[JS]Scraping&Crawling

1.Scraping
- 다른 사이트 정보를 한번만 가져온다!
- scraping을 도와주는 node.js 라이브러리 => cheerio!!
og(opengrahp)를 가져오는데 많이 사용- meta태그 속 property속성이 og인 태그들의 내용을 가져오는 방식

import axios from "axios"
import cheerio from "cheerio"
// BackendAPI (사이트 주소를 알고있는 경우!)
async function createBoardAPI(mydata){
const targetURL = mydata.contents.split(" ").filter((el) => el.startsWith("http"))[0]
// 데이터 내용을 배열로 만들고 배열 값이 http로 시작하는 값 출력
console.log(targetURL)
const aaa = await axios.get(targetURL)
const $ = cheerio.load(aaa.data)
$("meta").each((_,ele) => { //each((몇번째 태그인지, 요소) => {} )for문처럼 작동!!!
if($(ele).attr('property')){ //모든 meta태그 중 속성이 property
const key = $(ele).attr('property').split(":")[1]
const value = $(ele).attr('content')
console.log(key,value)
// 콘솔 출력 값
// title 네이버
// url https://www.naver.com/
// image https://s.pstatic.net/static/www/mobile/edit/2016/0705/mobile_212852414260.png
// description 네이버 메인에서 다양한 정보와 유용한 컨텐츠를 만나 보세요
}
})
}
const frontendData = {
title: "안녕하세요~~",
contents: "여기 정말 좋은거 같아요 한번 꼭 놀러오세요!! 여기가 어디냐면 https://naver.com 입니다~~!!"
}
createBoardAPI(frontendData)
2.Crawling
- 다른 사이트 정보를 꾸준히 가져온다!
- crawling을 도와주는 node.js 라이브러리 => puppeteer!!
- 크롤링 가능 여부
사이트주소/robots.txt(= 크롤링여부 가이드 문서)로 확인 가능 - 크롤링 할 홈페이지에서 가져오고 싶은 내용을
copy selector를 이용해 복사해옴
개발자도구-element에서 해당 내용을 오른쪽클릭하면 copy할 수 있음
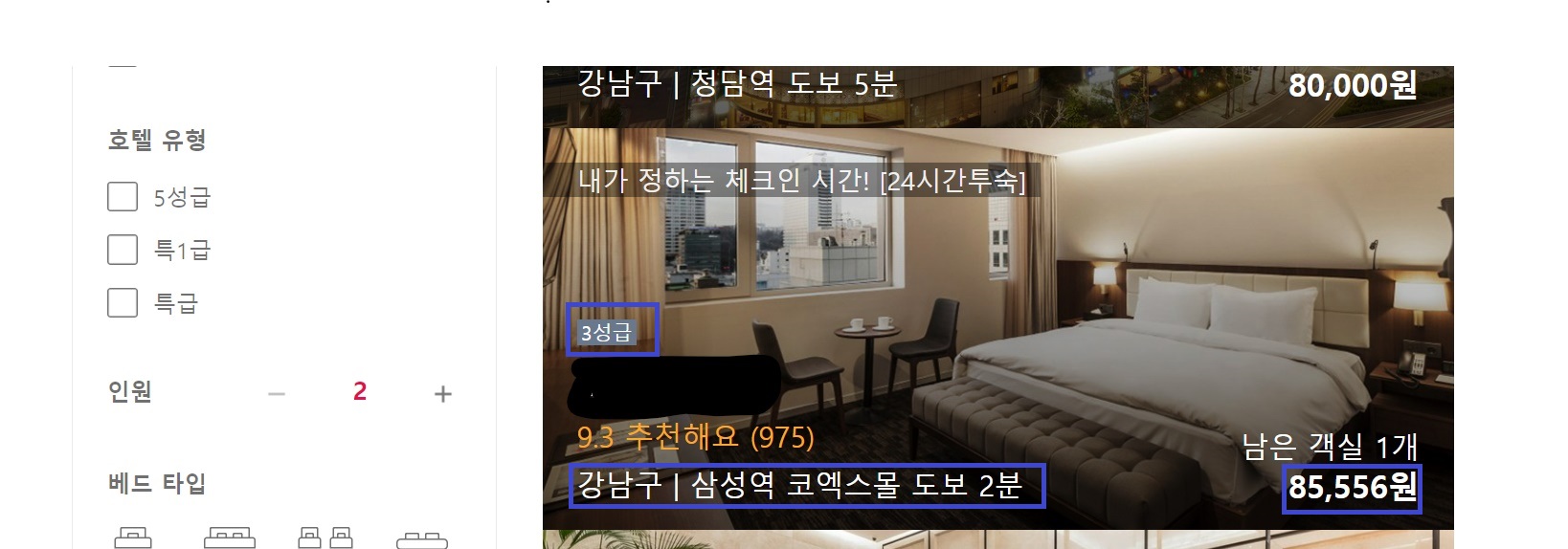
// 사진 속 홈페이지의 파란박스 안 내용들을 크롤링하는 코드
import puppeteer from "puppeteer"
async function startCrawling(){
const browser = await puppeteer.launch({headless:false}) //puppeteer에 내장되어있는 브라우저(chrome ...?) 시작 (headless:false => 눈에 보이게 함)
const page = await browser.newPage() //페이지 열기
page.setViewport({width:1280, height:720}) // page크기 조정
await page.goto("https://www.goodchoice.kr/product/search/2") // 주소로 이동
await page.waitForTimeout(1000) // 크롤링 주기 설정(주기 접속은 차단될 수 있어서 시간을 랜덤으로 설정하는게 좋음)
const stage = await page.$eval(
"#poduct_list_area > li:nth-child(3) > a > div > div.name > div > span",
(el) => el.textContent //copy selector로 복사한 내용 / el=태그 값 el.textContent=해당 태그의 내용가져오기
)
await page.waitForTimeout(1000)
const location = await page.$eval(
"#poduct_list_area > li:nth-child(3) > a > div > div.name > p:nth-child(4)",
(el) => el.textContent
)
await page.waitForTimeout(1000)
const price = await page.$eval(
"#poduct_list_area > li:nth-child(3) > a > div > div.price > p > b",
(el) => el.textContent
)
await page.waitForTimeout(1000)
console.log(stage) // 3성급
console.log(location.trim()) // 강남구 | 삼성역 코엑스몰 도보 2분
console.log(price) // 85,556원
await browser.close()
}
startCrawling()
공부하며 작성하고 있는 블로그입니다.
잘못된 내용이 있을 수 있으며 혹시 있다면 댓글 달아주시면 감사하겠습니다 😊
