NLP subtask
NLP subtask에 대한 정리
: 주요 NLP task인 Word Embedding과 Text Classfication에 대해 간단히 정리했습니다.
1.Word Embedding
1.1 Word Embedding에서 고려하는 task
Word Embedding은 단어를 저차원의 실수벡터로 dense mapping하는 word representation 방식의 하나이다.
Embedding 자체는 토큰을 고정된 길이의 벡터로 표현하는 것을 뜻한다.
단어의 구문(Syntax)와 의미(Semantics)를 실수벡터의 형태로 표현하는 것이 그 목적이다.

1.1.1 차원의 저주
단어를 실수벡터의 형태로 dense mapping하는 이유는 차원의 저주를 피하기 위함이다.
문서의 모든 단어를 One Hot encoding으로 표현할 경우 feature가 기하급수적으로 많아진 희소행렬이 생성되고 이 경우 연산비용이 증가하는 문제점이 발생한다.
이를 피하기 위해 Word Embedding을 통해 단어를 저차원 벡터에 고정시켜 나타내게 된다.
1.1.2 Distribution Hypothesis
Distribution Hypothesis는 비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다는 가설이다.
Word embedding은 이 분포 가설에 기반하여 주변 단어 분포를 기준으로 타겟이 되는 단어의 벡터 표현을 결정한다.
따라서 Word Embedding을 통해 생성된 두 단어 벡터의 거리가 가까울 수록 원문에서 두 단어가 유사한 의미와 용법을 가졌다고 볼 수 있다.
1.1.3 Predictive Method
Word Embedding은 기본적으로 단어의 예측을 학습하는 것으로 이루어진다.
1.2 대표적인 데이터셋
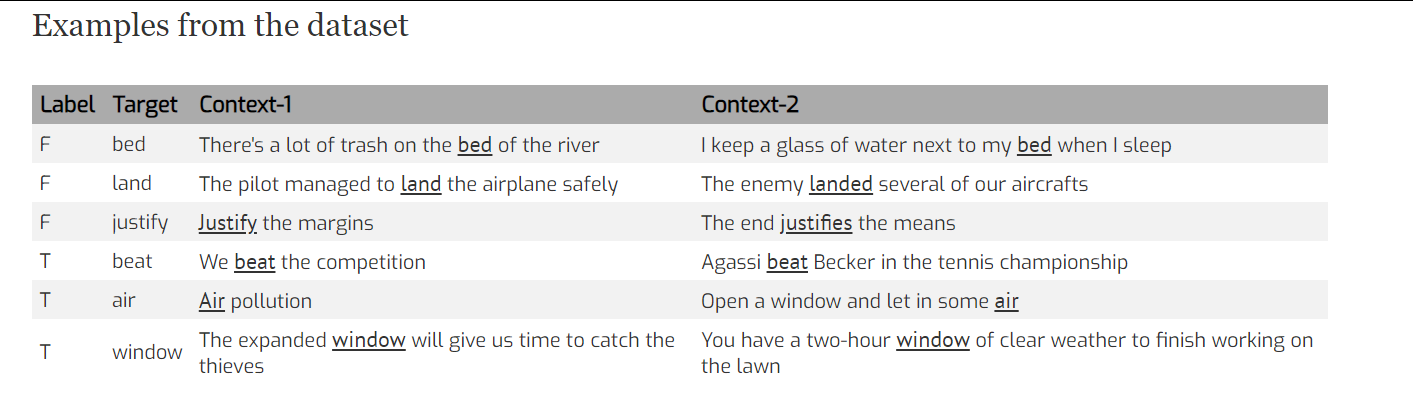
Words in Context
Word in Context는 문맥에 따른 단어의 용법을 모아놓은 데이터 셋이다.
과거의 Word Embedding 기법들이 문맥에 따라 달라지는 단어의 의미를 구분하지 못한다는 문제점을 보완하기 위해 만들어졌다.
Word in Context을 통해 문맥정보를 학습한 임베딩을 생성할 수 있다.
데이터셋은 타겟단어 , 타겟이 되는 타겟단어의 Context 문장 2개와 해당 문장이 문맥상 같은 의미로 쓰여졌는지에 대한 label로 구성되어 있다.
1.3 Contextual Embedding(SOTA Technique)
Word Embedding은 기본적으로 모델링이 아니라 NLP task의 input을 만드는 작업이기 때문에 BERT, ELMO, GPT-1와 같은 SOTA 모델에서 사용하는 Embedding 방식인 Contextual Embedding에 대해 기술하고자 한다.
과거의 Word Embedding 대표적인 문제점은 하나의 단어당 하나의 벡터 값 만이 매핑된다는 것이다. 따라서 단어의 문맥에 따라 달라지는 의미를 고려하기 어려워지고 성능에 부적인 영향을 주게 된다.
이러한 문제점을 보완하기 위해 Deep contextualized word representations(ELMO)에서 Contextual Embedding이 제시되었다.
1.3.1 biLM(bidirectional Language Model) as function
Contextual Embedding과 기존 임베딩의 차이점은 각 단어마다 고정된 크기의 벡터를 사용한 것이 아니라 pretrained model 자체를 일종의 함수으로 기능하게끔 하여 문맥정보를 학습에 반영한다는 것이다.
ELMo(Embedding from Language Model)는 여기서 단순한 Language Model이 아니라 일종의 함수이며 문장에 따라 같은 단어라도 다른 임베딩(단어 벡터)을 출력할 수 있다.
여기서 biLM은 단순히 forword LSTM(앞의 단어들로 뒤에 나올 단어를 예측)과 backword LSTM(뒤의 단어들로 앞의 단어를 예픅)을 합친 양방향 모델을 말하며 ELmo의 학습에 사용된다.
2. Text Classification
2.1 Text Classification의 주요 task
Text Classification은 문서의 내용을 바탕으로 특징을 추출해서 특정한 카테고리에 분류하는 것을 그 목적으로 한다.
2.2 대표적인 데이터셋
2.2.1 IMDB Movie Review
IMDB에 게시된 영화 리뷰와 Positive/Negative label로 구성된 데이터셋이며 주로 감성분석과 추천시스템 구현에 사용된다.
2.3 BERT(SOTA Technique)
BERT는 구글에서 개발한 신경망 구조이며 Text Classification 뿐 만 아니라 질의응답, 기계번역 , 문서요약과 같은 다양한 task에 적용할 수 있는 대표적인 SOTA Model이다.
2.3.1 Transformer
Transformer는 Encoder Decoder 구조를 가지는 딥러닝 모델이다.
기본적으로 여러개의 Encoder Decoder Layer가 존재하기 때문에 순차적으로 단어정보를 입력받지 않아 연산에서의 부담이 상대적으로 적은 편이다.
Encoder 내부에서는 self attention 기법으로 한 문장에서 한 단어가 다른 단어와 어떤 관계를 갖고 있는지 수치화한다.
문장의 Context를 학습하기 위해 Positional Encoding이라는 특수한 Input을 사용한다.
BERT(Bidirectional Encoder Representations from Transformers)는 양방향 입력을 받는 Encoder를 여러개 쌓아올린 구조로 이루어져 있다.
BERT에서는 일부 단어를 마스킹하고 해당 단어를 예측하거나(). 문장단위로 예측을 수행()하는 기법()
단어 토큰을 보다 세분화하는 WordPiece 기법을 사용한다.
2.3.2 fine tuning
Transformer와 함께 BERT의 핵심 컨셉중 하나로 기존의 학습된 모델을 기반으로 레이어를 새로운 task에 맞게 변형하고 이미 학습된 모델가중치를 업데이트하거나 모델의 파라미터를 재조정하는 것을 뜻한다.
References





좋은글 감사합니다