기존모델의 한계
- RNN이 가지는 Sequence 구조의 단점은 단어가 순서대로 들어온 다는 것.
- 따라서 Sequence 가 길어질 경우 학습과정에서 발산이 일어 날수 있다.
- RNN 방식은 context vector v에 소스 문장의 정보를 압축함
Transformer
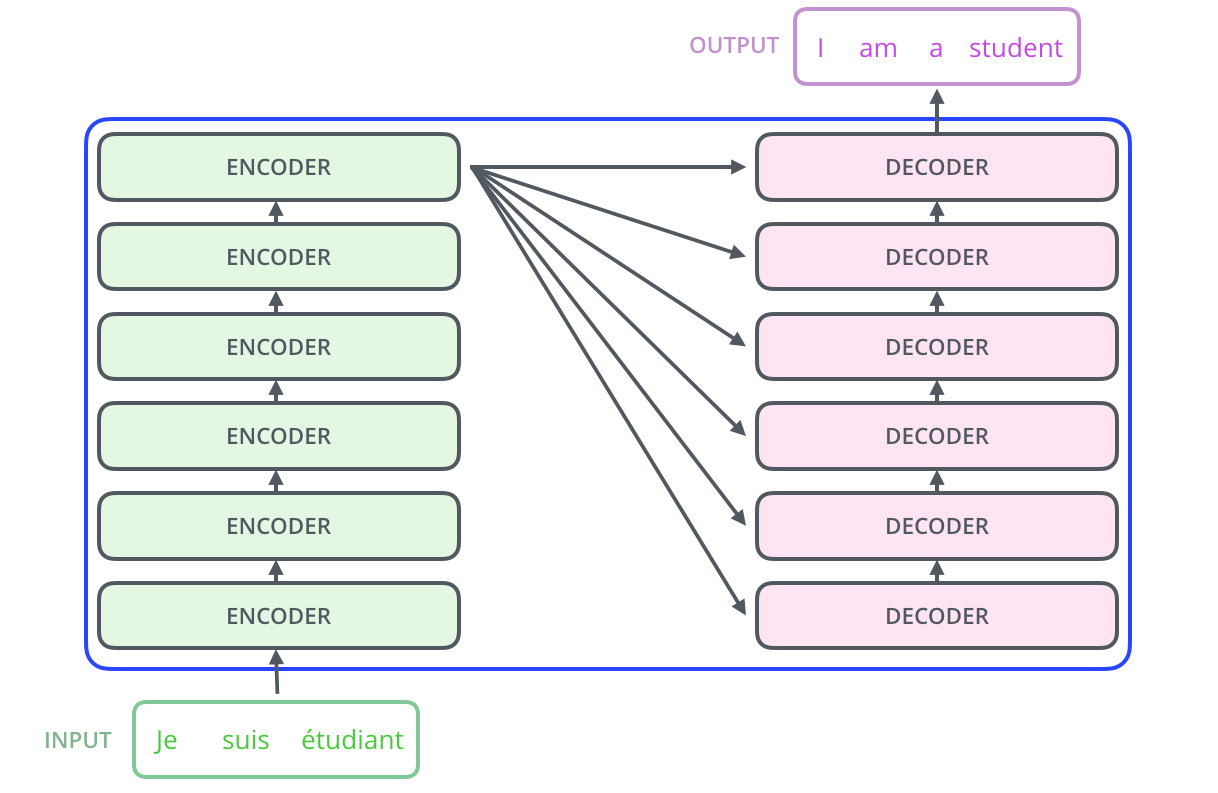
Transformer 구조
- Encoder의 결과물을 Decoder에서 한번에 받는다.
Self Attenstion 매커니즘
- 인코더와 디코더를 이루고 있는 Multihead Attentinon layer의 핵심 매커니즘
- 기본적인 목적은 한 문장에서 한 단어가 다른 단어와 어떤 관계를 갖고 있는지 수치화 하는 것
Query , key ,value
워드 임베딩은 벡터, 실제 문장은 행렬
- Querey : 분석이 대상이 되는 단어에 대한 가중치 벡터
- Key : 모든 단어. 각 단어가 쿼리에 해당하는 단어가 얼마나 연관이 있는가>
- value : 키의 의미를 나타내는 가중치 벡터
Attention 적용 절치
- input data 준비
Input 1: [1, 0, 1, 0]
Input 2: [0, 2, 0, 2]
Input 3: [1, 1, 1, 1]
- 가중치 초기화
- Query , key ,value 는 Wq, Wk, Wv 가중치행렬을 통해 생성된다.
- Wq, Wk, Wv는 딥러닝 학습과정을 통해 최적화된다.
w_key = [
[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]
]
w_query = [
[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]
]
w_value = [
[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]
]
w_key = torch.tensor(w_key, dtype=torch.float32)
w_query = torch.tensor(w_query, dtype=torch.float32)
w_value = torch.tensor(w_value, dtype=torch.float32)
- Query , Key , Value 계산
각 문장의 쿼리, 키 , value는 행렬곱을 통해 한번에 구할 수 있다.
keys = x @ w_key
querys = x @ w_query
values = x @ w_value
print(keys)
# tensor([[0., 1., 1.],
# [4., 4., 0.],
# [2., 3., 1.]])
print(querys)
# tensor([[1., 0., 2.],
# [2., 2., 2.],
# [2., 1., 3.]])
print(values)
# tensor([[1., 2., 3.],
# [2., 8., 0.],
# [2., 6., 3.]])
- Attention score 계산
기본적으로 현재의 단어가 Query이고 어떤 단어와 다른 단어의 상관을 구할 때 Query를 Key에 곱해준다
이를 Attenstion Score라고 한다
Attention Score 는 한 Sequence(문장) 내에서 특정 단어와 나머지 모든 단어와의 관련성의 정도를 나타낸다.
attn_scores = querys @ keys.T
# tensor([[ 2., 4., 4.], # attention scores from Query 1
# [ 4., 16., 12.], # attention scores from Query 2
# [ 4., 12., 10.]]) # attention scores from Query 3
- Softmax 적용
attenstion score에 다음와 같은 방식으로 softmax를 적용해 준다. -> 확률값 산출
softmax(Score/sqrt(dimention of key))
이는 키벡터의 차원이 늘어날 수록 dot product 계산시 값이 증대되는 문제를 보완하기 위해 score를 sqrt(dimention of key) 로 나눠줌
from torch.nn.functional import softmax
attn_scores_softmax = softmax(attn_scores, dim=-1)
# tensor([[6.3379e-02, 4.6831e-01, 4.6831e-01],
# [6.0337e-06, 9.8201e-01, 1.7986e-02],
# [2.9539e-04, 8.8054e-01, 1.1917e-01]])
# For readability, approximate the above as follows
attn_scores_softmax = [
[0.0, 0.5, 0.5],
[0.0, 1.0, 0.0],
[0.0, 0.9, 0.1]
]
attn_scores_softmax = torch.tensor(attn_scores_softmax)
- attention score와
weighted_values = values[:,None] * attn_scores_softmax.T[:,:,None]
# tensor([[[0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000]],
#
# [[1.0000, 4.0000, 0.0000],
# [2.0000, 8.0000, 0.0000],
# [1.8000, 7.2000, 0.0000]],
#
# [[1.0000, 3.0000, 1.5000],
# [0.0000, 0.0000, 0.0000],
# [0.2000, 0.6000, 0.3000]]])
7 . Weighted Value 합산
밸류(v) 각 단어의 벡터를 곱해준 후 모두 더한다
outputs = weighted_values.sum(dim=0)
# tensor([[2.0000, 7.0000, 1.5000], # Output 1
# [2.0000, 8.0000, 0.0000], # Output 2
# [2.0000, 7.8000, 0.3000]]) # Output 3모든 self attention 연산은 행렬곱으로 한번에 처리할 수 있다
transformer는 1에서 7까지의 연산을 수행하는 encoder layer를 6개 붙인 형태이다
encoder layer 입력벡터와 출력벡터의 크기는 동일하다
Transformer로 확장하기
-
self attention 구조
+ Dimention
+ Bias -
self attetion layer에 들어갈 수 잇는 input
+ Embedding module
+ Positional encoding
+ Truncating
+ Masking
-
다른 self attention modul
+ Multihead attention
+ Layer stacking
Multihead Attention
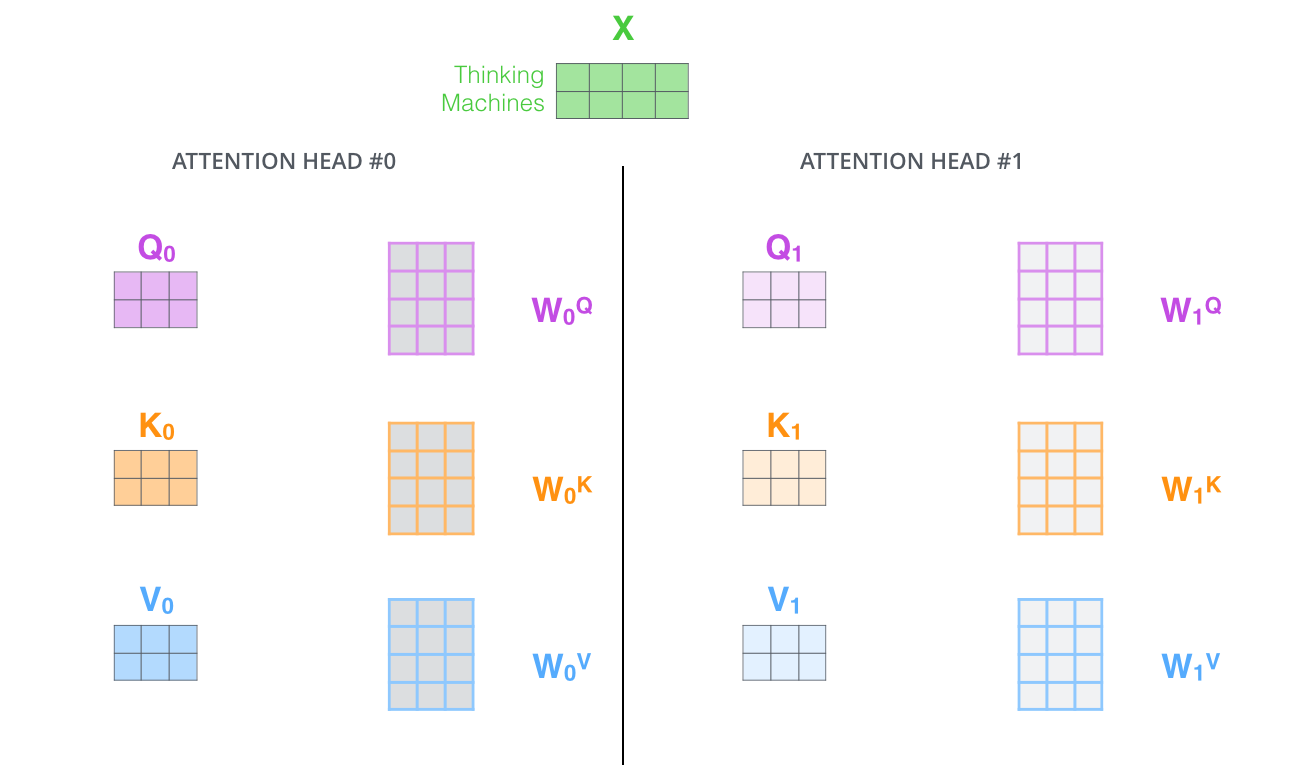
: 병렬처리되는 attention을 Multi Head Attention이라고 한다.
구체적으로는 attention layer가 여러개의 representation space를 가지게 해주는 것.
여러개의 attention layer를 병렬처리해서 얻는 이점은 문장에서 단어의 의미가 모호해서 한개의 attention으로 모호한 단어의 정보를 충분히
encoding하기 가 어려운데 multi head attenion을 사용해서 다른 관점에 단어정보를 수집해서 이를 보완할 수 있다. ->
Feed Forward Layer
multi head attention의 결과값은 모두 이어 붙여저서 또 다른 행렬과 곱해져 최초 워드임베딩과 동일한
크기를 갖는 벡터로 나온다.
multi head attentionn layer에서 나온 최초의 워드임베딩과 동일한 크기를 가지는 벡터로 나온다.
Positional Encoding
: 위치정보를 포함하고 있는 임베딩
- 각 단어의 상대적인 위치정보를 전달
- 보다 구체적으로는 각 단어 내에서 문장의 위치 정보 표시
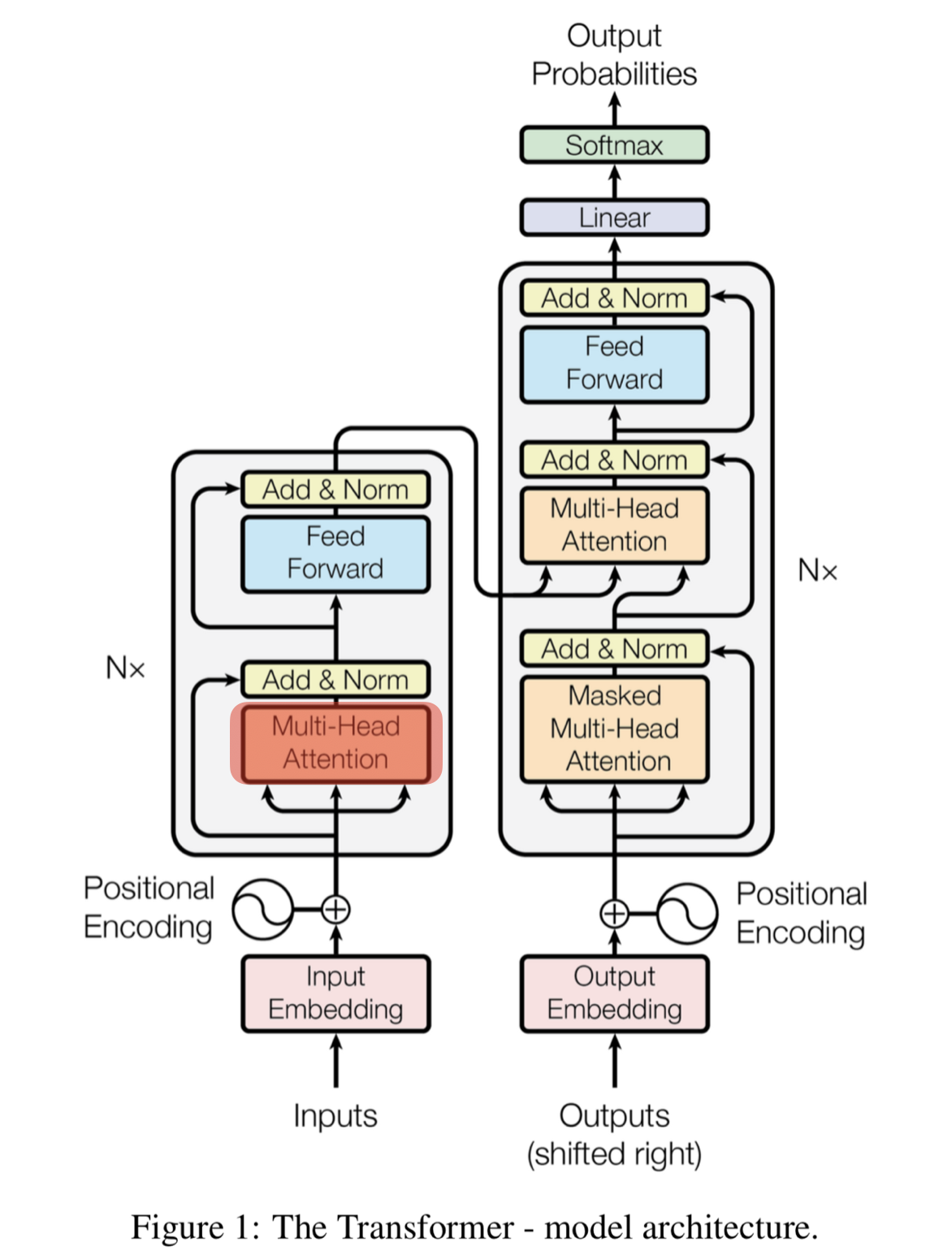
Encoder
- 입력값 임베딩
- Multi Head Attention
- 성능향상을 위한 Residual Learning
- 각 layer에서 attention과 정규화 과정을 반복함
-> resiual connection flollowd by layer normalization
역전파 과정중에 positional encoding이 손실 될 수있다.
이를 보완하기 위해 입력된 값을 다시 한번 더해준다.
Decoder
- 마지막 인코더 레이어의 출력이 모든 디코더 레이어에 입력됨
- 기본적으로 Decoder에서는 뒤에 나오는 단어를 가려주고 앞에 나오는 단어들 끼리만 연관성을 파악한다.
이러한 가려주는 것 (masking)을 안하면 학습이 잘 안된다.
이를 Masked Multihead attention이라 한다 - masked multi-head attention
- Masked Self-Attention 을 해주는 이유는 해당 위치 오른쪽에 있는 단어를 가림(mask)으로써 Attention 가중치 계산에 사용되지 않도록 하기 위함
- encoder decoder attention
- ffnn
Encoder- Decoder Atteinton Layer
목적: 원래문장 - 번역 문장 관계 파악
a. query : 디코더
b. Key, value : 인코더
c. 인코더 블록의 단어 정보와 디코더 블록의 단어 정보를 연결
Trainsforem 간단히 정리
- 입력값이 encoder에 입력됨
- 각 토큰이 positional encoding와 더해짐(단어의 위치정보 encoding)
- 행렬곱을 통해 attention vector 생성 (attention vector를 통해 토큰의 내포한 의미 전달)
- attention vector는 fully connected layer로 전송되고 이와 동일한 과정이 6번 진행됨
- 서브레이어가 기본적으로 2개(Encoder)
- Multi-head attention
- Feed Forward
- Encoder는 계산을 한번에 하며 왼쪽에서 오른쪽으로 읽어오는 과정이 없다.
- 그 최종 출력값은 decoder에 전달됨
- decoder의 서브레이어는 3
- decoder는 순차적으로 출력값 생성(왼쪽 부터 오른쪽)
- start special token으로 작업시작
- 이전 생성된 decoder의 출력값과 encoder의 출력값을 사용해 현재의 decoder 출력값 생성
- end token이라 는 최종출력이 나올때 까지 6번 반복
References
- https://www.analyticsvidhya.com/blog/2019/11/comprehensive-guide-attention-mechanism-deep-learning/
- https://jalammar.github.io/illustrated-transformer/
- https://arxiv.org/abs/1706.03762
{kind=link}
