NLG에 대한 이해
NLG(Natural Language Generation)을 학습하고 NLG의 subtask 중 하나인 Extractive Summarizationd에 대해 간단히 정리했습니다.
1. Extractive Summarization
1.1 Extractive summarization task 개요
- corpus input에서 중요한 내용을 추출해 요약문을 리턴하는 자연어 축약(Text Summarization) 과제 중 하나이다.
- Extract라는 말 그대로 input인 원문에서 중요한 문장을 골라내서 그대로 반환한다는 특징을 가진다,
- 원문에서 중요한 내용을 추출하고 새로운 문장 자체를 생성하는
Abstractive Summarization보다 나올 수 있는 결과물이 제한적이지만 상대적으로 구현이 쉽다는 장점을 가진다. - metic으로 ROUGE 라는 특수한 평가지표를 사용한다. 기계가 생성한 요약문과 사람이 미리 만들어 놓은 요약문을 비교하여 단어의 수가 얼마나 겹치는 지 확인하는 방식으로 metric의 Precision과 Recall을 구할 수 있다.
- ROGUE에서는 기본적으로 기계가 생성한 Generatied Summary와 사람이 작업한 reference summary의 순서와 출현 단어가 일치하는 정도를 바탕으로 점수를 계산한다.
1.2 대표적인 데이터셋
1.2.1 CNN/Daily mail
- 30만개의 CNN jounalist의 뉴스기사와 Daily mail을 모아놓은 데이터셋으로 Abstractive Summarization 과제와 Extractive Summmazisation 과제 모두에 사용할 수 있다.
- 기본적으로 각 article에 대한 summary와 highlight 문장으로 구성되어 있으며. highlight가 요약과제에서의 target이 된다.
ex={'id': '0054d6d30dbcad772e20b22771153a2a9cbeaf62',
'article': '(CNN) -- An American woman died aboard a cruise ship that docked at Rio de Janeiro on Tuesday, the same ship on which 86 passengers previously fell ill, according to the state-run Brazilian news agency, Agencia Brasil. The American tourist died aboard the MS Veendam, owned by cruise operator Holland America. Federal Police told Agencia Brasil that forensic doctors were investigating her death. The ship's doctors told police that the woman was elderly and suffered from diabetes and hypertension, according the agency. The other passengers came down with diarrhea prior to her death during an earlier part of the trip, the ship's doctors said. The Veendam left New York 36 days ago for a South America tour.'
'highlights': 'The elderly woman suffered from diabetes and hypertension, ship's doctors say .\nPreviously, 86 passengers had fallen ill on the ship, Agencia Brasil says .'}
1.3 SOTA models for Extractive Summarization
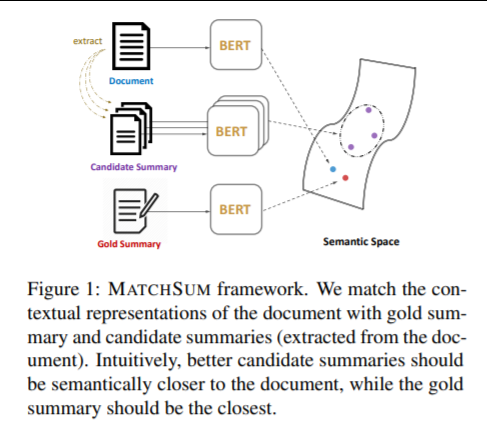
1.3.1 MATCHSUM
- framework의 전환을 통해 성능개선에 성공한 SOTA model 중 하나.
- 문장을 개별적으로 추출하고 문장 간 관계를 모델링하는 기존의 텍스트 축약 방법론 대신 task를 Sementic Text Matching 문제로 전환함.
Sementic Text Matching은 보다 더 좋은 요약문일 수록 Semantic Space에서 원문과 유사도가 높을 것이라는 가정에 기반한다는 점에서 Text Similarity 분석과 유사하다.
1.3.2 BART
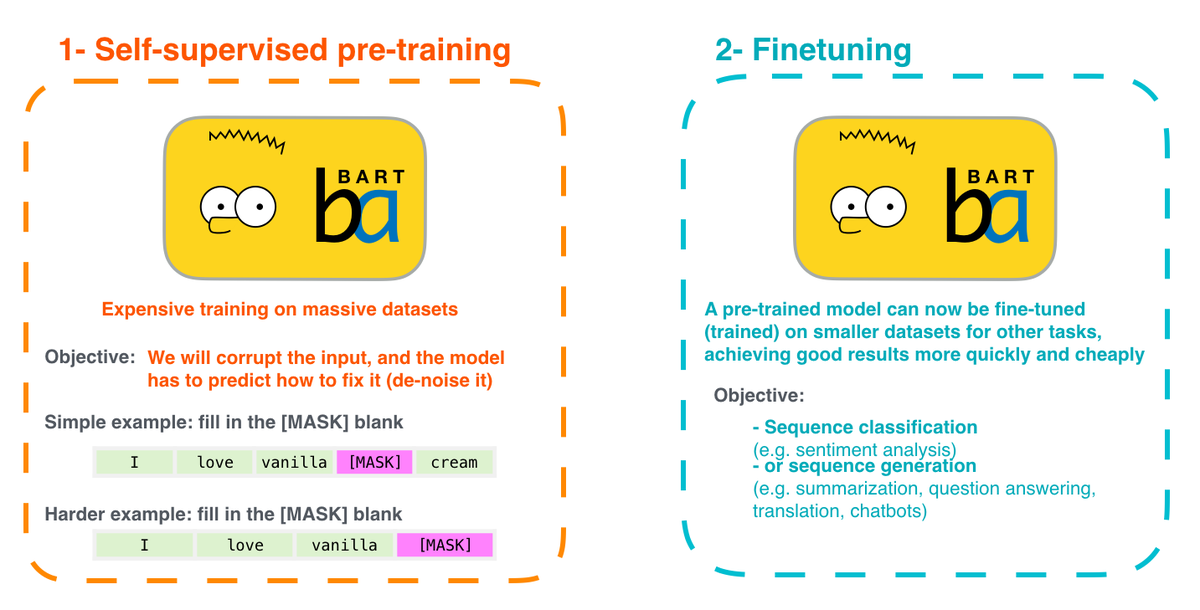
: Denoising Autoencoder method를 적용한 Seq2Seq에 기반한 pretrained model.
- BART의 핵심은 BERT에도 적용된 Masked Language Model과 Denoising Autoencoder를 통한 텍스트 재생성 기술의 결합이다.
AutoEncoder
- AutoEncoder는 PCA를 비선형모델로 일반화한 버전으로 feature extraction의 역할을 한다.
- Denosing AutoEncoder는 추천시스템과 영상처리에도 사용되는 범용성 높은 feature extraction 방식으로 데이터에 의도적으로 noise를 주고 원데이터를 재생성하는 방식으로 모델을 학습시킨다.
- BART에서는 Denoising Autoencode를 활용해 토큰을 마스킹하고 학습시키는 방식을 쓰기에 텍스트를 생성하는 NLG task에서 보다 높은 성능을 보인다.
- auto regressive decoder를 사용해 문서의 sequence 생성작업에서 fine tuning이 가능하다.

2. References

Python, R User :)




좋은 글 감사합니다