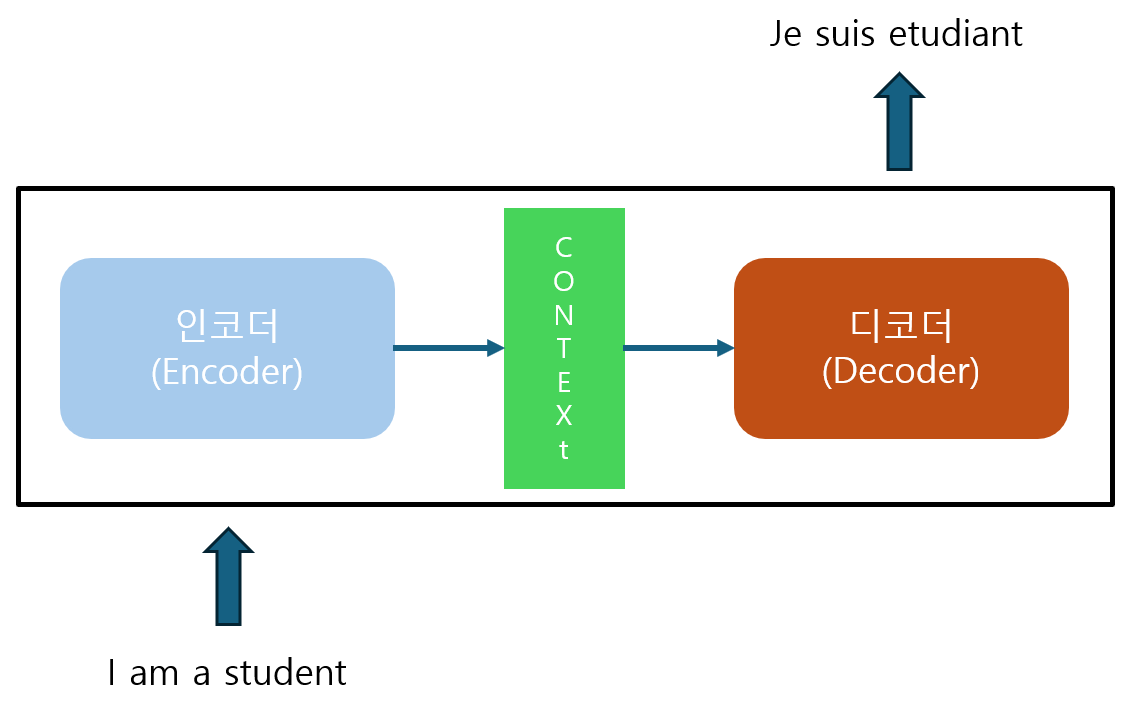
- seq2seq는 인코더, 디코더로 구성되어 있다.
- 인코더는 입력된 데이터를 순차적으로 받은 뒤, 모든 정보들을 압축해서 하나의 Context Vector로 만드는 역할을 담당
- 디코더는 Context Vector를 받아서 번역된 단어를 하나씩 출력한다.
인코더와 디코더를 좀 더 자세히 보면 아래 구조와 같다.
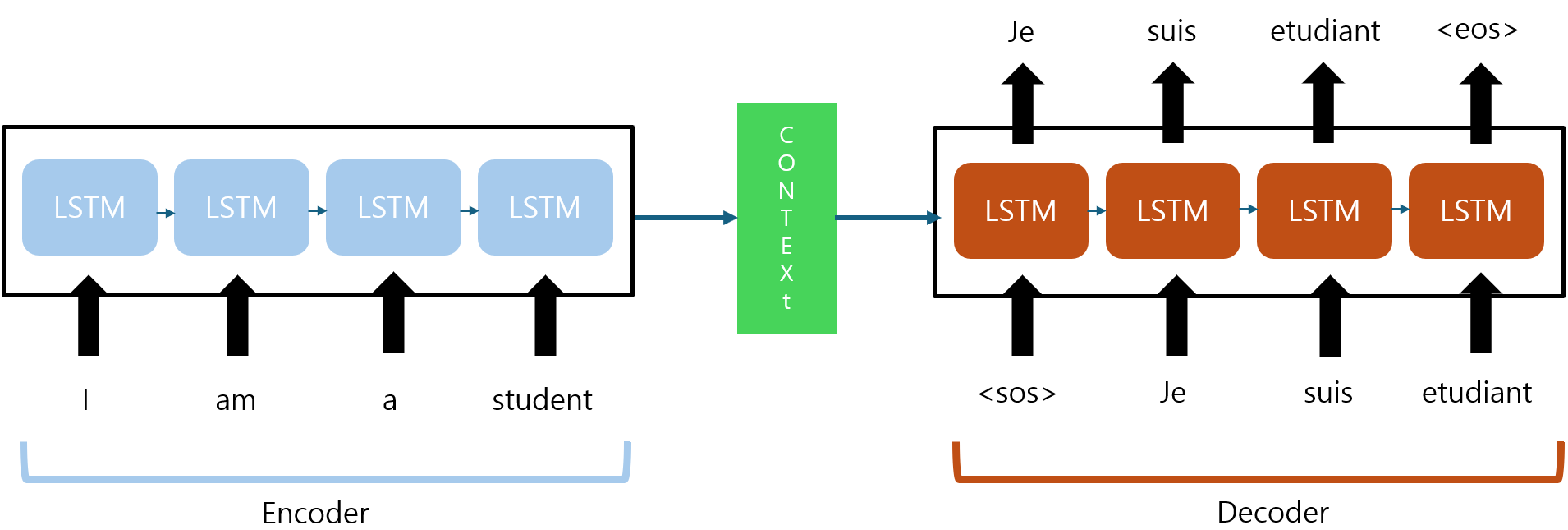
- 인코더와 디코더의 각 모듈에는 RNN보단 LSTM, GRU와 같은 모델이 사용된다.
(RNN은 기울기 소실 또는 기울기 폭발 문제가 발생하여 이를 방지) - 인코더의 마지막 LSTM셀에서 반환된 결과가 디코더로 전달되는데, 이게 바로 Context Vector이고, 이 벡터는 Numerical 성질을 갖는다.
- 디코더에선 이 벡터가 첫 LSTM의 입력으로 사용
- start of sequence라는 의미의 sos가 입력되면 디코더는 확률을 고려하여 다음에 나올 확률이 가장 큰 단어를 다음 단어로 예측한다.
(즉, 디코더는 예측한 단어를 다음 셀 입력으로 사용)
- 위와 같이 이전 셀에서 예측한 단어를 다음 셀에서 입력으로 사용하고.... 이 과정을 반복하다가 end of sequnce(eos)가 예측되면 멈춘다.
더 세분화하여 LSTM을 살펴보자
- LSTM의 과정은 아래와 같다.
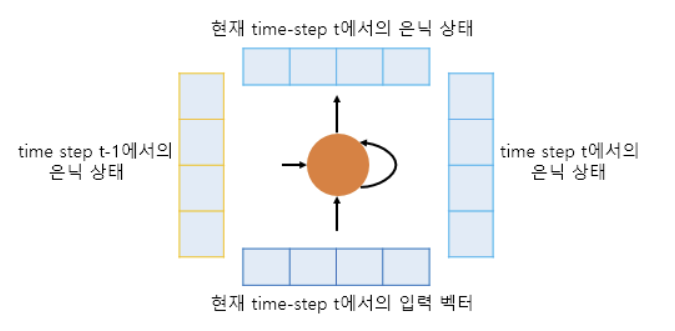
- t시점을 살펴보면, 이 시점의 임베딩 벡터와 (t-1)시점의 은닉 상태(hidden_state)를 입력으로 받아서 t시점의 은닉 상태를 생성한다.
- 결과적으로 t시점의 은닉 상태는 t-1, t-2, t-3... 등 이전 시점이 누적된 값이라고 볼 수 있다.
- 이 말은 인코더 마지막 셀의 은닉 상태는 모든 단어(또는 토큰)의 정보를 담고 있다고 할 수 있고 이게 Context Vector를 의미한다.
디코더의 단어 산출 과정
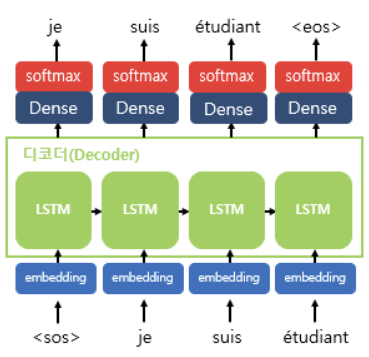
- LSTM 개별 셀은 Dense Layer + Softmax 구조를 거쳐 확률이 가장 높은 단어를 반환한다.
정리
- seq2seq 구조는 입력 시퀀스와 출력 시퀀스의 길이가 달라도 되어, 기계 번역, 텍스트 요약 등 웬만한 작업에 모두 사용할 수 있는 장점이 있지만
- 장기 의존성 문제
- 병렬 처리 불가
- 입력 시퀀스를 하나의 context vecotr에 담아야 하므로 정보 손실 발생
등 단점이 존재한다.
seq2seq의 단점을 극복하기 위해 Attention이 등장하였고 다음 포스팅에서는 어텐션 매커니즘에 대해 알아보고자한다.
| 그림 출처: https://wikidocs.net/24996

Data Scientist & Data Analyst